



 本文详细解析了Java NIO中ByteBuffer的内部机制,包括HeapByteBuffer与DirectByteBuffer的区别,四个关键指针的作用,以及各种操作方法如flip、rewind、clear的使用场景。同时,文章还介绍了内存分配、子Buffer操作、数据压缩和类型转换等内容。
本文详细解析了Java NIO中ByteBuffer的内部机制,包括HeapByteBuffer与DirectByteBuffer的区别,四个关键指针的作用,以及各种操作方法如flip、rewind、clear的使用场景。同时,文章还介绍了内存分配、子Buffer操作、数据压缩和类型转换等内容。
该类继承Buffer类,Buffer类的继承关系图如下:
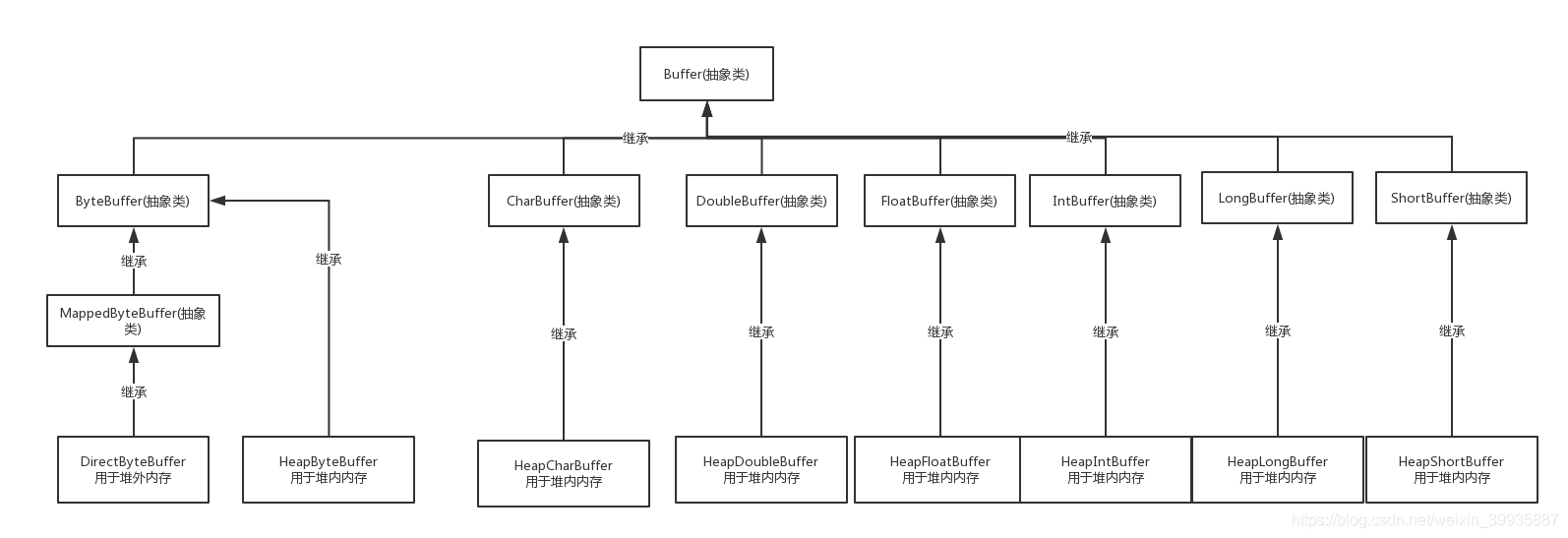
ByteBuffer类
从上面的图可以看出,该类有三个子类,MappedByteBuffer、HeapByteBuffer、DirectByteBuffer,其中HeapByteBuffer和DirectByteBuffer分别用于堆上内存和非堆上内存。
DirectByteBuffer不是分配在堆上的,它不被GC直接管理(但Direct Buffer的JAVA对象是归GC管理的,只要GC回收了它的JAVA对象,操作系统才会释放Direct Buffer所申请的空间),它似乎给人感觉是“内核缓冲区(buffer in kernel)”。
HeapByteBuffer则是分配在堆上的,或者我们可以简单理解为Heap Buffer就是byte[]数组的一种封装形式,查看JAVA源代码实现,HeapByteBuffer也的确是这样。 说白了就是HeapByteBuffer是在JVM堆内存中分配会被JVM管理回收,但是DirectByteBuffer是直接由系统内存进行分配,不被JVM管理。通过上面的区别看到:
1、创建和释放DirectByteBuffer的代价比HeapByteBuffer的要高,因为JVM堆中分配和释放内存肯定比系统分配和创建内存高效
2、因为平时的read/write,都会在I/O设备与应用程序空间之间经历一个“内核缓冲区”。 DirectByteBuffer就好比是“内核缓冲区”上的缓存,不直接受GC管理;而Heap Buffer就仅仅是byte[]字节数组的包装形式。因此把一个Direct Buffer写入一个Channel的速度要比把一个HeapByteBuffer写入一个Channel的速度要快。
所以这两个类操作起来各有好处,要视情况而定,一般如果是一个ByteBuffer经常被重用的话,就可以使用DirectByteBuffer对象。如果是需要经常释放和分配的地方用HeapByteBuffer对象。
堆外内存
ByteBuffer类中通过allocateDirect(int capacity)函数类创建一个内存分配在非堆上的类对象,代码如下:
/**
* Allocates a new direct byte buffer.
*
* <p> The new buffer's position will be zero, its limit will be its
* capacity, its mark will be undefined, and each of its elements will be
* initialized to zero. Whether or not it has a
* {@link #hasArray backing array} is unspecified.
*
* @param capacity
* The new buffer's capacity, in bytes
*
* @return The new byte buffer
*
* @throws IllegalArgumentException
* If the <tt>capacity</tt> is a negative integer
*/
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}DirectByteBuffer类的构造函数代码如下:
// Primary constructor
//
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}上面的代码中通过Unsafe类来分配堆外内存,Unsafe类详解
堆内内存
ByteBuffer类中通过allocate(int capacity)函数类创建一个内存分配在堆上的类对象,代码如下:
/**
* Allocates a new byte buffer.
*
* <p> The new buffer's position will be zero, its limit will be its
* capacity, its mark will be undefined, and each of its elements will be
* initialized to zero. It will have a {@link #array backing array},
* and its {@link #arrayOffset array offset} will be zero.
*
* @param capacity
* The new buffer's capacity, in bytes
*
* @return The new byte buffer
*
* @throws IllegalArgumentException
* If the <tt>capacity</tt> is a negative integer
*/
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}可以看出,这里面会返回一个HeapByteBuffer类对象,我们进入到该类的构造函数中,代码如下:
// For speed these fields are actually declared in X-Buffer;
// these declarations are here as documentation
/*
protected final byte[] hb;
protected final int offset;
*/
HeapByteBuffer(int cap, int lim) { // package-private
super(-1, 0, lim, cap, new byte[cap], 0);
/*
hb = new byte[cap];
offset = 0;
*/
}会调用父类的构造函数,也就是ByteBuffer,ByteBuffer类的构造函数如下:
// Creates a new buffer with the given mark, position, limit, capacity,
// backing array, and array offset
//
ByteBuffer(int mark, int pos, int lim, int cap, // package-private
byte[] hb, int offset)
{
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}可以看到HeapByteBuffer构造函数中创建的byte[]变量赋值给了ByteBuffer类中的hb变量。这种情况下对ByteBuffer类的读取和写入操作都最终反映到了hb变量上,比如array()函数,代码如下:
/**
* Returns the byte array that backs this
* buffer <i>(optional operation)</i>.
*
* <p> Modifications to this buffer's content will cause the returned
* array's content to be modified, and vice versa.
*
* <p> Invoke the {@link #hasArray hasArray} method before invoking this
* method in order to ensure that this buffer has an accessible backing
* array. </p>
*
* @return The array that backs this buffer
*
* @throws ReadOnlyBufferException
* If this buffer is backed by an array but is read-only
*
* @throws UnsupportedOperationException
* If this buffer is not backed by an accessible array
*/
public final byte[] array() {
if (hb == null)
throw new UnsupportedOperationException();
if (isReadOnly)
throw new ReadOnlyBufferException();
return hb;
}这里需要注意,如果是非堆内存,那么hb这个变量为null,所以非堆内存的ByteBuffer类对象是不能使用array()函数来读取内存中的内容的,该函数只能用于堆内存的情况,非堆内存的ByteBuffer类对象可以使用get(byte[] dst, int offset, int length)函数来读取内存中的内容。
下面是详细的转载内容,原文地址在https://blog.youkuaiyun.com/shuaiawp/article/details/51915983
ByteBuffer的四大类操作方法

这张图中我们可以看到在操作ByteBuffer的时候,有四个指针来进行操作:
capacity指针:这个指针是在调用allocate方法分配完内存之后直接指向字节数组的末尾,不会在发生改变的,除非再次调用allocate方法重新分配内存大小。
limit指针:这个指针在初始化分配内存的时候和capacity指针一样,指向数组的末尾,但是这个指针是会发生改变的,有一个limit方法可以设置他的值。同时像flip,clear等方法也会改变他的值。它更像是数组的一个有效数据的范围上限指针。limit<=capacity
position指针:这个指针是指向当前有效数据的起始位置,在初始化分配内存的时候指向数组的起始位置,后续可以通过position方法进行设置,同时他在很多地方都会发生改变,特别是在读写数据方法get,put的时候,每次读写一次,指针就加一,直到遇到了limit指针,position<=limit;所以可以看到整个数组中只有position-limit之间的数据是有效的,是可以进行读写操作的。
mark指针:这个指针在初始化的时候就是-1,起到一个数组指针不合法的哨兵作用,只要不调用mark方法,他的值一直是-1,最主要的是对position进行标记作用,有时候有一种需求就是想临时保存一下当前读写指针position的值,因为position随时都会发生改变,但是有时候还想再回来,那么mark指针就是这个作用,用来标记position的前一个状态,对应的方法是mark,还原方法是reset,这个指针只有在mark方法,clear,flip等方法会发生变化。mark<=position
通过上面的四个指针分析之后,发现有了mark和limit指针,我们不会担心数组越界的问题了,有了position指针我们能够很简单的操作数组数据,效率也高。
下面通过一个代码来验证这些方法的具体作用:
1、首先看一下打印ByteBuffer中四个指针的方法,这里ByteBuffer都提供了position,limit,capacity三个指针的访问方法,但是mark指针没有,所以这里需要用反射去操作,注意的是,我们allocate出来的是HeapByteBuffer对象,但是这四个指针都是定义在Buffer类中的,HeapByteBuffer->ByteBuffer->Buffer

下面来看一个这些方法的操作案例:

1、allocate方法
这里首先调用allocate方法分配10个大小的内存,然后从起始位置开始写入5个数据,再次调用flip方法准备读状态,然后在从起始位置读取四个数据,运行结果如下:

2、flip方法
这里看到了,在put完数据之后,position就变成了5了,所以需要调用flip方法来改变状态,才能正确的读到刚刚写入的数据,假设这里不调用flip方法:

看到了,读取出来的数据都是脏数据0,而且看到position变成了5+4=9了。所以在每次读写之后一定要记得改变状态,改变状态有flip,rewind,clear这三种方法,但是flip方法是最合理的。因为他把有效数据的末尾指针position赋值给了limit指针。
看一下flip源码:

3、put方法
再来看一下put方法:

使用直接索引的方式写入字节数组,看看nextPutIndex方法:

看到了position++了,所以所有put方法都会改变position的值。
同样的get方法是同理,这里不再解释了。
4、clear方法
后续的代码,我们使用了put方法直接写入一个字节数组,但是在之前我们使用了clear方法来设置状态,下面来看看clear源码:

这时候就相当于到了起始状态了:来看看put方法源码:

其实内部实现很简单,就是把源字节数组copy到hb中,然后position=position+length即可。
5、rewind方法
然后调用rewind方法设置状态,准备后面的读取数据,看一下rewind方法源码:

这里直接把position清零,这样才能正确的读取到刚刚的那个写入的数据,但是这个方法有一个问题,也就是和flip不同的地方,我们下面来改一下代码:

这里看到,我们上面写入了5个数据,但是调用rewind方法之后,再去读6个数据,这时候肯定不会出现错误的,但是会读取脏数据:

因为limit=capacity=10,但是flip方法就会把limit设置成position,不会读出脏数据的,所以flip和rewind方法的区别。
6、position和limit方法
这里我们还可以手动去设置position和limit值,做到我们想要的想过,比如这里可以模仿clear方法:

看到了,这里手动的将状态设置初始状态,打印结果:

7、mark和reset方法
下面再来看一下mark和reset方法的使用效果:

首先调用mark把mark设置position=0,然后在去操作position值,最后在调用reset进行复位,position又等于0了,看一下运行结果:

8、remaining和hasRemaining方法
再来看一下ByteBuffer容量剩余的方法remaining和hasRemaining:

hasRemaining方法就是判断ByteBuffer有没有到上限,即position是否大于limit,看看方法的源码:

同时还有一个remaining方法获取当前剩余的范围值,就是limit-position的值,看看源码:

看看上面的运行结果:

好了,上面就看到了所有的关于ByteBuffer四个指针的操作方法,下面来总结一下:
1、四个指针:mark,position,limit,capacity,他们之间的关系:mark<=position<=limit<=capacity
2、allocate分配方法可以改变capacity的值
3、flip,limit,clear,allocate方法可以改变limit的值
4、put,get,flip,clear,rewind,position,reset等读写数据的方法都会改变position的值
5、mark,flip,clear,rewind等方法会改变mark的值
6、capacity,limit,position是可以通过方法获取到值的,其中limit,position方法可以直接改变limit和position的值
7、hasRemaining和remaining方法是用来判断当前ByteBuffer中还有多少空间可以使用,一般先判断hasRemaining是否有空,如果没有空间的话,在把capacity设置成limit的,使用limit(buff.capacity)方法设置即可。如果在超出的话,就需要重新分配空间了。
第二类:内存分配功能解析
这里主要来介绍一下ByteBuffer的内存分配内容,在之前其实已经介绍了关于allocate和allocateDirect方法的区别了,其实还有一个重要方法就是wrap方法,下面先来看一下图简介:

下面来看一下代码:

1、allocate和allocateDirect方法
这里首先查看JVM内存大小,然后在使用allocate方法分配一个大内存,在查看JVM内存大小,然后在使用allocateDirect方法分配一个大内存,在查看JVM内存大小,看看打印结果:

看到了,在调用了allocate方法之后,JVM内存发生了变化,但是allocateDirect方法没有,还是之前allocate方法执行完之后的内存大小。
2、wrap方法
然后在看看wrap方法进行内存分配,同时进行写数据,首先来看一下wrap的源码:

这里看到了,直接构造一个HeapByteBuffer对象返回了,传入的array就直接赋值给了全局数组hb了,看看构造方法:

构造方法中,前四个参数就是mark,position,limit,capacity的值了,从这里看到,position就是wrap中需要传递字节数组的有效数据的开始索引,limit就是有效数据的上限,capacity就是整个数组的大小了,这样看来其实是很合理的,我们调用wrap方法之后看结果:

看到了,这里的position和limit值就是数组起始位置和结束位置。同时修改了字节数组的第11个值,然后ByteBuffer内容也被影响进行了修改了。
所以看到wrap方法有这几个特点:
1、他的功相当于是allocate+put方法的结合,同时分配内存,也写入数据了。
2、写入的字节数据和ByteBuffer内容在堆中是一份数据的,相互影响的,所以这个方法在使用的时候需要特别小心,注意数据的有效性,同时这个方法因为是直接操作堆内存的,所以返回的就是HeapByteBuffer对象了。
3、通过传递的字节数组的offset和len值,来设置mark,position,limit,capacity的大小了
第三类:子Buffer操作
ByteBuffer中操作子Buffer的方法大致是四个:slice,duplicate,array,get;下面来看一下图解吧:

看到上面的图之后,发现这四个方法其实比较起来就三个方面:拷贝的内容范围,会影响源内容,执行完之后会影响源内容的position和limit值;
1、slice方法
下面通过代码来看看,首先看一下slice方法:

slice方法其实就是copy一个原来的ByteBuffer的position-limit之间的有效数据,所以如果你想拷贝那一段数据,需要提前设置position和limit值,同时看看slice内容和源内容是否相互影响,看一下运行结果:

再来看一下slice源码:

看到源码就知道了,和源ByteBuffer共用一个hb,只是改变了position和limit,capacity的值,内容肯定是相互影响的。但是没有影响到了源ByteBuffer的position和limit值。
2、duplicate方法
再来看一下duplicate方法,这个方法是直接拷贝源ByteBuffer的一个副本,不仅把所有的内容拷贝过来,而且还把mark,position,limit,capacity也全部拷贝过来了:

看一下运行结果:

在来看一下duplicate的源码:

这个构造方法直接把hb赋值过去,同时设置源ByteBuffer的所有标记指针值。所以内容肯定也是相互影响的。但是没有影响到了源ByteBuffer的position和limit值。
3、array方法
再来看一下array方法,这个方法也是拷贝所有的内容到一个字节数组中:

运行结果看看:

下面来看看源码:

这个方法很简单,直接返回了ByteBuffer全局的字节数组hb,那么内容肯定是相互影响的,但是没有影响到了源ByteBuffer的position和limit值。
4、get方法
最后再来看一个get方法,他是拷贝源ByteBuffer的position到limit之间的有效数据内容的:

看看运行结果:

查看源码:

源码中可以看到,内部使用了get方法读取一个字节,然后存放到新的字节数组中,那么这样看来就不会内容之间相互影响了,但是因为调用了get方法,所以position值会递增的。
看完了上面的四个方法,下面就来总结一下吧:
1》、slice方法获取的是源ByteBuffer的position-limit之间的内容,和源内容相互影响,源内容的position和limit不受影响
2》、duplicate方法获取的是源ByteBuffer所有的内容,包括源ByteBuffer的mark,position,limit,capacity值,和源内容相互影响,源内容的position和limit不受影响
3》、array方法获取的是源ByteBuffer的所有内容,只是存放到一个字节数组中,和源内容相互影响,源position和limit不受影响
4》、get方法获取的是源ByteBuffer的position-limit之间的内容,存放到目标字节数组中,和源内容不影响,源position会发生变化等于limit,limit不受影响
第四类:数据压缩和其他基本类型之间的转化
这里主要来看看ByteBuffer中的数据压缩,以及和其他基本类型之间的转化内容了,先来看一下图解:

下面依次来看看具体内容:
1、compact方法
首先来看一下压缩方法compact:

这里首先初始化ByteBuffer内容为0-10,然后设置position为3,那么压缩前,0-2这三个位置就是无效数据了,那么就把从3开始的,长度是10-3=7的数据拷贝到位置是0-7中。同时position=limit-position;为了方便看结果,这里调用clear方法,回到初始状态,看看结果:

看到了结果就会明白了,这里个把0-2的位置给顶替了,再来看看他的源码:

通过源码可以看到:直接拷贝内容,然后在设置position和limit的值。
2、getInt和asIntBuffer,order方法
再来看一下ByteBuffer中和其他类型之间的转化
说到其他类型的转化之前,必须先说一下字节排序,我们知道所有的内容最后存放到内存中都是二进制,那么在学习计算机组成原理的时候都知道,内存中的数据有高序和低序之分的,那么不同的排序,输出的结果也是不同的,同样ByteBuffer中的字节也是有排序的,简称大端和小端排序,Java中默认的是大端排序,如果想设置小端排序的话,可以通过order方法进行设置:

有三个选项,前两个是枚举,大端排序和小端排序,后一个是一个方法,这个方法其实就是底层实现的,根据本机系统支持的排序,因为Java默认是大端排序的,所以有时候我们在涉及到底层开发的时候,需要根据本机系统来进行操作,那么这时候这个方法就非常有效了,比如后面说到的openGL就经常用到这个方法。
设置完了字节排序之后,我们才能开始转化其他类型,因为其他类型都是由多个字节组成的,比如int类型就4个字节,可以通过getInt方法来获取一个int值,但是需要注意的是ByteBuffer的字节有效性,每次取数据都是在position到limit之间的数据,然后通过取4个字节以及字节排序来进行int值的转化,加入limit-position % 4 !=0的话,那么在取最后一个int值会发生错误,因为字节个数不足4了,这个需要做一次判断的,下面来看看代码:

首先我们打印一下JVM默认的字节排序,然后在设置本机系统的字节排序,运行结果:

这里看到了,默认是大端排序的,然后通过打印结果是:07090809来看应该是低端排序了,因为本来是:
03040506 07080907 0809
因为调用了两次getInt,所以是中间的内容,但是看到了是倒序的,加入我们没有设置字节排序,使用默认的排序:

这下就看到了,nativeOrder是小端排序的,看到内容也是。
这里同时也看到了,每次调用getInt方法,position都会递增的,下面来看一下源码:

nextGetIndex方法在之前分析了,内部是position做加法操作的。
最后再来看看如果想改ByteBuffer中整型内容值该怎么办?有一个asIntBuffer方法:

调用了asIntBuffer对象返回的是IntBuffer对象,其他类型的都有对应的对象,然后我们打印结果,在修改IntBuffer中的值,在打印ByteBuffer内容,看看结果:

看到了,修改了前四个字节的内容,正好是IntBuffer的第一个数据,而IntBuffer的limit=2,这个就是通过ByteBuffer的remaining的值除以4得到的,这里是(limit-position=10)/4=2,可以看看源码:

到这里,我们就看完了,如何把ByteBuffer中字节转化成int类型,同时修改int值来同步到ByteBuffer中,当然其他基本类型操作方法类似的,最后再来看一个比较安全有用的方法:asReadOnlyBuffer,这个方法主要是返回一个只读的ByteBuffer的副本对象,如果我们调用了这个对象的put方法:

运行就会出错:

所以这个方法对于,我们不想给源ByteBuffer的数据造成影响,但是又想读取数据的话,就这个方法了。
四、知识总结
上面就介绍完了整个ByteBuffer的所有内容了,首先我们知道他是一个操作字节数据的高效类。
1、ByteBuffer的操作原理
ByteBuffer有两个子类HeapByteBuffer和DirectByteBuffer,这两个类的区别就在于前一个类是基于JVM堆内存的,后一个是基于系统内存的,他们通过allocate和allocateDirect方法获取。
2、四个“指针”
mark,position,limit,capacity这四个指针来操作数据,mark最不常用,默认是-1,就是为了存储上一次position的值,而position是最常用的,在进行数据的读写,状态改变都会设置这个值,就是表示当前有效数据的起始位置,limit的值是当前有效数据的末尾位置,可以通过limit方法直接设置值,capacity值是整个内存的容量,一般不会改变,只有在内存不足的的时候再次分配会被重新复制。同时position和limit可以通过对应的方法随意设置指定的值,而position和limit以及capacity这三个可以有对应的方法来访问他们的值。最重要的是:position到limit中间的数据被认为是有效数据。
3、操作内存分配方法
这里主要介绍了allocate和allocateDirect方法的区别,以及wrap方法和前面的两个方法的区别,wrap方法相当于是allocate+put方法结合体,需要注意的是wrap方法传递进入的字节数组和ByteBuffer内容是相互影响的。
4、操作子Buffer的方法
这里主要介绍了slice方法,duplicate方法,array方法,get方法,这四个方法从三个方面:拷贝源ByteBuffer内容,是否影响源ByteBuffer内容,是否会改变源ByteBuffer的postion和limit值,来作比较的。
5、压缩数据以及和其他基本类型的转化
这里主要介绍了ByteBuffer中的compact方法的作用,然后介绍了ByteBuffer中的字节排序,以及如何转化成int类型值,修改int类型值。
最后再来看一张表格,来比较这些方法的区别:
首先是操作四个指针的方法:

然后是操作内容的一些方法比较:

项目下载:http://download.youkuaiyun.com/detail/jiangwei0910410003/9575398
五、总结
介绍了ByteBuffer内容之后,我们就可以进行后续的操作了,比如在处理MediaCodec中编码视频流的时候,用到了ByteBuffer类型,在处理OpenGL的时候,需要用到ByteBuffer类型,当然介绍完了ByteBuffer类型之后,其他基本类型大致相同也就可以大致了解就可以了。

















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









