





 本文介绍了Python的线程和进程的区别,详细讲解了threading模块的使用,包括通过可调用对象创建线程、派生Thread子类以及Lock同步锁的使用,同时探讨了死锁和重入锁的概念。强调在Python中,多线程主要用于I/O密集型程序,因为全局解释器锁(GIL)限制了多核CPU的并行计算能力。
本文介绍了Python的线程和进程的区别,详细讲解了threading模块的使用,包括通过可调用对象创建线程、派生Thread子类以及Lock同步锁的使用,同时探讨了死锁和重入锁的概念。强调在Python中,多线程主要用于I/O密集型程序,因为全局解释器锁(GIL)限制了多核CPU的并行计算能力。
讲实现多线程之前,先了解什么是进程、什么是线程、以及两者的区别?
一、进程与线程
进程:是资源分配的最小单位,也可以指程序从开始到结束的一个过程。
线程:是操作系统进行运算调度的最小单位,一个进程至少有一个线程。
区别:
所有线程共享创建它的进程地址空间,而进程之间的地址空间是独立的。
所有线程共享创建它的进程数据,而进程之间的数据不能互相访问。
线程之间可以相互通讯、互相操作,而进程之间不可以。
二、全局解释器锁(GIL)
Python的多线程,只有用于I/O密集型程序时效率才会有明显的提高。
原因如下:
Python代码的执行是由Python虚拟机进行控制。它在主循环中同时只能有一个控制线程在执行,意思就是Python解释器中可以运行多个线程,但是在执行的只有一个线程,其他的处于等待状态。
这些线程执行是有全局解释器锁(GIL)控制,它来保证同时只有一个线程在运行。在多线程运行环境中,Python虚拟机执行方式如下:
设置GIL
切换进线程
执行下面操作之一:1.运行指定数量的字节码指令;2.线程主动让出控制权
切换出线程(线程处于睡眠状态)
解锁GIL
进入1步骤(设置GIL)
三、Python 的 threading 模块
Python 常用的多线程模块有threading 和 Queue,在这里我们将 threading 模块。
threading 模块的Thread 类是主要的执行对象。使用Thread 类,可以有很多方法来创建线程。最常用的有下面三种:
创建Thread 的实例,传给它一个可调用对象(函数或者类的实例方法)。
派生Thread 的子类,并创建子类的实例。
3.1 可调用对象(函数,类的实例方法)使用多线程
步骤如下:

示例:创建Thread实例,传递给他一个类的实例方法
from threading import Threadfrom time import sleep, ctimeclass MyClass(object):def func(self,name,sec):print('---开始---', name, '时间', ctime())
sleep(sec)print('***结束***', name, '时间', ctime())if __name__=="__main__": # 创建 Thread 实例
t1 = Thread(target=MyClass().func, args=(1, 1))
t2 = Thread(target=MyClass().func, args=(2, 2))# 启动线程运行
t1.start()
t2.start()# 等待所有线程执行完毕
t1.join() # join() 等待线程终止,要不然一直挂起
t2.join()运行结果:
---开始--- 一 时间 Fri Nov 29 11:34:31 2019
---开始--- 二 时间 Fri Nov 29 11:34:31 2019
***结束*** 一 时间 Fri Nov 29 11:34:32 2019
***结束*** 二 时间 Fri Nov 29 11:34:33 2019
程序总共运行两秒,如果程序按照线性运行需要3秒,节约1秒钟。
Thread 实例化时需要接收 target,args(kwargs)两个参数。
target 用于接收需要使用多线程调用的对象。
args 或 kwargs 用于接收调用对象的需要用到的参数,args接收tuple,kwargs接收dict。
start() 是方法用来启动线程的执行。
join() 方法是一种自旋锁,它用来等待线程终止。也可以提供超时的时间,当线程运行达到超时时间后结束线程,如join(500),500毫秒后结束线程运行。
注意:如果当你的主线程还有其他事情要做,而不是等待这些线程完成,就可以不调用join()。join()方法只有在你需要等待线程完成然后在做其他事情的时候才是有用的。
3.2 派生Thread 的子类,并创建子类的实例。
我们可以通过继承Thread类,派生出一个子类,使用子类来创建多线程。
示例:派生Thread 的子类,传递给他一个可调用对象
from threading import Threadfrom time import sleep, ctime# 创建 Thread 的子类class MyThread(Thread):def __init__(self, func, args):'''
:param func: 可调用的对象
:param args: 可调用对象的参数
'''
Thread.__init__(self) # 不要忘记调用Thread的初始化方法self.func = funcself.args = argsdef run(self):self.func(*self.args)def func(name, sec):print('---开始---', name, '时间', ctime())
sleep(sec)print('***结束***', name, '时间', ctime())if __name__ == '__main__': # 创建 Thread 实例
t1 = MyThread(func, (1, 1))
t2 = MyThread(func, (2, 2))# 启动线程运行
t1.start()
t2.start()# 等待所有线程执行完毕
t1.join()
t2.join()注意:不要忘记在子类中初始化父类的方法Thread.__init__(self) 。需要重构 run() 方法来执行多线程的程序。
四、Lock 同步锁(原语锁)
2.1 同步锁的使用
我们一般使用获得锁(加锁)和释放锁(解锁)函数来控制锁的两种状态“锁定”和“未锁定”。一般只要在公共操作前加上加锁和解锁的操作即可。
示例:加锁 与 解锁
import threading# 创建一个锁对象
lock = threading.Lock()# 获得锁,加锁
lock.acquire()....# 释放锁,解锁
lock.release()当我们通过 lock.acquire() 获得锁后线程程将一直执行不会中断,直到该线程 lock.release( )释放锁后线程才有可能被释放(注意:锁被释放后线程不一定会释放)。
示例:锁的运用
import timeimport threading# 生成一个锁对象
lock = threading.Lock()def func():global num # 全局变量# lock.acquire() # 获得锁,加锁
num1 = num
time.sleep(0.1)
num = num1 - 1# lock.release() # 释放锁,解锁
time.sleep(2)
num = 100
l = []for i in range(100): # 开启100个线程
t = threading.Thread(target=func, args=())
t.start()
l.append(t)# 等待线程运行结束for i in l:
i.join()print(num)注意:上面代码先将lock.acquire()和lock.release()行注释掉表示不使用锁,取消lock.acquire()和lock.release()行的注释表示使用锁。
运行结果:
不使用锁程序运行输出为 99;
使用锁程序运行结果为0
为什么会有差异?这就是有锁和无锁的差别。
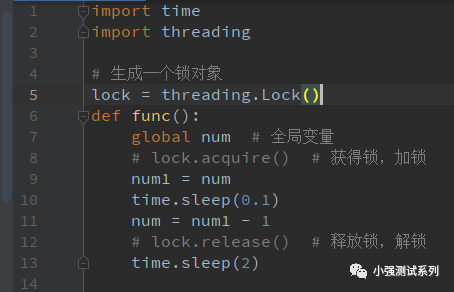
注意,第10行,这里增加了一个sleep()操作,当在没有锁的情况下线程将在这里被释放出来,让给下一线程运行,而我们的num值还没有被修改,所以后面线程的num1的取值都是100。
Lock 与GIL(全局解释器锁)存在区别。
我们需要知道 Lock 锁的目的,它是为了保护共享的数据,同时刻只能有一个线程来修改共享的数据,而保护不同的数据需要使用不同的锁。
GIL用于限制一个进程中同一时刻只有一个线程被CPU调度,GIL的级别比Lock高,GIL是解释器级别。
GIL与Lock同时存在,程序执行如下:
1. 同时存在两个线程:线程A,线程B
2. 线程A 抢占到GIL,进入CPU执行,并加了Lock,但为执行完毕,线程被释放
3. 线程B 抢占到GIL,进入CPU执行,执行时发现数据被线程A Lock,于是线程B被阻塞
4. 线程B的GIL被夺走,有可能线程A拿到GIL,执行完操作、解锁,并释放GIL
5. 线程B再次拿到GIL,才可以正常执行
通过上述应该能看到,Lock 通过牺牲执行的效率换数据安全。
2.2 死锁
多线程最怕的是遇到死锁,两个或两个以上的线程在执行时,因争夺资源被相互锁住而相互等待。如果两个锁同时被多个线程运行,就有可能出现死锁,如果没出现死锁,就多运行几遍就会出现死锁现象。
2.3 重入锁(递归锁) threading.RLock()
为了支持同一个线程中多次请求同一资源,Python 提供了可重入锁(RLock)。这个RLock内部维护着一个锁(Lock)和一个计数器(counter)变量,counter 记录了acquire 的次数,从而使得资源可以被多次acquire。直到一个线程所有 acquire都被release(计数器counter变为0),其他的线程才能获得资源。使用重入锁时,counter 没有变为0(所有的acquire没有被释放掉),即使遇到长时间的io操作也不会切换线程。

















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









