




漏洞名称:
http response splitting attack ,HTTP响应头拆分漏洞
描述:
HTTP响应头拆分漏洞(CRLF)”是一种新型的web攻击方案,它重新产生了很多安全漏洞包括:web缓存感染、用户信息涂改、窃取敏感用户页面、跨站脚本漏洞。这项攻击方案,包括其衍生的一系列技术产生,是由于web应用程序没有对用户的提交进行严格过滤,导致非法用户可以提交一些恶意字符,更具体来说,是对用户输入的CR 和LF字符没有进行严格的过滤。CRLF是”回车 + 换行”(\r\n)的简称。在HTTP协议中,HTTP Header与HTTP Body是用两个CRLF分隔的,浏览器就是根据这两个CRLF来取出HTTP 内容并显示出来。所以,一旦我们能够控制HTTP 消息头中的字符,注入一些恶意的换行,这样我们就能注入一些会话Cookie或者HTML代码,所以CRLF Injection又叫HTTP Response Splitting(HRS)。是应用程序没有正确的过滤用户提供的输入。远程攻击者可以利用这个漏洞影响或错误的显示Web内容服务,缓存或解释的方式,这可能帮助诱骗客户端用户,导致跨站脚本,缓存破坏或页面劫持等漏洞。
(补充:
HRS 是比XSS 危害更大的安全 问题 ,具体是 为 什 么 ,我 们 往下看。对 于HRS 最 简单 的利用方式是注入两个\r\n ,之后在写入XSS 代 码 ,来构造一个xss 。
类 似 这样头 部信息HTTP/1.1 302 Moved Temporarily\r\n Date: Wed, 1 Mar 2005 15:26:41 GMT\r\n Location: http://192.168.0.1/isno.jsp?lang=Allyesno\r\n Content-Length: 0\r\n HTTP/1.1 200 OK\r\n Content-Type: text/html\r\n Content-Length: 24\r\nCRLF)
检测条件:
1.Web业务运行正常
2.HTTP Header可进行篡改。
检测方法:
通过web扫描工具进行扫描检测,或者手工去判断,手工判断举例:一般网站会在HTTP头中用Location: http://baidu.com这种方式来进行302跳转,所以我们能控制的内容就是Location:后面的XXX某个网址,如下所示为抓包得到的相关数据包:
HTTP/1.1 302 Moved Temporarily Date: Fri, 27 Jun 2014 17:52:17 GMT Content-Type: text/html Content-Length: 154 Connection: close Location: http://www.sina.com.cn然后手工输入链接:
http://www.sina.com.cn%0aSet-cookie:JSPSESSID%3Dwooyun后, 注入了一个换行 再次抓包得到如下
HTTP/1.1 302 Moved Temporarily Date: Fri, 27 Jun 2014 17:52:17 GMT Content-Type: text/html Content-Length: 154 Connection: close Location: http://www.sina.com.cn Set-cookie: JSPSESSID=wooyun这个时候这样我们就给访问者设置了一个SESSION,可以发现在http header处多了一行,如果某应用刚好可以受这个参数控制,那将会有重大影响,否则,该漏洞的危害比较小。。当然,HRS并不仅限于会话固定,通过注入两个CRLF就能造成一个无视浏览器Filter的反射型XSS (注:两次”lr'n“意味着HTTP头的结束,在两次CRLF之后跟着就是HTTP Bodyo攻击者在两次CRLF之后构造了恶意的HTML脚本,从而得以执行, XSS攻击成功。
)比如一个网站接受url 参数http://test.sina.com.cn/?url=xxx ,xxx 放在Location 后
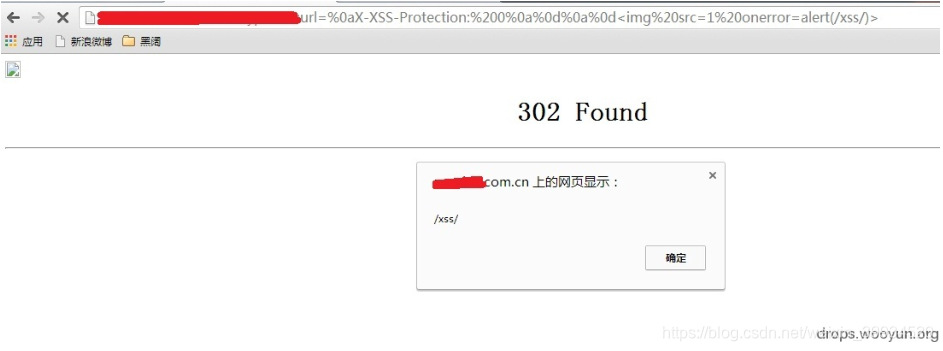
面作 为 一个跳 转 。如果我们输入的是:http://test.sina.com.cn/?url=%0d%0a%0d%0a<img src=1 onerr or=alert(/xss/)>我 们 的返回包就会 变 成 这样
HTTP/1.1 302 Moved Temporarily Date: Fri, 27 Jun 2014 17:52:17 GMT Content-Type: text/html Content-Length: 154 Connection: close Location: <img src=1 onerror=alert(/xss/)>之前 说 了 浏览 器会根据第一个CRLF 把HTTP 包分成 头 和体,然后将体显示出来。于是我 们这 里
这 个 标签就会显示出来,造成一个XSS 。
为 什 么说 是无 视浏览 器filter 的, 这 里 涉 及到另一个 问题 。
浏览 器的Filter 是 浏览 器 应对 一些反射型XSS 做的保 护 策略,当url 中含有XSS相关特征的时候就会过滤掉不显示在页面中,所以不能触 发XSS 。怎 样 才能 关 掉filter ?一般来 说 用 户这边是不行的,只有数据包中http 头 含有X-XSS-Protection 并且 值为0 的 时 候, 浏览 器才不会 开 启filter 。
说 到 这 里 应该 就很清楚了,HRS 不正是注入HTTP 头 的一个漏洞 吗 ,我 们 可以将X-XSS-Protection:0 注入到数据包中,再用两个CRLF 来注入XSS 代 码 , 这样 就成功地 绕过 了 浏览 器filter ,并且 执 行我 们 的反射型XSS 。
所以 说HRS 的危害大于XSS ,因为它能绕过 一般XSS 所 绕 不 过 的filter ,并能 生会话我们来一个真 实 案例吧。
新浪某分站含有一个url 跳转漏洞,危害并不大,于是我就想到了CRLF Injection ,当我测试
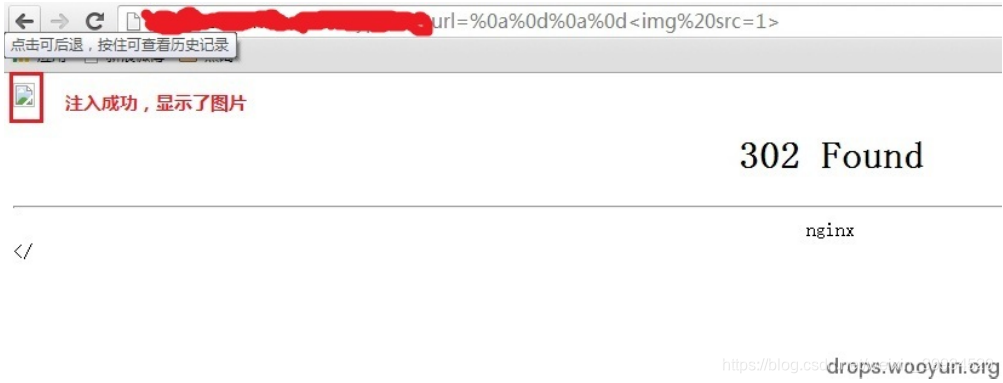
http://xxx.sina.com.cn/?url=%0a%0d%0a%0d%3Cimg%20src=1%3E的 时 候, 发现图 片已 经输 出在 页 面中了, 说 明CRLF 注入成功了:
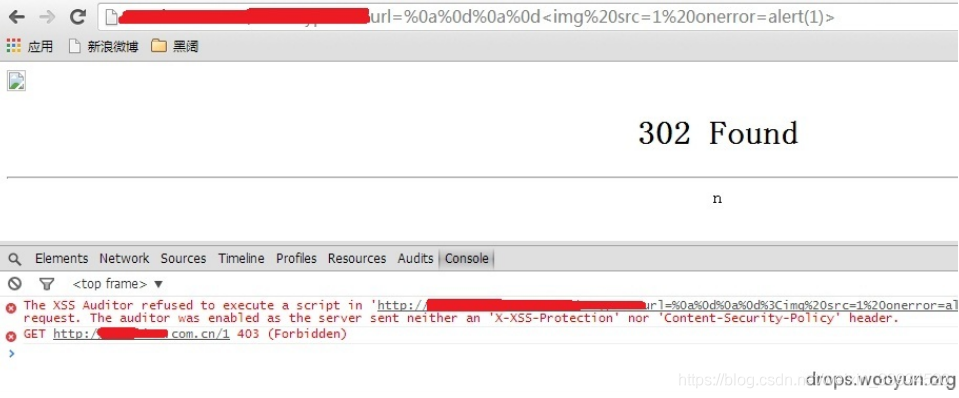
那么我们试试XSS
看控制台,果然被XSS Filter 拦 截了。
那 么 我 们就注入一个X-XSS-Protection:0到数据包中,看看什么效果
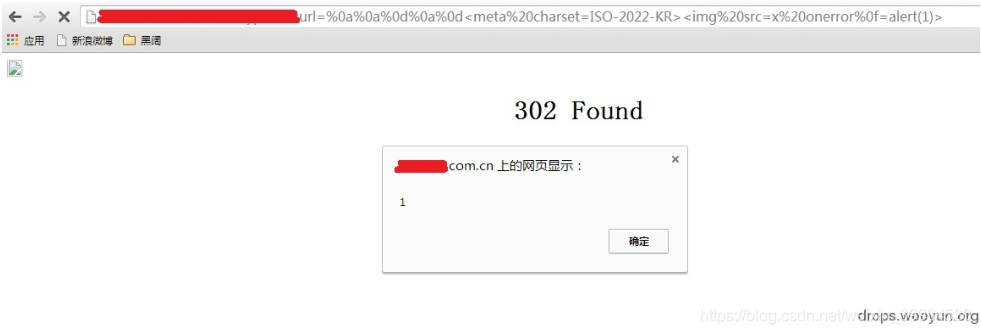
还有一个是利用字符编码来绕过XSS Filter 的方法,当编码是is-2022-kr 时浏览器会忽略%0f , 这样 我 们 在onerror 后面加个%0f 就能绕过filter ,
前提是注入一个<meta charset=ISO-2022-KR>
当然,在Location: 这 里注入只有webkit 内核 浏览 器才能 够 利用,其他 浏览器 器
可能会跳 转 、出 错 。不 过对于chrome 的使用量来 说 ,危害已 经 足 够 了。补充:(POST型)

修复漏洞:
1.建议过滤\r 、\n之类的换行符,避免输入的数据污染到其他HTTP头。具体过滤措施,可参考SQL注入的修复方案。
2.这种现象往往表现在带有参数传递的网页,只要合理的过滤好就 OK 啦, PHP 语言的一些过滤方法:
$post = = trim($post); $post = = strip_tags($post,""); // 清除 HTML 等代码 $post = = ereg_replace("\t","",$post); // 去掉制表符号 $post = = ereg_replace("\r\n","",$post); // 去掉回车换行符号 $post = = ereg_replace("\r","",$post); // 去掉回车 $post = = ereg_replace("\n","",$post); // 去掉换行 $post = = ereg_replace(" ","",$post); // 去掉空格 $post = = ereg_replace("'","",$post); //去掉单引号
其他补充:
来自:HTTP | HTTP报文
01概述
客户端与服务器端之间的通信,通过HTTP协议,以HTTP报文的形式来实现数据的交互。
HTTP报文是HTTP通信时发送的数据块,本文主要从以下几个方面介绍HTTP报文:HTTP报文结构、方法、状态码、首部。
02 报文结构
HTTP报文由三部分组成:状态行(请求行 | 响应行)、首部、主体。也有些书籍说是由首部和主体两部分组成,状态行包含在首部中,但绝大多数的说法是由三部分组成。
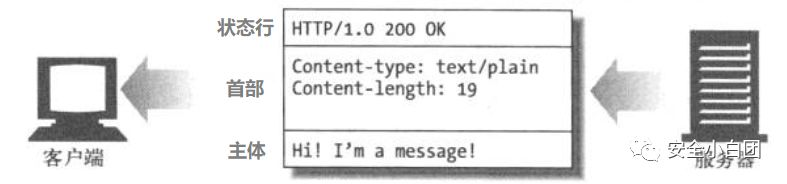
HTTP报文可以分为请求报文和响应报文;请求报文向服务器传达请求,响应报文将请求的结果返回给客户端。以下两图,分别是请求报文以及响应报文的结构图。
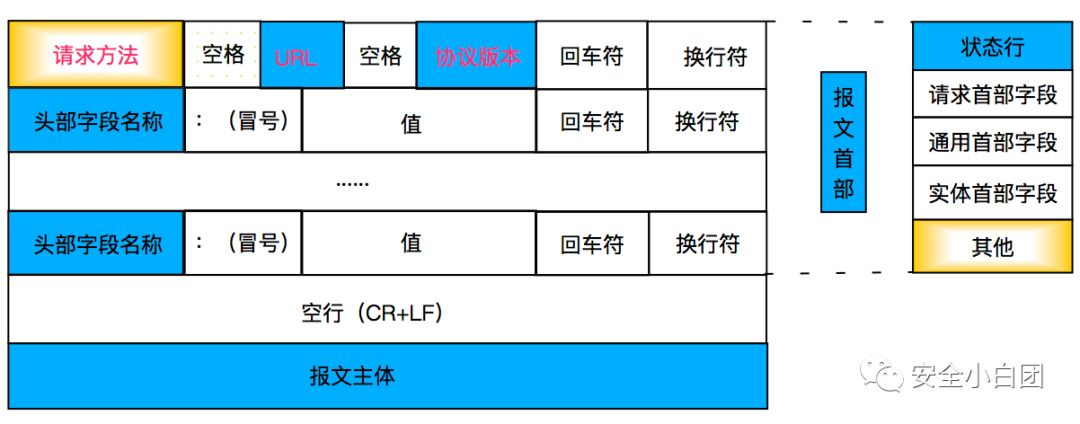
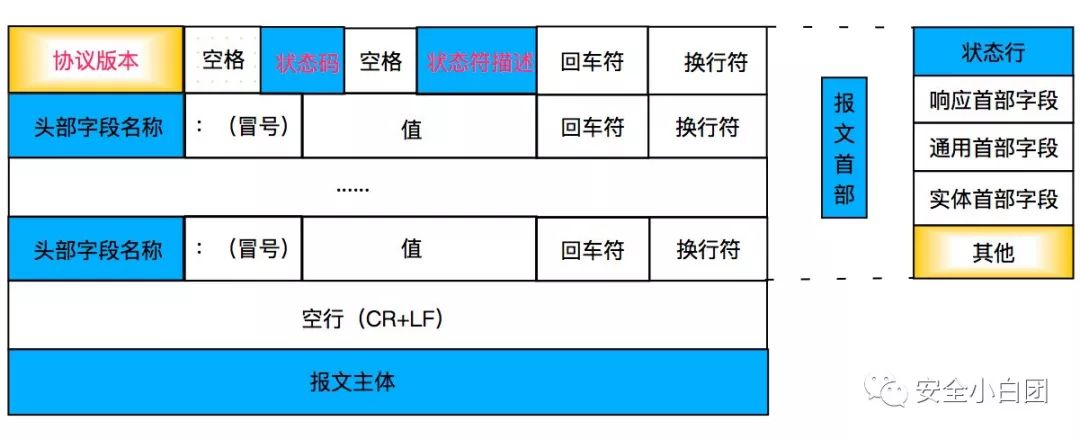
HTTP报文以状态行开始,跟在后面的是HTTP首部,首部由多个首部字段构成,每行一个首部字段;HTTP首部后是一个空行,然后是报文主体。
可以看到,状态行和首部中的每行都是以回车符(\r,%0d,CR)和换行符(\n,%0a,LF)结束,这是因为HTTP规范中行应该使用CRLF结束。另外,首部和主体之间由一空行隔开,或者可以理解为HTTP首部的最后一个字段有两个CRLF。
与状态行和首部不同的是,主体是可选的,也就是说报文中不一定要有主体;另外状态行和首部是ASCII文本,主体可包含文本或二进制数据。
以上就是HTTP报文的大概结构,下面分别对这三部分进行简要描述。
状态行
HTTP报文以状态行开始,请求报文中的状态行叫请求行,响应报文中的状态行叫响应行。
请求行由请求方法、URL、协议版本组成,这些字段都由空格分隔。

请求行表明要对哪个资源执行哪个方法,具体有哪些请求方法,文章后面会详细介绍。
响应行由协议版本、状态码、原因短语(状态码描述)组成。这些字段同样都由空格分隔。

响应行表明了服务器对请求的处理结果,由状态码体现。值得注意的是,原因短语是数字状态码的可读版本,描述数字状态码的含义,便于人理解,只对人有意义,因此以下两种响应行都会被当作成功处理。
HTTP/1.0 200 NOT OK
HTTP/1.0 200 OKHTTP协议将状态码分成了5类,在下面的章节中会详细介绍。
另外请求行和响应行中都包含HTTP版本号,其格式为
HTTP/<major>.<minor>major是主版本号,minor是次版本号,使用版本号的目的是规范双方之间通信的格式。
首部
HTTP首部由多个首部字段构成,旨在向报文中添加一些通信过程中所需的重要信息。具体细节文章后面会介绍。
主体
报文主体包含了HTTP所要传输的内容,但并不是所有的报文都有主体。
03 方法
状态行部分讲到请求行中包含请求方法字段,请求方法告诉服务器要做什么。下图是HTTP规范中目前已定义的方法,红框中的是比较常用的方法。
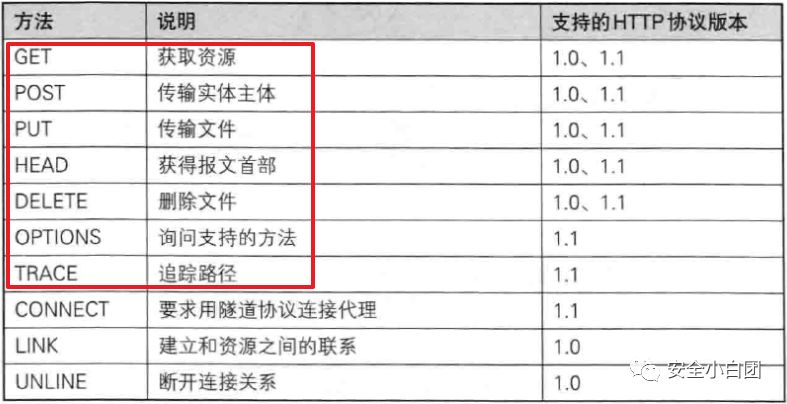
注意,不是所有的服务器都会实现这些方法,一般都会实现GET和POST方法。另外,请求方法需要大写。
GET
GET:获取/查询资源。是最常用的HTTP方法,常用于请求URL指定的资源,服务端经过处理将资源返回给客户端。
比如访问百度首页,请求包如下,百度的服务器收到请求后,将百度首页返回给浏览器。
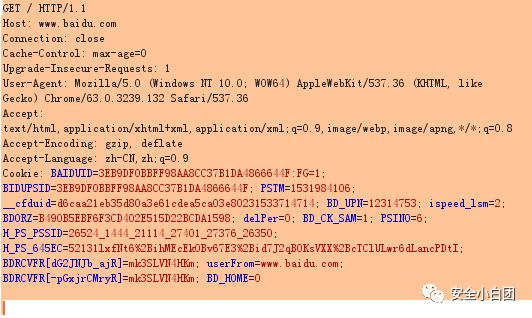
有时请求会传递一些参数给服务器,在GET方法中,这些参数会被包含在URL中,放在文件路径后面,用“ ? ”分隔,被称为查询字符串。查询字符串以键值对的形式存在,每个参数的键和值用“=”连接,不同参数之间用“&”符号连接。(详情请看URL格式)
百度搜索google,抓包可以发现,google被当成了word参数的参数值,放在请求行的URL字段中。
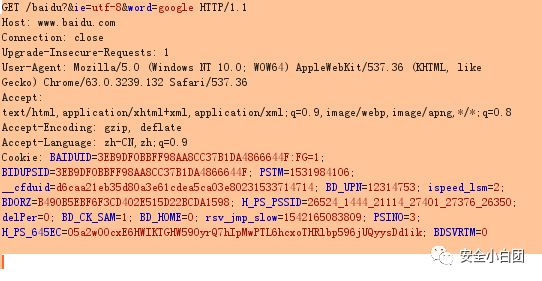
特意将请求报文全选,大家可以看到,首部字段下方有一空行,然后空行下面有一光标,这再次体现了HTTP报文的结构,也告诉大家,GET请求是不包含请求主体的。
POST
POST:传输实体主体。常用于向指定资源发送数据,指定的资源会对数据进行处理,然后将处理结果返回给客户端。数据被包含在请求主体中,一般用于表单提交、文件上传等。
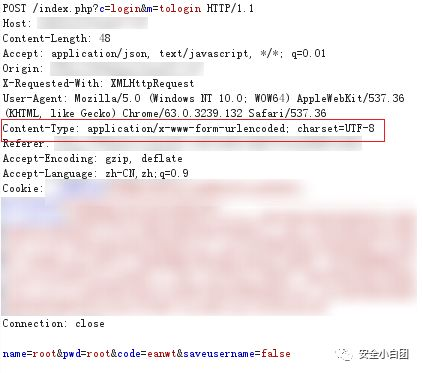
以上是登录时的请求包,请求主体中包含了用户名、密码、验证码、是否记住用户名的参数数据,服务器接收到请求后,会交给index.php文件去处理,然后会返回一个处理结果,可能是登录失败,也可能是跳转到系统内部。
可以看到,这些数据的格式和查询字符串的格式一致,Content-Type字段值为application/x-www-form-urlencoded,这是POST提交数据的几种格式之一,POST提交数据的几种格式会在以后的文章中介绍。
当然,GET方法也可以用来传输数据,但是首先URL的长度受浏览器、服务器、操作系统影响,其次是GET方法提交的参数都会在地址栏中显示出来,不安全,因此涉及到大量数据、敏感数据的时候,一般采用POST方法。
HEAD
HEAD:获取报文首部。HEAD方法和GET方法很像,但服务器接收到HEAD请求时,在响应中只会返回报文首部,不会返回报文主体。常用于测试请求资源是否存在或是否被修改。
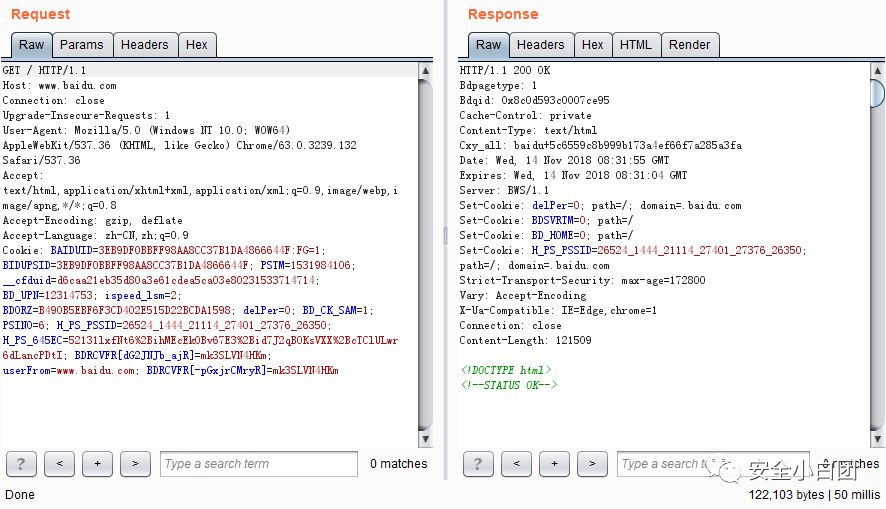
GET请求,除了返回报文首部,还返回了主体,经浏览器解析,成为我们眼中的百度首部。
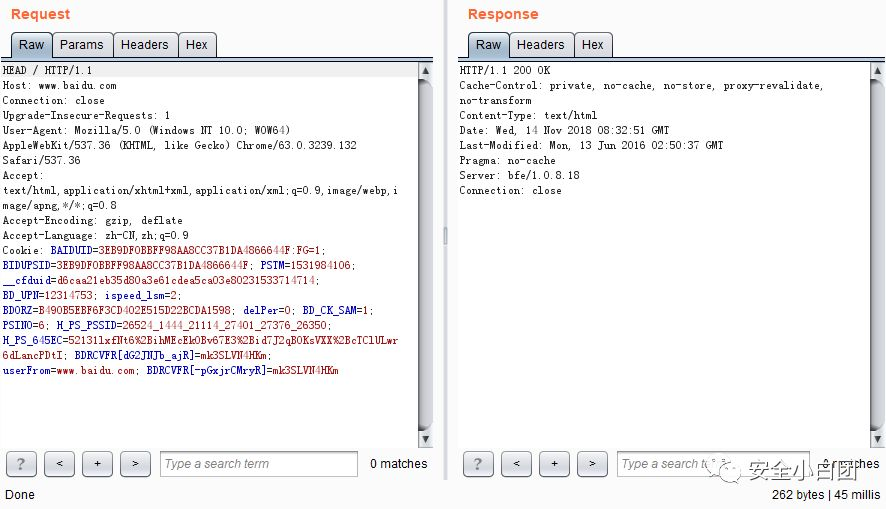
HEAD请求,只返回首部,没有主体。
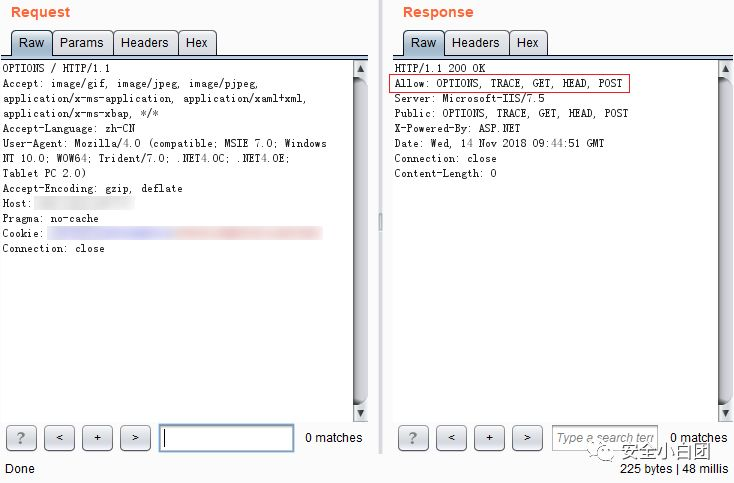
OPTIONS
OPTIONS:查询资源支持的方法。用于查询URL指定的资源支持哪些方法,资源支持哪些方法,会在响应包的Allow字段中显示。
PUT
PUT:传输文件。服务器会将请求主体的内容保存到URL指定的资源位置,包含两种情况:URL指定的资源不存在和URL指定的资源存在。
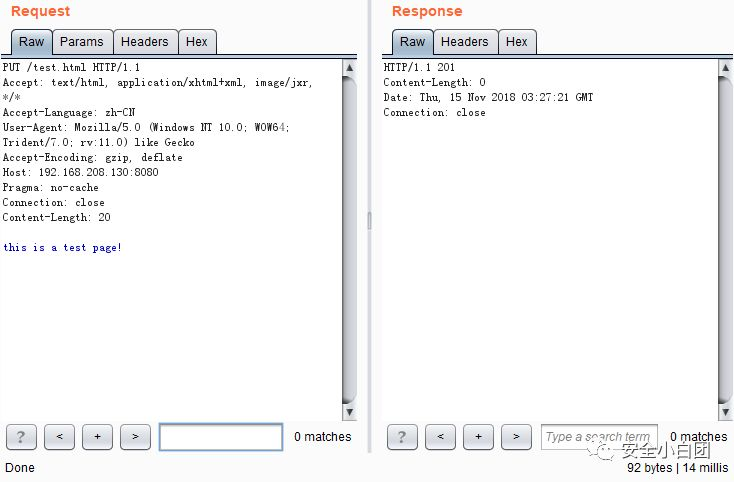
如果URL指定的资源不存在,服务器会新建一个文件,将请求主体中的内容保存到新建的文件里,响应码为201。
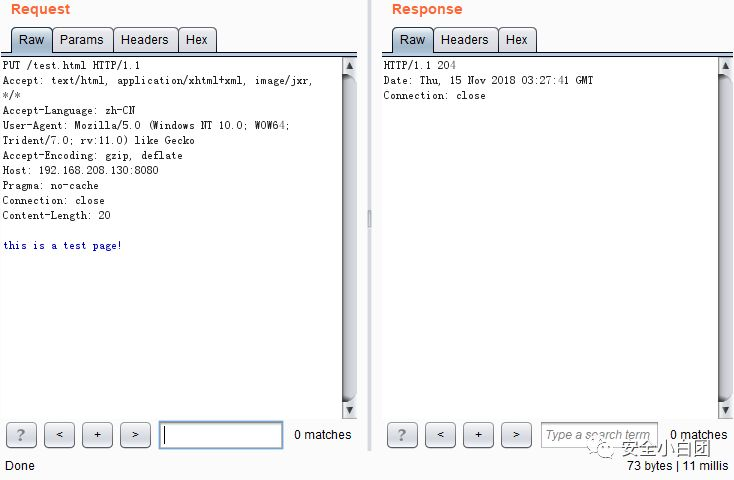
如果URL指定的资源存在,服务器会重置文件内容,用请求主体中的内容覆盖原文件内容,响应码为200或204。
需要注意的是,PUT方法自身不带验证机制,任何人都可以执行,存在安全问题,所以网站一般不会使用PUT方法。
DELETE
DELETE:删除文件,删除URL指定的资源,和PUT相反。
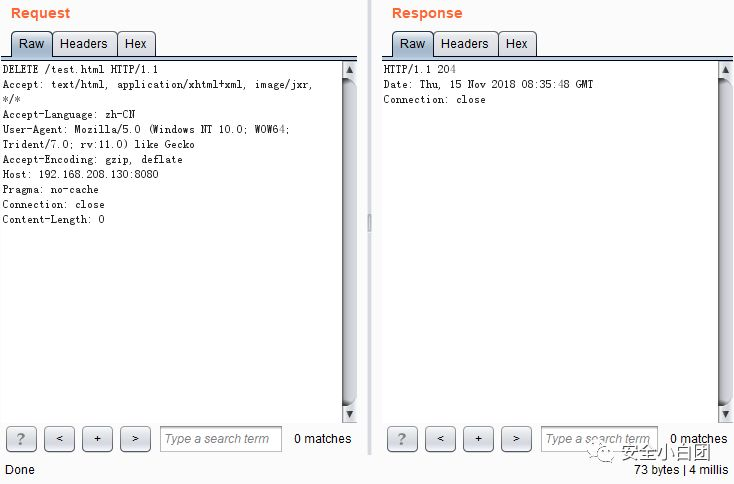
文件删除成功,响应码为204。
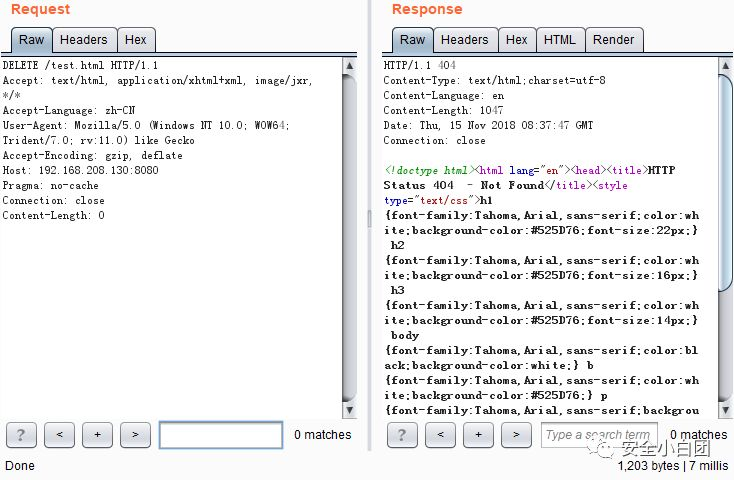
若删除的文件不存在,响应码为404。
和PUT一样,DELETE方法同样不带验证机制,所以网站一般也不使用DELETE方法。
TRACE
TRACE:路径追踪。主要用于诊断,让服务器将收到的请求放在响应主体中,环回给客户端,这样客户端就可以判断发出的请求是否被请求/响应链(在客户端和服务器端之间,请求可能会经过代理、网关、防火墙等应用程序)篡改。
TRACE请求不能带有实体的主体部分,TRACE响应的实体主体包含服务器收到的请求。
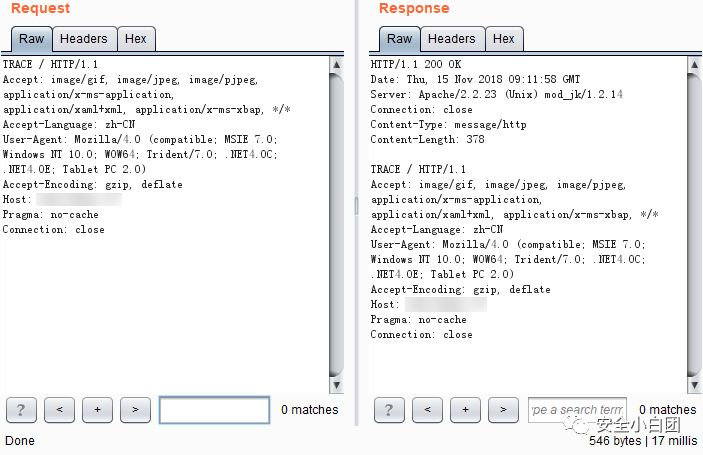
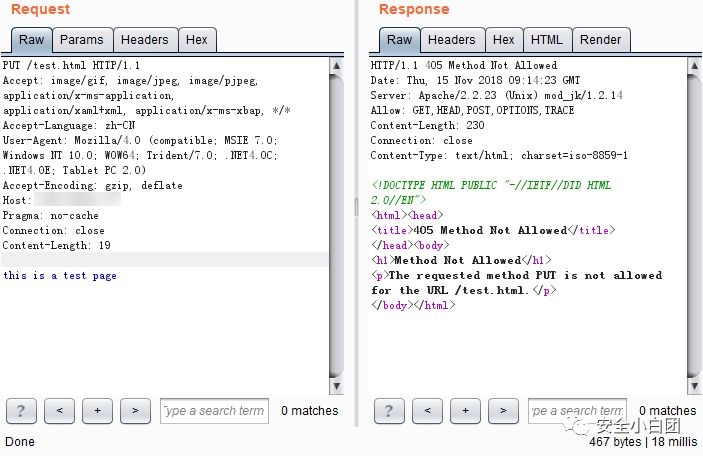
以上都是方法没被禁用时的响应,如果方法被禁用,响应码为405。
HTTP是可扩展的。除了使用HTTP/1.1规范中定义的方法,有的扩展还定义了一些新的方法,被称为扩展方法。
以下是WebDAV HTTP扩展包含的方法。
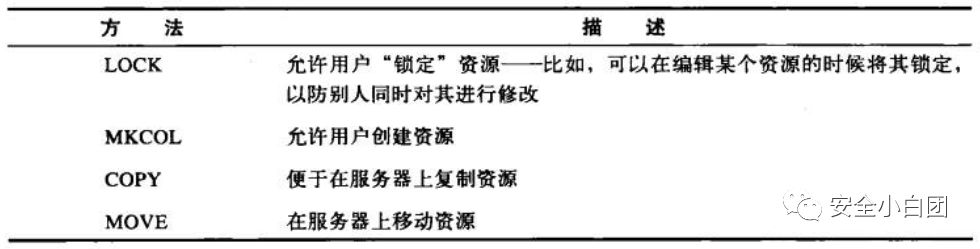
04 状态码
请求方法告诉服务器要做什么,状态码则告诉客户端,服务器对请求的处理结果:是正常处理了请求,还是出现了错误。HTTP状态码被分成了以下5类。

1xx——信息提示
1xx响应表明服务器端正在处理客户端发过来的请求。

2xx——成功
2xx响应表明服务器端正常处理了客户端发过来的请求。
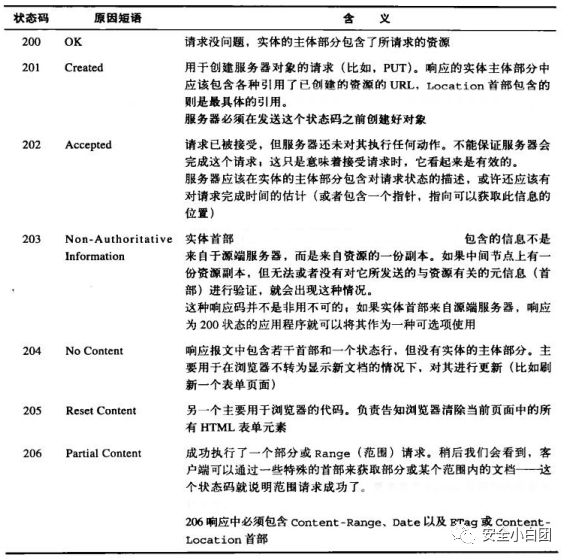
常用的有:
200(成功)、201(已创建)、204(无内容)、206(部分内容)
3xx——重定向
3xx响应表明客户端请求的资源的位置发生了改变,要完成请求,需进一步操作。


常用的有:301(永久移动)、302(临时移动)
4xx——客户端错误
4xx响应表明客户端发过来的请求有问题,服务器无法处理。
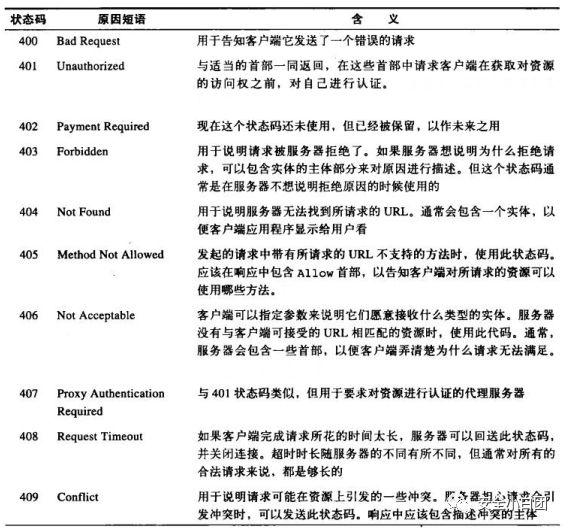
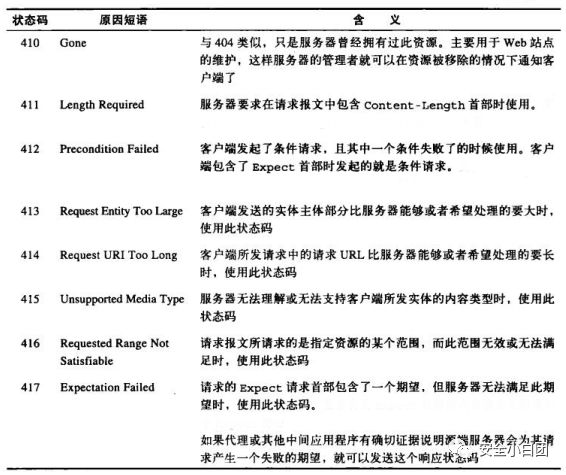
常用的有:
400(语法错误)、401(未认证)、403(禁止访问)、404(未找到)、405(方法禁用)
5xx——服务器错误
5xx响应表明服务器自身出了问题,处理不了客户端发过来的请求。


常用的有:500(服务器错误)、502(网关错误)
05 首部
HTTP首部由多个首部字段构成,旨在向报文中添加一些通信过程中所需的重要信息。
从本质上来说,首部字段是名/值对,由字段名和字段值组成,中间用冒号“ : ”隔开,字段值前可包含一个空格。每一行一个首部字段,由CRLF结束行。注意,首部应该以空行(单个CRLF)结束,即使没有主体。
首部字段名: 字段值根据用途,HTTP首部字段被分为4类:通用首部、请求首部、响应首部、实体首部。
首部字段不一定都是HTTP/1.1规范定义的,其中,HTTP/1.1规范中定义的首部字段只有47种。下列表格中的都是HTTP/1.1规范定义的首部字段。
通用首部
请求报文和响应报文都可以使用的首部。
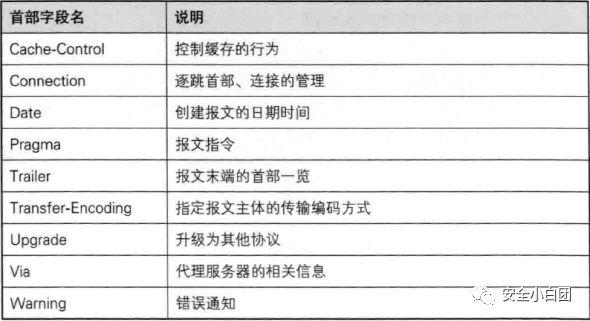
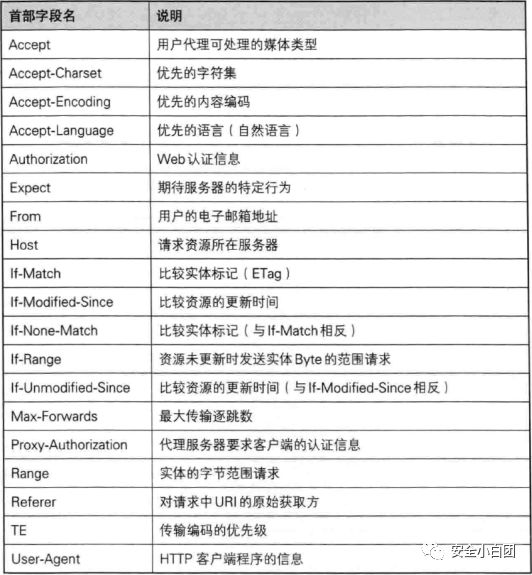
请求首部
请求报文使用的首部。
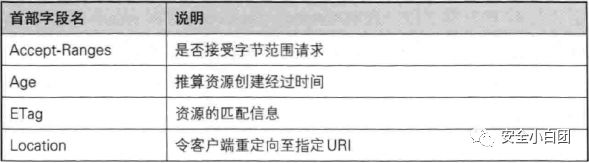
响应首部
响应报文使用的首部。
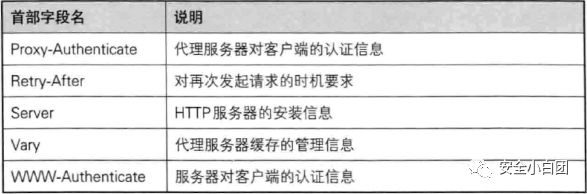
实体首部
实体使用的首部。
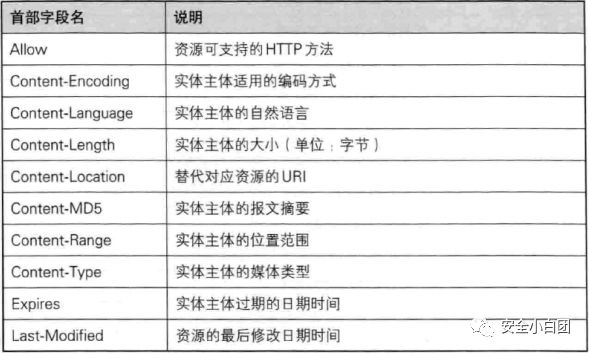
HTTP首部除了使用HTTP/1.1规范中定义的首部字段,还会使用其他RFC中定义的首部字段,比如Cookie、Set-Cookie等。
-------------------------------------------------------------------------
漏洞知识拓展
CRLF 指的是回车符(CR,ASCII 13,\r,%0d) 和换行符(LF,ASCII 10,\n,%0a)。
CRLF的概念源自打字机,表明行的结束,计算机出现后沿用了这个概念。
回车符:光标移到行首,
换行符:光标垂直移到下行。
键盘上的回车键(Enter)就可以执行该操作。但是不同的操作系统,行的结束符是不一样的。
Windows:使用CRLF表示行的结束
Linux/Unix:使用LF表示行的结束
MacOS:早期使用CR表示,现在好像也用LF表示行的结束
所以同一文件在不同操作系统中打开,内容格式可能会出现差异,这是行结束符不一致导致的。
在HTTP规范中,行应该使用CRLF来结束。首部与主体由两个CRLF分隔,浏览器根据这两个CRLF来获取HTTP内容并显示。
漏洞检测
CRLF注入漏洞的本质和XSS有点相似,攻击者将恶意数据发送给易受攻击的Web应用程序,Web应用程序将恶意数据输出在HTTP响应头中。(XSS一般输出在主体中)
所以CRLF注入漏洞的检测也和XSS漏洞的检测差不多。通过修改HTTP参数或URL,注入恶意的CRLF,查看构造的恶意数据是否在响应头中输出。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









