





更多原创
编程/机器学习/数据科学/FinTech/量化投资 干货......
欢迎关注与标星★公众号哟~
说到数据可视化,我们第一反应一定是大名鼎鼎的matplotlib,
那么啥是seaborn呢?
我们首先介绍一下什么是Seaborn,为啥是matplotlib的“升级版”呢?
Seaborn是基于matplotlib的图形可视化python包。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。
也就是说Seaborn是在matplotlib的基础上进行了更高级的API封装,能让我们直接调用seaborn能做出很具有吸引力的图,并且便于我们对可视化的图形进行分析。
当然,并不是说大家用了seaborn后就完全抛弃matplotlib,因为使用matplotlib就能制作具有更多特色的图,能实现更多的定制化。
seaborn官网:http://seaborn.pydata.org/
首先我们需要安装seaborn,如果已经安装了最新版本anaconda,应该已经有seaborn了,我们可以通过命令行或者anaconda navigator进行查看:
当然,也可以直接通过pip进行安装:
python3 -m pip install --upgrade pip
# 安装包并安装这个包所需的依赖包
pip3 install seaborn -U
# 或者
pip3 install scipy
pip3 install seaborn
安装完毕后,我们可以直接按照seaborn相应的API规则直接调用相应功能,一般格式如下:
sns.图名(x='X轴 列名', y='Y轴 列名', data=原始数据df对象)
sns.图名(x='X轴 列名', y='Y轴 列名', hue='分组绘图参数', data=原始数据df对象)
sns.图名(x=np.array, y=np.array[, ...])
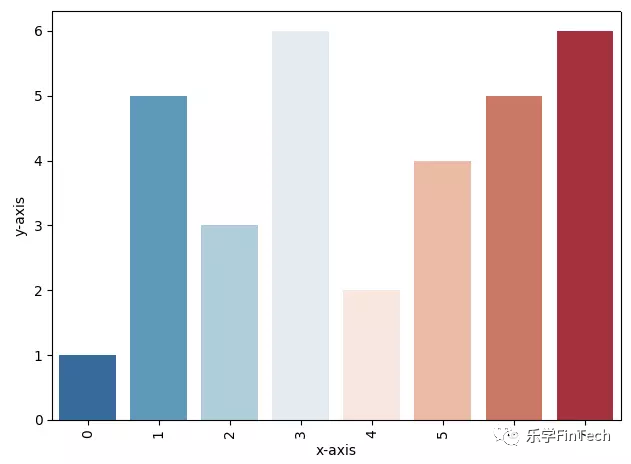
以柱形图为例,
seaborn.barplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, estimator=<function mean>, ci=95, n_boot=1000, units=None, orient=None, color=None, palette=None, saturation=0.75, errcolor='.26', errwidth=None, capsize=None, dodge=True, ax=None, **kwargs)
比如说我们假设一组测试数据,如果需要调用seaborn
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.arange(8)
y = np.array([1,5,3,6,2,4,5,6])
df = pd.DataFrame({"x-axis": x,"y-axis": y})
sns.barplot("x-axis","y-axis",palette="RdBu_r",data=df)
plt.xticks(rotation=90)
plt.show()
接下来我们用真实的金融数据作为输入,并用seaborn做可视化辅助我们进行判断:
import pandas as pd
import seaborn as sns
import tushare as ts
通过tushare作为数据来源,我们调取000001股票2018年-2019年6月30日的数据:
pro = ts.pro_api()
df = pro.daily(ts_code='000001.SZ', start_date='20180101', end_date='20190630')
df.head()
tushare数据倒序与数据类型的坑我们在很多地方都提到过,稍微做一下变换
# pandas有个专门把字符串转为时间格式的函数,to_datetime。第一个参数是原始数据,第二个参数是原始数据的格式
df['trade_date'] = pd.to_datetime(df['trade_date'],format='%Y%m%d')
# 把trade_date设置为索引
df.set_index('trade_date',inplace=True)
df.head()
排序
df=df.sort_index(ascending=True)
df.head()
比如说我现在需要判断这只股票在一段时间内的涨跌分布:
可以通过:
returns=df["pct_chg"].dropna()
sns.distplot(returns)
returns.head()
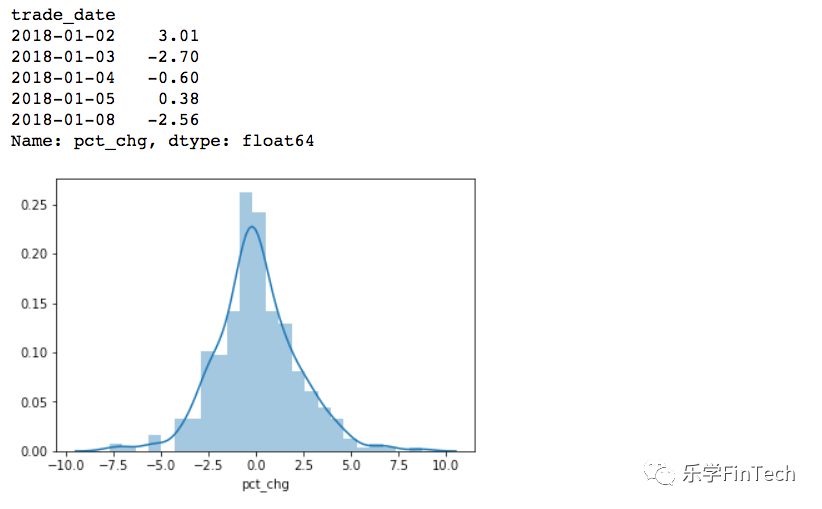
我们会发现这只股票的涨跌还是基本围绕在小幅度波动,出现极端涨跌停的情况极少,我们可以通过这样的可视化进行进一步的研究方向的判断(比如,极端情况多不多,是否存在暴涨暴跌或者长期横盘的情况等等)
我们再来研究一个主题吧,看看可视化能帮我们做出怎样的判断,比如经常我们可能会做出这样看似“显而易见”的推断:
航空股与石油股肯定是反向变动的关系,因为石油价格涨,石油股价格涨,航空股成本上升,所以跌。
看似很有道理,但是我们不妨拿中国国航与中石油做一次实验:
中国国航:
df_ZGGH= pro.daily(ts_code='601111.SH', start_date='20180101', end_date='20190630')
# pandas有个专门把字符串转为时间格式的函数,to_datetime。第一个参数是原始数据,第二个参数是原始数据的格式
df_ZGGH['trade_date'] = pd.to_datetime(df_ZGGH['trade_date'],format='%Y%m%d')
# 把trade_date设置为索引
df_ZGGH.set_index('trade_date',inplace=True)
df_ZGGH=df_ZGGH.sort_index(ascending=True)
df_ZGGH.head()
中石油:
df_ZGSY= pro.daily(ts_code='601857.SH', start_date='20180101', end_date='20190630')
# pandas有个专门把字符串转为时间格式的函数,to_datetime。第一个参数是原始数据,第二个参数是原始数据的格式
df_ZGSY['trade_date'] = pd.to_datetime(df_ZGSY['trade_date'],format='%Y%m%d')
# 把trade_date设置为索引
df_ZGSY.set_index('trade_date',inplace=True)
df_ZGSY=df_ZGSY.sort_index(ascending=True)
df_ZGSY.head()
光看数据,我们还是一头雾水,这个时候,不妨可视化一下:
sns.jointplot(df_ZGGH['change'], df_ZGSY['change'], kind='reg', height=10)
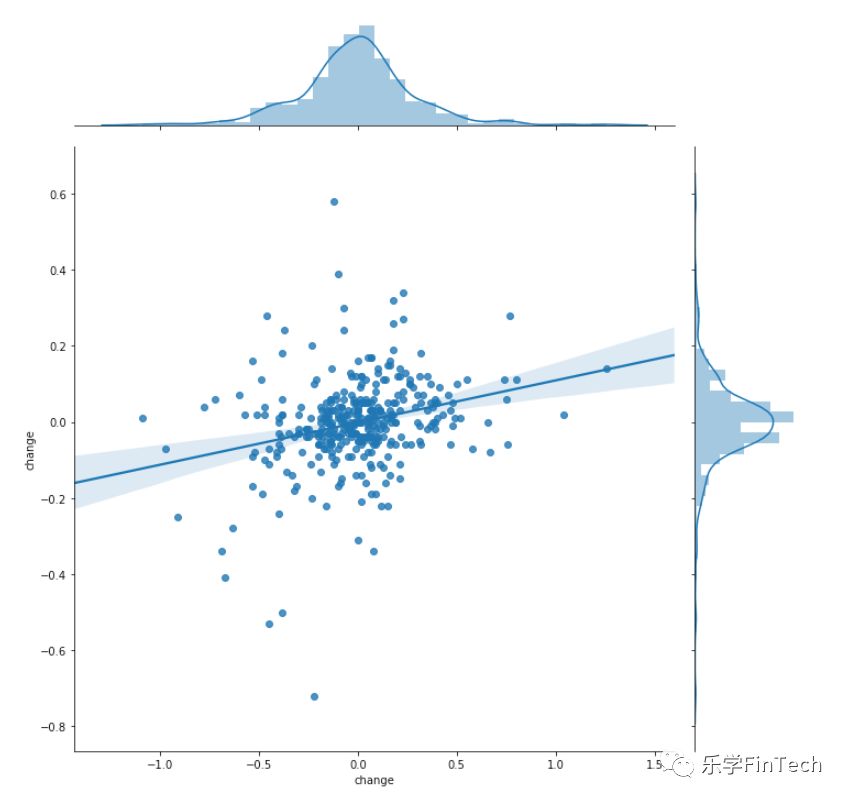
我们可以通过可视化的图非常清楚的看到是呈现正相关的关系,跟我们看似“聪明”的推断完全相反。
也就是说,当下次别人侃侃而谈说:“看,石油板块大跌,赶紧买航空股压压惊的”的时候,可以不着急交易,先分析下,拿出Python与Seaborn,打打代码压压惊。
未完待续......
Hey,想学了那么久的Python,推荐一个超干干货入门合集。用Python做爬虫,数据分析,全栈建设,Fintech金融量化,机器学习,办公自动化,树莓派,美好生活DIY,......2000+连载,不仅有编程,还有更多原理讲解。
更多内容,欢迎点击【阅读原文】订阅连载视频。观看逐行代码与原理讲解与加入同业交流与技术探讨社区。您的支持是公众号更新的动力!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









