






 PyCorrector是一个中文文本纠错工具,包括规则和深度学习两种解决思路。规则模型通过错误检测和纠正两步进行,而深度学习模型如Seq2Seq和Attention模型用于端到端学习。此外,文章介绍了如何源码安装和运行该工具。
PyCorrector是一个中文文本纠错工具,包括规则和深度学习两种解决思路。规则模型通过错误检测和纠正两步进行,而深度学习模型如Seq2Seq和Attention模型用于端到端学习。此外,文章介绍了如何源码安装和运行该工具。
PyCorrector文本纠错工具代码详解
1. 简介
中文文本纠错工具。音似、形似错字(或变体字)纠正,可用于中文拼音、笔画输入法的错误纠正。python3.6开发。pycorrector依据语言模型检测错别字位置,通过拼音音似特征、笔画五笔编辑距离特征及语言模型困惑度特征纠正错别字。
1.1 在线Demo
https://www.borntowin.cn/product/corrector
1.2 Question
中文文本纠错任务,常见错误类型包括:
- 谐音字词,如 配副眼睛-配副眼镜
- 混淆音字词,如 流浪织女-牛郎织女
- 字词顺序颠倒,如 伍迪艾伦-艾伦伍迪
- 字词补全,如 爱有天意-假如爱有天意
- 形似字错误,如 高梁-高粱
- 中文拼音全拼,如 xingfu-幸福
- 中文拼音缩写,如 sz-深圳
- 语法错误,如 想象难以-难以想象
当然,针对不同业务场景,这些问题并不一定全部存在,比如输入法中需要处理前四种,搜索引擎需要处理所有类型,语音识别后文本纠错只需要处理前两种, 其中'形似字错误'主要针对五笔或者笔画手写输入等。
1.3 Solution
1.3.1 规则的解决思路
- 中文纠错分为两步走,第一步是错误检测,第二步是错误纠正;
- 错误检测部分先通过结巴中文分词器切词,由于句子中含有错别字,所以切词结果往往会有切分错误的情况,这样从字粒度和词粒度两方面检测错误, 整合这两种粒度的疑似错误结果,形成疑似错误位置候选集;
- 错误纠正部分,是遍历所有的疑似错误位置,并使用音似、形似词典替换错误位置的词,然后通过语言模型计算句子困惑度,对所有候选集结果比较并排序,得到最优纠正词。
1.3.2 深度模型的解决思路
- 端到端的深度模型可以避免人工提取特征,减少人工工作量,RNN序列模型对文本任务拟合能力强,rnn_attention在英文文本纠错比赛中取得第一名成绩,证明应用效果不错;
- CRF会计算全局最优输出节点的条件概率,对句子中特定错误类型的检测,会根据整句话判定该错误,阿里参赛2016中文语法纠错任务并取得第一名,证明应用效果不错;
- seq2seq模型是使用encoder-decoder结构解决序列转换问题,目前在序列转换任务中(如机器翻译、对话生成、文本摘要、图像描述)使用最广泛、效果最好的模型之一。
1.4 Feature
1.4.1 模型
- kenlm:kenlm统计语言模型工具
- rnn_attention模型:参考Stanford University的nlc模型,该模型是参加2014英文文本纠错比赛并取得第一名的方法
- rnn_crf模型:参考阿里巴巴2016参赛中文语法纠错比赛CGED2018并取得第一名的方法(整理中)
- seq2seq_attention模型:在seq2seq模型加上attention机制,对于长文本效果更好,模型更容易收敛,但容易过拟合
- transformer模型:全attention的结构代替了lstm用于解决sequence to sequence问题,语义特征提取效果更好
- bert模型:中文fine-tuned模型,使用MASK特征纠正错字
- conv_seq2seq模型:基于Facebook出品的fairseq,北京语言大学团队改进ConvS2S模型用于中文纠错,在NLPCC-2018的中文语法纠错比赛中,是唯一使用单模型并取得第三名的成绩
1.4.2 错误检测
- 字粒度:语言模型困惑度(ppl)检测某字的似然概率值低于句子文本平均值,则判定该字是疑似错别字的概率大。
- 词粒度:切词后不在词典中的词是疑似错词的概率大。
1.4.3 错误纠正
- 通过错误检测定位所有疑似错误后,取所有疑似错字的音似、形似候选词,
- 使用候选词替换,基于语言模型得到类似翻译模型的候选排序结果,得到最优纠正词。
1.4.4 思考
- 现在的处理手段,在词粒度的错误召回还不错,但错误纠正的准确率还有待提高,更多优质的纠错集及纠错词库会有提升,我更希望算法上有更大的突破。
- 另外,现在的文本错误不再局限于字词粒度上的拼写错误,需要提高中文语法错误检测(CGED, Chinese Grammar Error Diagnosis)及纠正能力,列在TODO中,后续调研。
2. 安装
作者开源代码中介绍有两种安装方式: + pip安装
pip install pycorrector用户:适合做工程实践,不关心算法细节,直接调包使用。
- 源码安装
git clone https://github.com/shibing624/pycorrector.git
cd pycorrector
python setup.py install用户:希望了解代码实现,做一些深层次修改。
2.1 源码安装步骤详解
我们详细讲解第二种-源码安装方式。除了完成上面源码安装步骤外,我们还需要安装一些必要的库。
2.1.1 安装必要的库
pip install -r requirements.txt2.1.2 安装kenlm
kenlm是一个统计语言模型的开源工具,如图所示,代码96%都是C++实现的,所以效率极高,训练速度快,在GitHub上现有1.1K Star
pip安装kenlm
安装命令如下
pip install kenlm- 笔者尝试直接
pip安装,报了如下错误,机器环境(MAC OS 10.15.4)。

若报错,则进行如下源码安装kenlm,安装成功则跳过该步骤。
源码安装kenlm
- 下载kenlm代码
- 运行安装命令
python setup.py install如下图所示,则已经安装成功。
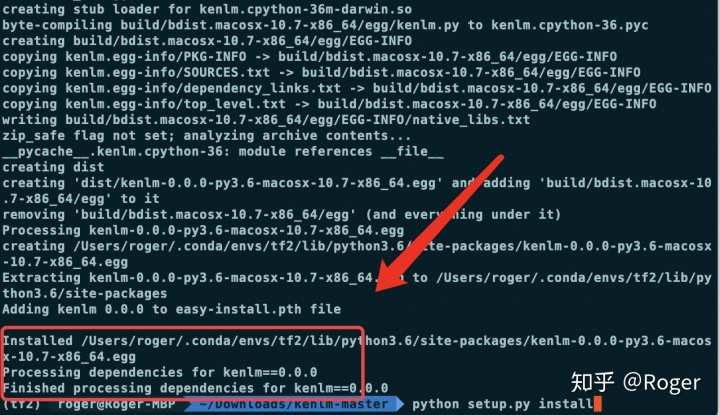
3. 环境测试
3.1 源码结构
代码结构如下(clone时间2020/5/5):
.
├── LICENSE
├── README.md
├── _config.yml
├── build
│ ├── bdist.macosx-10.7-x86_64
│ └── lib
├── dist
│ └── pycorrector-0.2.7-py3.6.egg
├── docs
│ ├── git_image
│ ├── logo.svg
│ └── 基于深度学习的中文文本自动校对研究与实现.pdf
├── examples
│ ├── base_demo.py
│ ├── detect_demo.py
│ ├── disable_char_error.py
│ ├── en_correct_demo.py
│ ├── load_custom_language_model.py
│ ├── my_custom_confusion.txt
│ ├── traditional_simplified_chinese_demo.py
│ └── use_custom_confusion.py
├── pycorrector
│ ├── __init__.py
│ ├── __main__.py
│ ├── __pycache__
│ ├── bert
│ ├── config.py
│ ├── conv_seq2seq
│ ├── corrector.py
│ ├── data
│ ├── deep_context
│ ├── detector.py
│ ├── en_spell.py
│ ├── seq2seq_attention
│ ├── transformer
│ ├── utils
│ └── version.py
├── pycorrector.egg-info
│ ├── PKG-INFO
│ ├── SOURCES.txt
│ ├── dependency_links.txt
│ ├── not-zip-safe
│ ├── requires.txt
│ └── top_level.txt
├── requirements-dev.txt
├── requirements.txt
├── setup.py
└── tests
├── bert_corrector_test.py
├── char 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4639
4639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









