






本文内容主要来自《全局光照技术》。
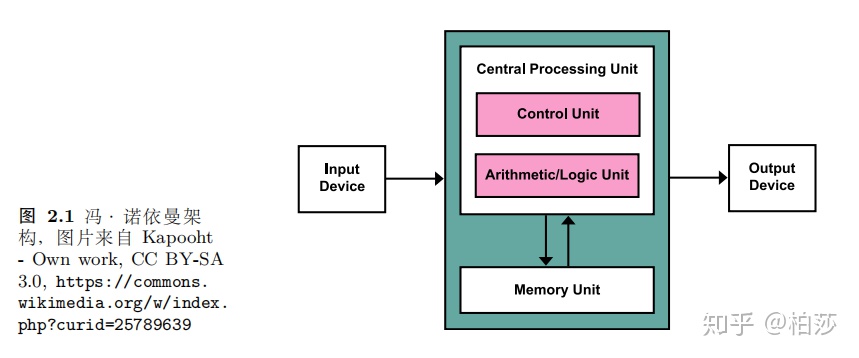
几乎所有处理器都是以冯诺依曼提出的处理器为工作基础。它包括一个算术逻辑单元ALU,高速存储指令和数据的寄存器组和一个控制指令读取的控制单元,还有一个用于存储所有指令和数据的内存,外加一些大容量的存储设备,还有一些输入输出设备。

里面的α成为延迟,β成为带宽,N表示消息长度。现代CPU一般都有多级缓存以及多个核心,在实际程序中,数据集可能非常大,以至于不能放在高速的L1或者L2缓存,所以建议要保持高性能部分的程序足够小,同时也要让高性能部分的数据足够小而且相邻。另外,对于一个固定的数据访问模式,例如遍历数组,那么可以通过数据预取来提高性能,不过如果循环里面是随机获取数据,那么预取就会变得毫无用处。指令预取则可以通过编译好的指令进行预测,不过对于函数指针以及分支条件,可能无法进行准确预测。
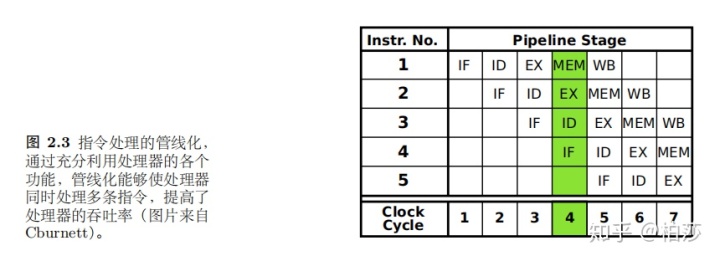
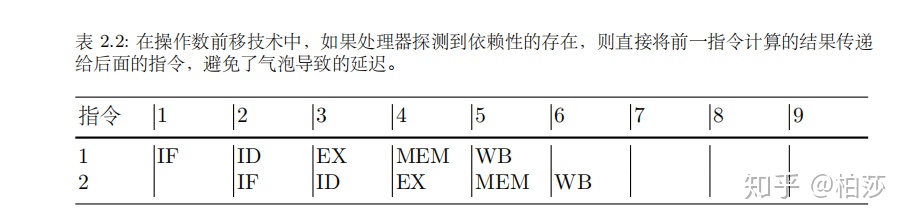
一般指令管线分为五个阶段:

这种流水线的方式可以提高整体性能。
不过由于指令之间可能会有依赖,那么需要一些技术来处理这种情况,例如管线气泡。
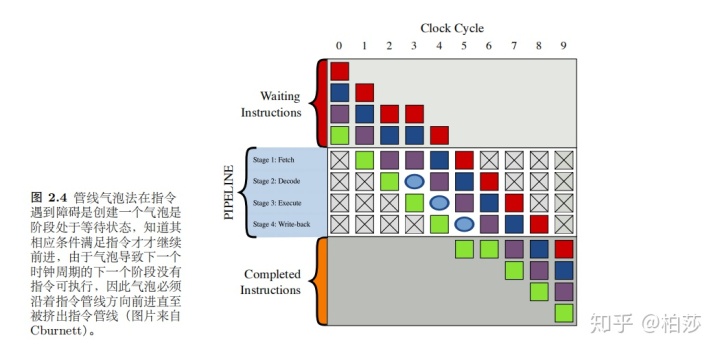
因为紫色依赖于绿色指令的输出,所以在第三个时钟周期的时候,绿色继续往前,而紫色则停下来创建了一个气泡等待。
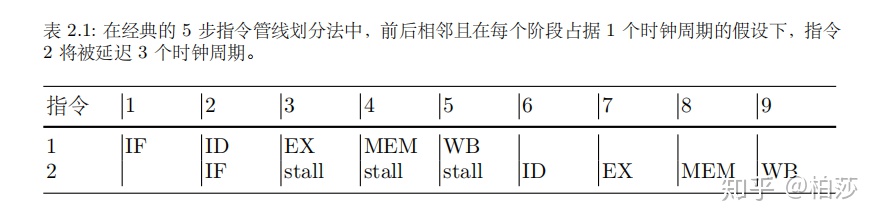
不过要是指令依赖于前面一个指令的结果,是可能存在多个时钟的延迟,如果能够绕开寄存器,直接将指令的结果传递给其他指令,那么可以大大节省延迟周期,这种技术叫做操作数前移。
分支预测失败也会影响指令周期,所以很多时候条件转移语句能够有更好的性能。

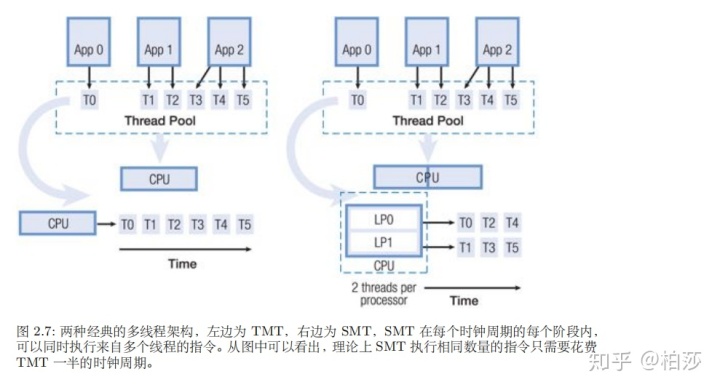
虽然fsel对两个输入值都需要进行计算,相当于计算了原来if条件的两个分支语句,但带来的性能提升依然明显。多线程处理器内部可以支持多个线程并行执行,但这些线程不是真正的同时执行,而是通过处理器的控制交叉的执行,当正在执行的线程遇到缓存失效或者其他事件,处理器就会自动切换到其他处于等待执行状态的线程。当然还可以做到同时执行来自多个线程的指令,这是两种不同的多线程架构,我们现在听说的4核8线程就是后者。
这里再提下SIMD模型,即单指令多数据,一个指令流被并发的广播道多个处理器上,每个处理器拥有自己的数据流,这样,处理器内部只需要一套逻辑来对指令流进行节码和执行,而不需要多个指令节码通道。另外SIMD指令只是在在处理器的SIMD寄存器可以支持向量操作。
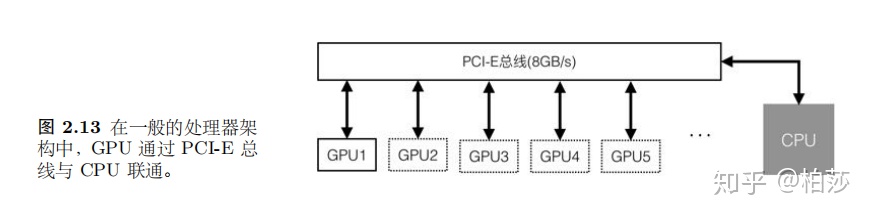
接下来看GPU,首先我们了解下为什么需要GPU。对于大规模并行计算,高速缓存的成本非常高,并且占据芯片空间很大,而且从主存到ALU之间的数据传输很耗电。相反,ALU很便宜,而且消耗很小的电能,占据空间也少。而且并行程序通常有数千个线程同时运行,大多数线程之间是相互独立的,如果每个线程的中间计算结果需要写回缓存甚至是主存,那将是巨大的开销。
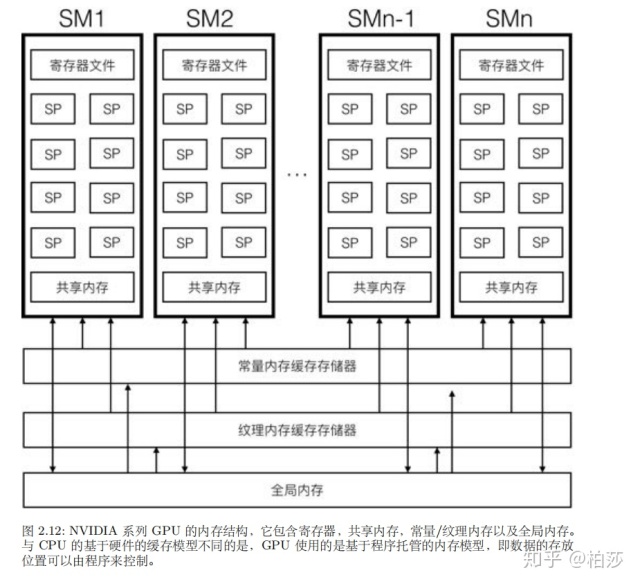
GPU内内存有四种,寄存器,共享内存,常量/纹理内存以及全局内存。

GPU的主存称为全局内存,这是因为GPU和CPU都可以对其进行写操作。例如顶点数组,纹理数据,都会通过CPU传输到GPU全局内存中。因为GPU内核函数访问全局内存比较慢,所以可以先把中间数据保存在执行单元本地,等到内核函数执行完毕再将本地数据写回到全局内存。
常量以及纹理内存其实是全局内存的一种虚拟地址形式,GPU并没有特殊保留的常量纹理内存,但是它能够提供高速缓存,而且他们都是只读内存。常量内存可以被缓存到常量内存缓存存储器,纹理内存可以被缓存到纹理内存缓存存储器,这些缓存通常是L1级缓存,速度会快一些。但对于数据不集中或者数据利用率不高的内存访问,尽量不用使用常量内存。纹理内存可以提供基于硬件的线性插值功能,而且可以根据数组索引自动处理边界条件,而不需要分支的引入。共享内存位于SM附近的L1高速缓存,延迟很低,但速度只有寄存器的1/10左右。

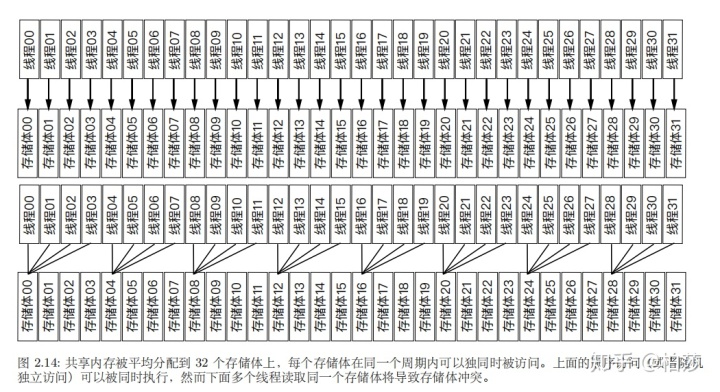
和CPU不同,GPU的每个SM有一个巨大的寄存器文件,它通常包含上千个寄存器。GPU的寄存器和CPU不同,CPU的寄存器在执行执行完后会把数据自动写入到缓存,然后缓存系统会广播更新多处理器架构中的其他处理器缓存。然而GPU并不会这么做,写入到寄存器中的数据会一直留在寄存器中,直到以后新的数据写入或者当前线程执行完毕自动退出,寄存器数据被重置。例如在一个着色器程序,只有最后才需要将结果写回到全局内存。那么如果变量太多了怎么办呢,所以你会发现shader写的计算代码太多会提示错误,寄存器数量不足。同时每个SP线程拥有自己独立的寄存器,可以避免切换线程时候导致寄存器数据的换进换出。

前面提到,CPU主要通过缓存来减少延迟,而在GPU中,则使用了延迟隐藏技术。在GK210/110架构中,每个SMX有192个SP,每个SMX可以分配高达2048个线程,就是说每个时钟周期有192个线程在执行计算的时候,还有2000个线程正在从内存中获取数据。
而且这种技术还可以用到GPU从cpu获取数据。
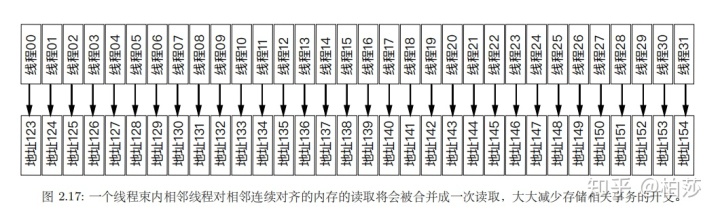
当连续的线程项全局内存发起数据请求,而且请求的内存块是连续对齐时,这些线程的多个内存请求会被合并成一个。
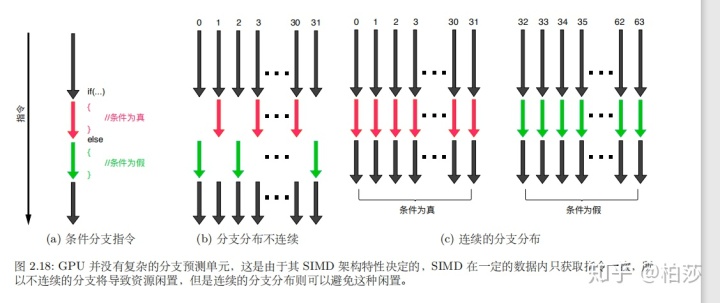
对于分支指令,GPU在执行完分支的一个后会接着执行另一个分支。当程序中包含分支指令时,如果一个线程束内的分支分布不是连续的,那么就会导致部分线程处于空闲状态。更糟糕的时,这样会导致线程无法将计算资源切换到其他线程束执行。不过在指令层面,硬件的调度是基于半个线程束,只要我们能够将半个线程束中连续的16个线程束划分到同一分支中,那么硬件就能够同时执行分支结构的两个不同条件的分支块。
就到这里啦,这次主要是对文章的一些摘要吧,详细内容建议去看原文哈。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









