






 B+树作为数据库索引的一种高效结构,通过优化B-树的特性,实现更快的范围查询。B+树所有数据只存在于叶子节点,叶子节点间用指针链接,从而减少了磁盘IO次数,提高了查询性能。此外,B+树的查找、插入和删除操作也具有明显优势,特别适合大数据量的范围查找。
B+树作为数据库索引的一种高效结构,通过优化B-树的特性,实现更快的范围查询。B+树所有数据只存在于叶子节点,叶子节点间用指针链接,从而减少了磁盘IO次数,提高了查询性能。此外,B+树的查找、插入和删除操作也具有明显优势,特别适合大数据量的范围查找。
既然前面提到B-树的查找性能已经很优秀了,为什么又出来了B+树?
试想B-树每查找一个元素都进行一次磁盘IO,尽管已经通过降低树高减少IO次数,但如果树高为n,要查找的元素恰好位于叶子结点,那么最快也要经过n次IO,如果数据库中存在上亿条记录,查询的性能可想而知。那么有没有更好的方法提高效率呢?B+树便产生了。
开始讲B+树之前,先 温习一下B-树的特性:
一个m阶的B-树具有以下特性:
1.根节点至少有两个孩子节点
2.每个中间节点包含k-1个元素和k个孩子节点,m/2<=k<=m
3.每个叶子结点包含k-1个元素,m/2<=k<=m
4.所有的叶子结点位于同一层
5.每个节点的元素从小到大排序,且其k-1个元素为k个孩子节点的值域分化
那么,我们再看以下B+树的特性:
B+树特性
一个m阶的B+树有以下特性:
1.有k个子树的中间节点包含k个元素(B-树为k-1),每个元素不保存数据,只保存索引,所有数据存在叶子结点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素
示例如下:
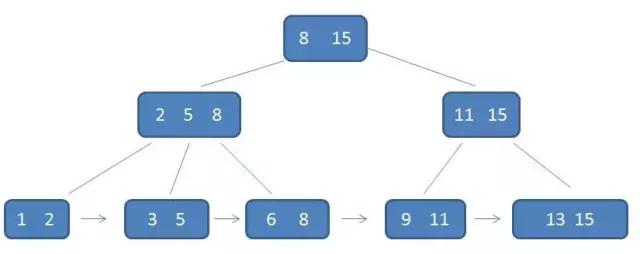
B+树结构示意图
与B-树想比,B+树变化很大,不仅子孩子包含父节点的元素,每个节点包含的元素为k个之外,叶子结点之间有指针指向,从小到大依次排列。
卫星数据
卫星数据:在数据库中多指某一行记录
这点也是B+树高效率的重要保证,我们先看一下B-树和B+树卫星数据的位置:

B-树的卫星数据跟随元素
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









