



“Java进程咋又突然没了?还没任何报错,都好几天了好奇怪啊。” 上午刚上班不久,旁边的同事就遇到了棘手的技术问题。大概打听下,原来是某个Java应用在执行某个耗时的定时任务的过程中,大概率进程会突然退出,而且应用日志、中间件日志都找不到任何异常。听起来还挺有意思,我默默地登上了出问题的docker容器。
0x01 OOM killer
登上机器后,查看应用和中间件日志,确实没有看到问题。我怀疑是JVM OOM了但没有配置输出,正想加上OOM时的堆栈输出参数,但发现应用启动命令已经包含类似的参数:-XX:+HeapDumpOnOutOfMemoryError -XX:ErrorFile=./hs_err_pid.log -XX:HeapDumpPath=./java_pid.hprof。 看来从应用层面查不到什么了,那就再看看系统日志吧。 使用dmesg -T | grep java查看系统日志
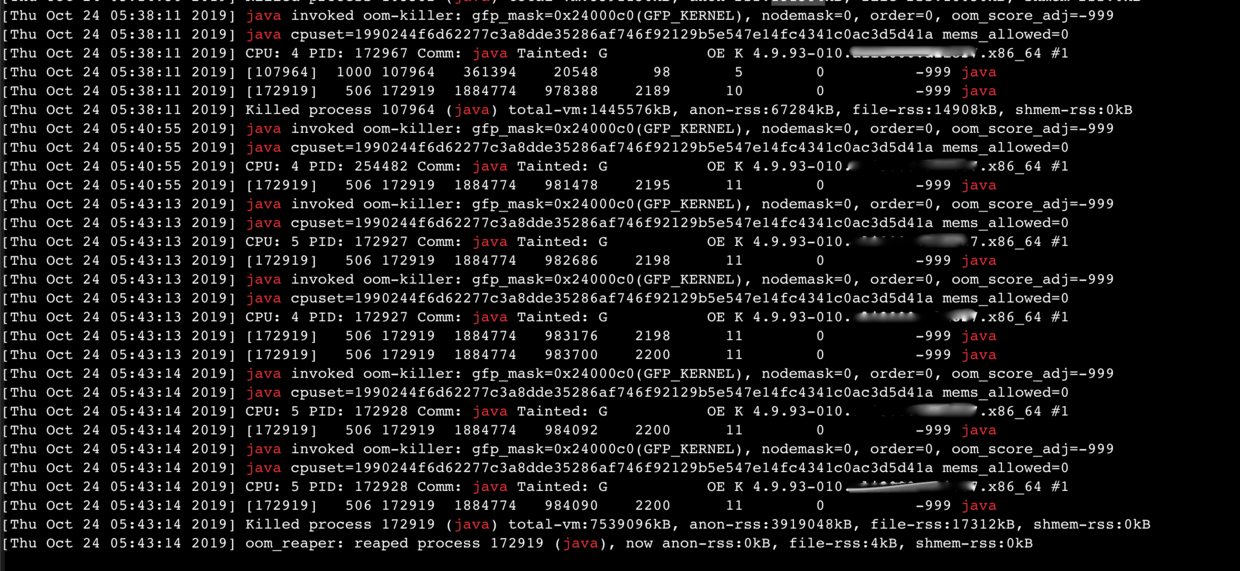 果然,从dmesg倒数第二行返回的信息来看,确实是由于oom导致的,但是这里的oom并非JVM的oom,而是Linux系统的oom。 >Killed process xxx(java), total-vm:7539096kB, anon-rss:3919048kB file-rss:17312kB, shmem-rss:0kB。
果然,从dmesg倒数第二行返回的信息来看,确实是由于oom导致的,但是这里的oom并非JVM的oom,而是Linux系统的oom。 >Killed process xxx(java), total-vm:7539096kB, anon-rss:3919048kB file-rss:17312kB, shmem-rss:0kB。
在这台物理内存为4GB的机器上,
`total-vm`是已经分配给java进程的虚拟内存数量(7539096kb=7.02GB)
`anon-rss`是java进程物理内存使用量(3919048kB=3.65GB)
`file-rss`是java进程映射到设备或文件系统的使用量(17312kB=16.51MB)
网上已经有很多介绍Linux oom killer的文章了,这里只简单概括:Linux系统在分配物理内存时,如果内存不足(什么时候不足?)oom killer会选择oom score得分最高的进程杀掉以释放内存。
0x02 JVM OOM vs. Linux OOM
看起来问题很明确了,是Linux的oom killer杀掉了Java进程。但是我还是有个疑问,同样是OOM,为什么没有触发JVM的OOM呢?带着这个疑问,继续了解了Linux的内存分配机制。
0x02.1 overcommit与oom killer
以下简单说一下我的理解,真实分配机制要复杂的多。有不对的地方请大家指正。 Linux有一套虚拟内存机制,当进程向系统申请内存时,总体上系统可以有两种方式答复进程: a.检查是否真的还有足够的内存(实际值计算一般等于Swap+RAM*overcmmit_ratio)满足需求,如果有就满足分配,如果没有就以分配失败答复集成; b.不检查,直接分配。
这里的分配指的都是进程的虚拟内存地址的增长。这里的b叫做"Overcommit",也就是发生了超过系统可接受内存范围的分配。这里的b其实是基于一种乐观的估计,因为申请的内存不一定用到。但是一旦进程需要使用所能提供的实际内存时,就会导致OOM,此时oom killer就会通过排序oom score牺牲掉一个或多个得分最高的进程,以此来释放内存。
再强调一次理解Overcommit的关键点,内存申请不等于内存分配,内存使用时才真正分配。
0x02.2 JVM OOM
那么JVM的OOM呢?
>One common indication of a memory leak is the java.lang.OutOfMemoryError exception. Usually, this error is thrown when there is insufficient space to allocate an object in the Java heap. In this case, The garbage collector cannot make space available to accommodate a new object, and the heap cannot be expanded further. Also, this error may be thrown when there is insufficient native memory to support the loading of a Java class. In a rare instance, a java.lang.OutOfMemoryError may be thrown when an excessive amount of time is being spent doing garbage collection and little memory is being freed. 摘自Oracle内存泄露说明相关文章
简单来说,发生JVM OOM的原因有: Java堆内存不足,垃圾回收器不能给新对象腾地儿,堆也无法扩展(Java heap space); 本地内存不足以支持加载Java类(Metaspace or Perm); 不常见地,过长时间的垃圾回收没有释放多少内存也会导致OOM(GC Overhead limit exceeded)。 回头看看,其实是Linux系统把Java进程给“骗”了。当开启了允许overcommit的策略时,如果Java进程或其他任何进程申请了可能过多(超过系统能提供的)虚拟内存时,只要系统内存还足够使用,Java进程并不会发生OOM。而当Linux系统发现分配内存真的不够时,就会把oom score最靠前的Java进程悄无声息地干掉(kill -9)。
>Java老农:“爷,给俺批点地,俺要种瓜。” Linux老爷:“爷我高兴,给你4096亩地,随便耍!” Java老农种地中...1...2...4....1024... Java老农:“没有虫子骚扰太开心啦,我要这样到永...” Java卒 Linux老爷:“有没有人要地呀,老爷我有的是地啊!”
0x03 解决方案
分析完原因,其实有很多解决方案。
0x03.1 申请更大内存的机器
如果有资源,就先尝试最简单的办法吧。
0x03.2 优化代码
现在的机器一般都是容器或虚拟机上只要只跑一个应用,如果发生OOM,最根本的解决之道还是要回归到代码上。
0x03.3 禁止Overcommit
让系统在申请时就报错,保守也保险。及早暴露问题,及早进行修复。同时可以修改overcommit_ratio的值改变CommitLimit。 配置参见附录。
0x03.4 禁止OOM Killer杀掉关键的应用进程
对于一些多应用进程混用的机器,可以保护关键进程不被kill掉。 sudo echo -1000 > /proc/$pid/oom_score_adj
0x03.5 禁止OOM Killer
修改panic_on_oom参数可以关闭OOM Killer。玩玩还可以,线上系统不建议用,否则系统死给你看。
附录:
1 Linux的Overcommit的策略
可在/proc/sys/vm/overcommit_memory配置或查看。
>0:默认值。启发式策略,比较严重的Overcommit将不能满足,而轻微的Overcommit将被允许。另外,root能Overcommit的值比普通用户要稍微多些,一般为3%。 1:允许Overcommit,这种策略适合那些不能承受内存分配失败的应用,比如某些科学计算应用。(本文中涉及的系统就是开启的这个策略) 2:禁止Overcommit,在这个情况下,系统所能分配的内存不会超过下面的CommitLimit,计算方法为Swap + RAM * /proc/sys/vm/overcmmit_ratio,默认50%,可调整),如果这么多资源已经用光,那么后面任何尝试申请内存的行为都会返回错误,这通常意味着此时没法运行任何新程序。
2 查看已分配内存
grep -i commit /proc/meminfo
CommitLimit: 6201492 kB # 虚拟内存限定值
Committed_AS: 5770836 kB # 已分配内存,如果大于CommitLimit说明开启了允许Overcommit的策略
3 查看oom相关
# 进程oom得分,0不kill
cat /proc/{pid}/oom_score
# 进程oom调整兼容,计算时一般会以oom_score_adj替换
cat /proc/{pid}/oom_adj
# 用户打分调整。最小值-1000,将会禁止oom killer杀此进程。
#取值从-1000到1000,表示对最终得分的折扣到惩罚。
cat /proc/{pid}/oom_score_adj
参考资料:

















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









