





 本文介绍了两种优化链表性能的方法:1. 跳表,通过建立多级索引来实现快速查找,时间复杂度降低到O(logn);2. 散列表+链表,结合两者优点,实现O(1)的查找、插入和删除操作,并允许顺序遍历。跳表常用于Redis的有序集合,而散列表+链表则能有效解决LRU缓存淘汰策略的问题。
本文介绍了两种优化链表性能的方法:1. 跳表,通过建立多级索引来实现快速查找,时间复杂度降低到O(logn);2. 散列表+链表,结合两者优点,实现O(1)的查找、插入和删除操作,并允许顺序遍历。跳表常用于Redis的有序集合,而散列表+链表则能有效解决LRU缓存淘汰策略的问题。
链表是一种我们耳熟能详的数据结构,其重要性是不言而喻的。但是,由于链表本身的结构限制,其查找的复杂度为O(n)。而删除和插入操作,虽然,理论上是O(1),但实际上,你必须获得其前一个结点,这导致其复杂度变成了O(n)。那么,今天,我介绍两种方法去,提升链表的性能。
1.链表的变形:跳表。
跳表是一种我们不常见的数据结构,但由于其优秀的特性,在工业中,常常被用来代替红黑树,进行查找,插入和删除。Redis的有序集合就是用跳表来实现的。
跳表本质上是采用"二分"的思路来改造链表,所以这要求链表必须是有序的。对于传统的链表,即使,其是有序的,查找起来也需要O(n)的时间复杂度。所以,我们在链表增加索引,如下图所示:
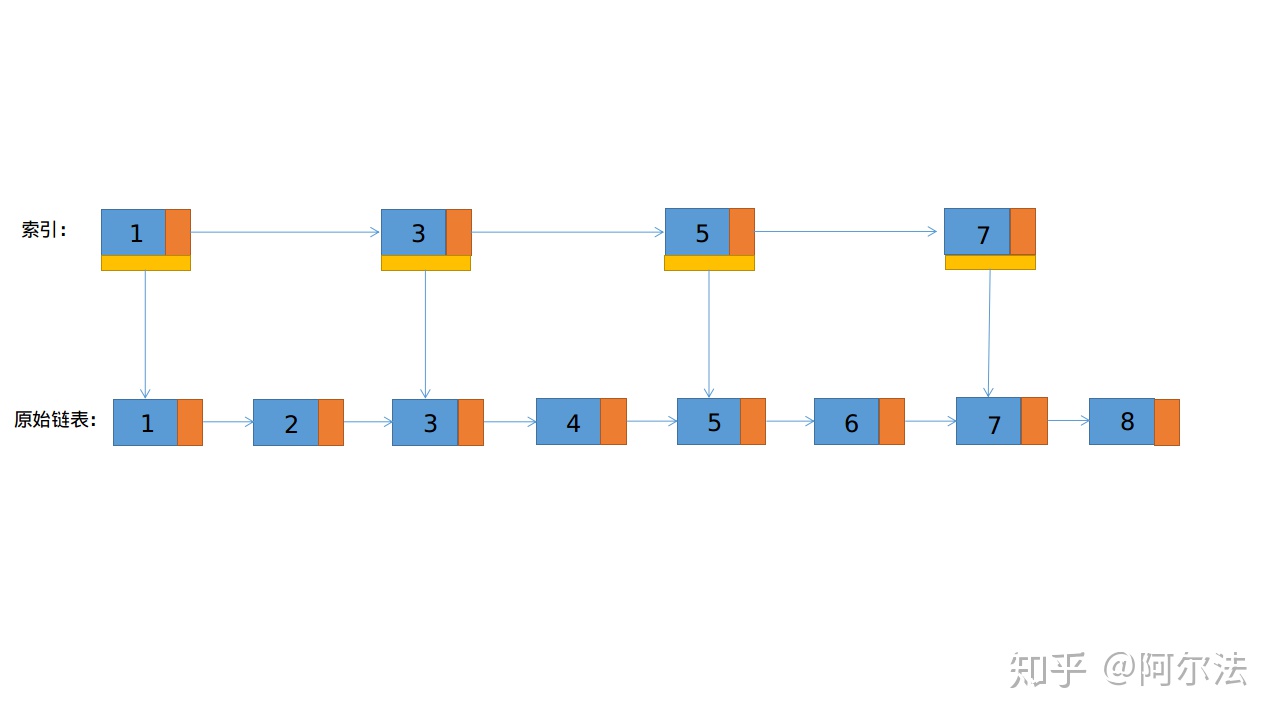
通过这种方式,当我们在查询6的时候,我们先通过索引,定位6在5之后,再通过指针,指向原始链表,得到6。通过这种方式,查找到6需要5步,原始需要6步。当然,这么看其实没有减少很多。所以我们可以继续向上加索引,如下图所示
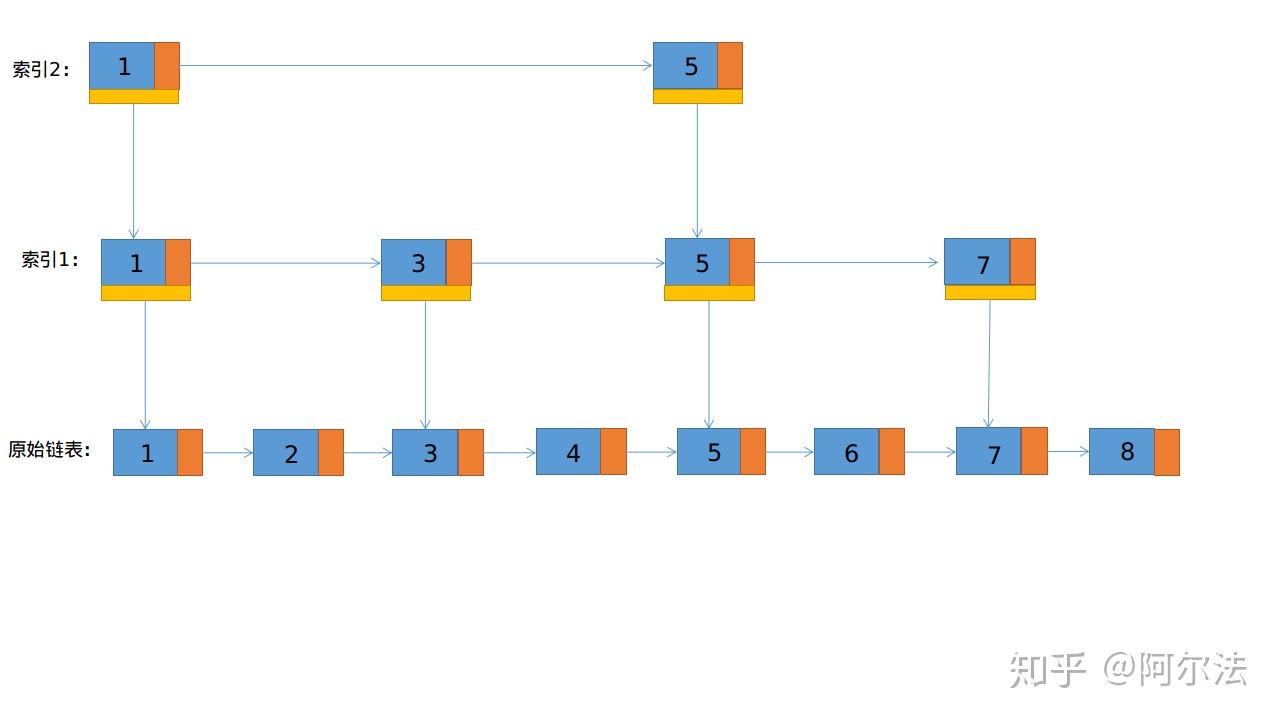
通过这种方式,在数据量很大的情况下,查找速度会有明显的的提升。不信,你可以动手画一下?
时间复杂度分析:
假设原始链表有n个结点,索引1为
空间复杂度:
从上可知,每层结点数为
这里提供一个我参考其他人的代码,给出的一个跳表的简单实现。
sccData/Data-structure-and-algorithm_selfgithub.com
2.散列表+链表
散列表解决散列冲突,通常有两种方法:开放地址法和链表法。所以,我们可以通过改造链表法,一方面弥补散列表无法按顺序遍历的缺点,另一方面弥补,链表无法随机访问的缺点。
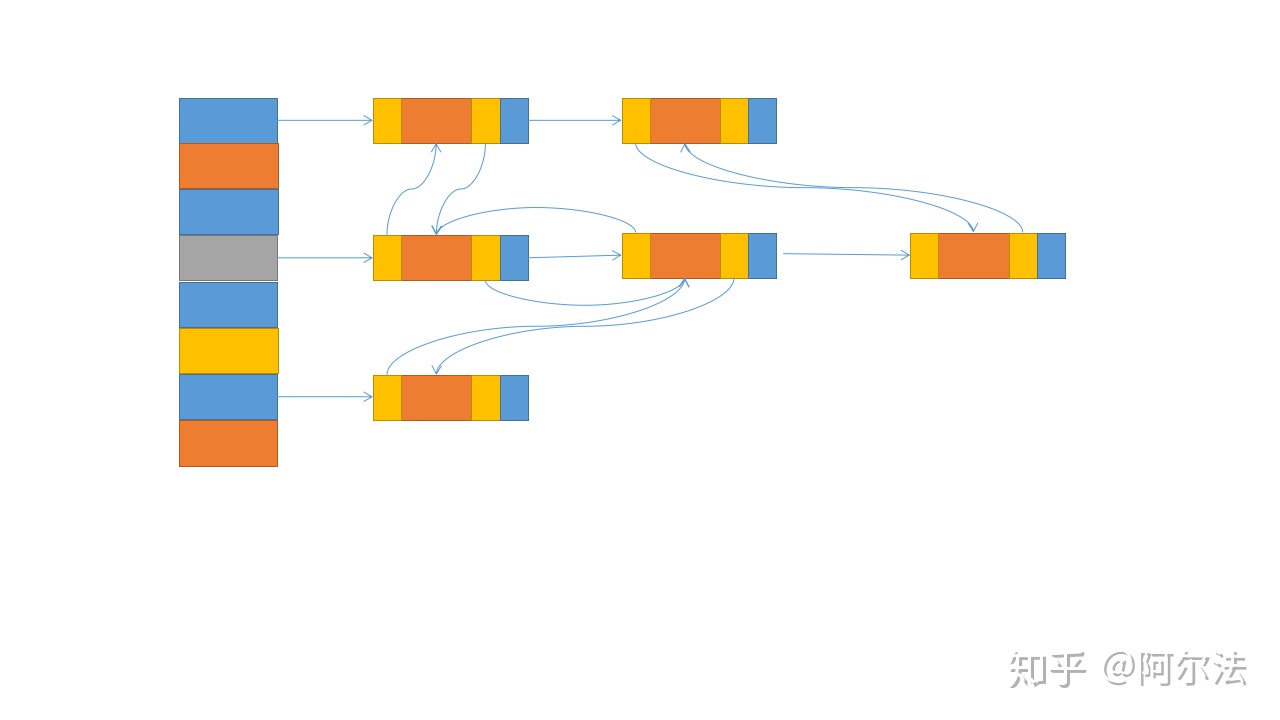
如上图所示,在链表法的基础上,使用双向链表把数据串起来,通过这种方式,我们可以把数据的查找,删除和插入的时间复杂度缩短到O(1)。另一方面,可以让散列表可以按某种顺序遍历。
下面,我们来看一个经典问题LRU淘汰缓存,在传统的单链表方式下,时间复杂度为O(n),通过上面介绍的散列表+链表的方式,可以将时间缩短到O(1)。
下面是leetcode关于这个题目的链接,你可以试一下。
https://leetcode.com/problems/lru-cache/leetcode.com

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









