





回到目录
聚合函数
聚合函数是用于汇总的函数,即将多行汇总为一行。有如下5个常用的聚合函数:
- COUNT:计算表的行数
- SUM:计算表中数值列中数据的和
- AVG:计算表中数值列中数据的平均值
- MAX:求表中任意列的最大值
- MIN:求表中任意列的最小值
COUNT的用法:
-- 例如
若将包含null的列作为count的参数,则count(列名)得到的结果是不包含null的行数。但count(*)例外,它不会排除null。
以列名为参数时,sum(列名)也一样,计算的时候会把null排除在外。
同理,avg(列名),求的该列平均值,是分子分母都排除了null后计算出来的结果。
max和min,求最大最小值,几乎适用于所有数据类型。而sum和avg只适用于数值类型。
同时使用DISTINCT和聚合函数删除重复值
-- 例如
对表进行分组的GROUP BY子句
SELECT 若表中有三种类别的物品,分别是衣服、厨房用具、办公用品,总共8行记录,其中衣服2行,厨房用具4行,办公用品2行,则上述语句得到结果为:
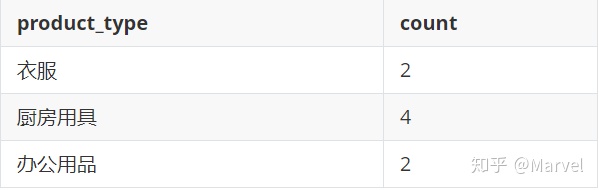
GROUP BY后面的参数称为聚合键,是表分组的依据。
使用GROUP BY时,null也会被视为一组,会在结果中以空白的形式出现。
书写顺序与执行顺序
截至目前学习的语句中,有如下书写顺序:
select -> from -> where -> group by
书写顺序不能乱。
同样重要的是执行顺序:
from -> where -> group by -> select
书写顺序和数据库内部的执行顺序并不相同。
同时使用WHERE和GROUP BY
-- 例如
根据上面提到的执行顺序可知,会先执行where语句对表格中的记录进行“过滤”,然后再对剩下的记录执行group by。
使用聚合函数和GROUP BY时的注意事项
- 使用了聚合函数的select后面的参数只能有三种情况:
- 聚合键
- 聚合函数
- 常数
因此使用聚合函数时,以上三种以外的情况不能出现在select后面。
- group by后不能书写列的别名。
因为别名是在select子句中定义的,而根据执行顺序,select在group by之后执行,因此执行到group by时,select中的别名此时数据库系统还不知道。
- group by语句结果的显示顺序是随机的。
- 不能在where子句中使用聚合函数。
只有select、having和order by子句中能够使用聚合函数。
DISTINCT和GROUP BY
有时候,distinct和group by都可以实现删除重复数据的功能。考虑如下语句:
-- distinct
上述两段代码得到的结果是一样的,而且都会把null作为一个独立的结果返回(对distinct来说,null也是一种类别),执行速度也差不多。那么该如何选择呢?
答案很简单,如果只是单纯地想删除重复数据,使用distinct足矣;而想对表进行分组并计算汇总结果时,则使用group by。如果不打算分组并计算汇总结果,却使用了group by来单纯地删除重复数据,则在逻辑上容易引起他人的误解。
能为聚合结果指定条件的HAVING子句
说到指定条件,很容易想到where,但where只能指定记录(行)的条件,不能用来指定分组后组的条件。而having则是可以对组指定条件的子句。语法如下:
SELECT 显然,如果不使用having,行数不是2的组及其行数也会被提取出来。
书写顺序与执行顺序
增加了having子句后书写顺序为:
select -> from -> where -> group by -> having
执行顺序为:
from -> where -> group by -> having -> select
HAVING子句的构成要素
与包含group by的select子句一样,having后面的参数也只能是以下三种情况:
- 聚合键
- 聚合函数
- 常数
WHERE与HAVING
有时候,where与having都可以实现在group by分组后指定条件。但是上文提到过where子句中不能使用聚合函数,那可以使用什么来指定条件呢?
答案是聚合键。group by后的where虽不能使用聚合函数指定条件,但可以使用聚合键。这样一来,可以完成和having一样的功能。考虑如下语句:
-- where
可以发现如果要对分组后的组指定条件,且该条件与聚合键相关,则where和having均能满足需求。但是更推荐将聚合键相关的条件写在where中,理由有两个:
- 理解容易。where的功能:指定行(记录)的条件;having的功能:指定组的条件。聚合键对应的条件应该属于行的条件,聚合函数对应的条件则属于组的条件。
- 执行速度更快。这种情况下,where比having处理速度更快。因为使用分组后select子句中使用聚合函数往往会增加机器的负担,聚合操作的负担往往比较大,而如果使用了where,则在分组、聚合前就已经对表的行数进行了过滤(因为where执行顺序优于group by),行数少了,处理的负担自然就小了。如果使用的是having,则分组、聚合时的数据量会比使用where更多。
使用ORDER BY进行排序
select语句查询的结果中,记录的顺序是随机的,如果需要排序,则需要在末尾添加order by子句。
SELECT 若想指定降序排列,则需要在排序键后添加DESC关键字,升序则添加ASC关键字。还可以省略关键字,省略后则默认按升序排列。
还可以在order by后指定多个排序键。这样一来,会优先使用左侧的键排序,若还无法排出先后,再使用右侧的键。这时,ASC和DESC关键字则写在各自的排序键的后面。
现在来考虑一下关于null的排序,第2章提到过,不能对null使用比较运算符,既null不能被比较大小,自然也就无法被排序。因此,使用含有null的列作为排序键时,null会在结果的开头或末尾汇总显示(开头或是末尾取决于DBMS)。
排序键还可以使用不包含在select中的列,不仅如此,order by还可以使用聚合函数,就像之前提到的,select、having、order by中可以使用聚合函数。
-- 例如
书写顺序与执行顺序
增加了order by子句后书写顺序为:
select -> from -> where -> group by -> having -> order by
执行顺序为:
from -> where -> group by -> having -> select -> distinct -> order by
由执行顺序可知,select执行后才轮到order by,因此order by子句中是可以使用select中定义的别名的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









