





前言
爬虫程序分很多种,有指定区域 文字 图片 内容 爬取,有通过某引擎进行爬取大数据,下面简单的介绍下通过搜索引擎来进行关键词爬取数据
功能代码结构
1.主代码
2.配置文件
3.支持库
正文
先来看一下代码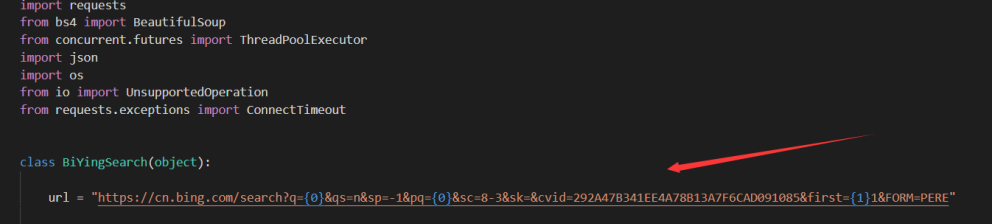
此处 必应调用的方式是,如下图:
这个是需要的参数,也是必要的,通过先搜索随机数之后取该接口 以及 参数 参数值
如果只是爬取这一个页面就不需要这样做了,但是我们爬取的是大数据,所以这个地方是要取 下一页的元素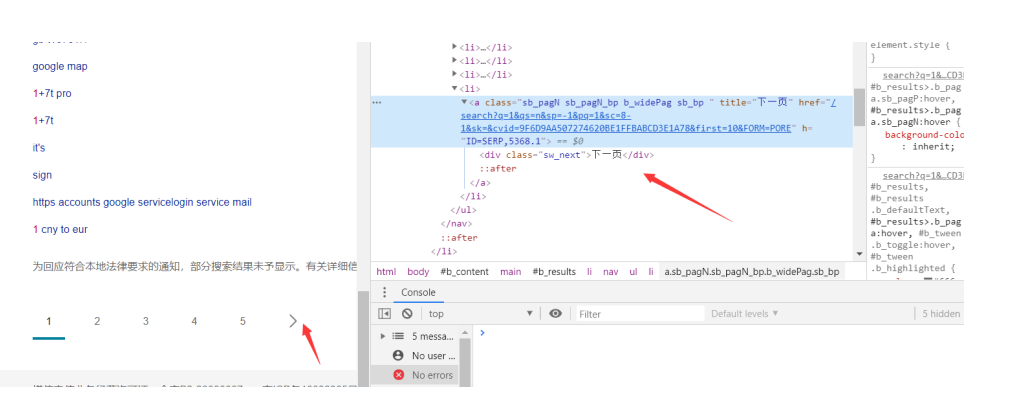
置响应代码,好让代码去自动处理下一页的关系。
继续看: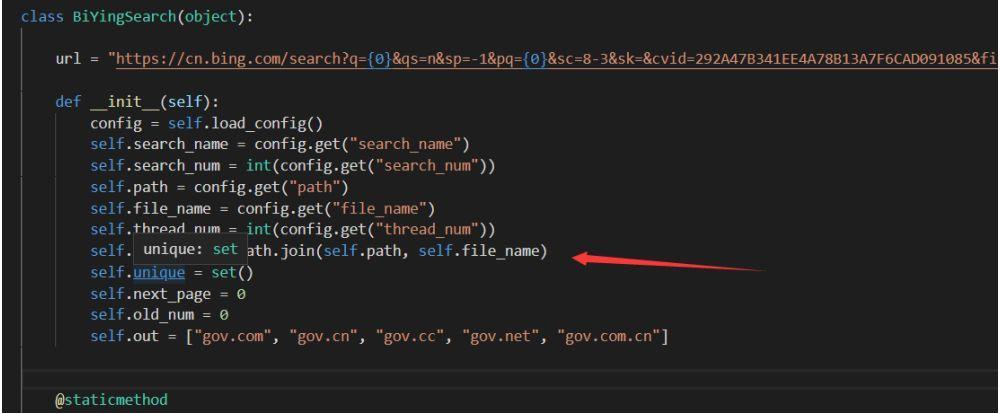
这个地方找的是 我们一个配置文件 ,在最开始我们都有定义Self.out ,相当于过滤,不对self.out 内的 内容进行搜索,这个地方就相当于在调用这个 config.json 这个配置文件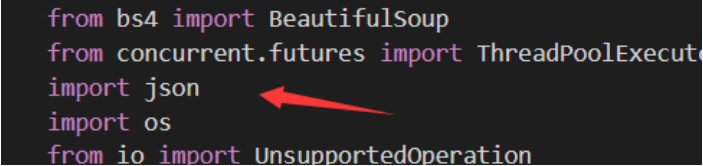
编写json配置文件: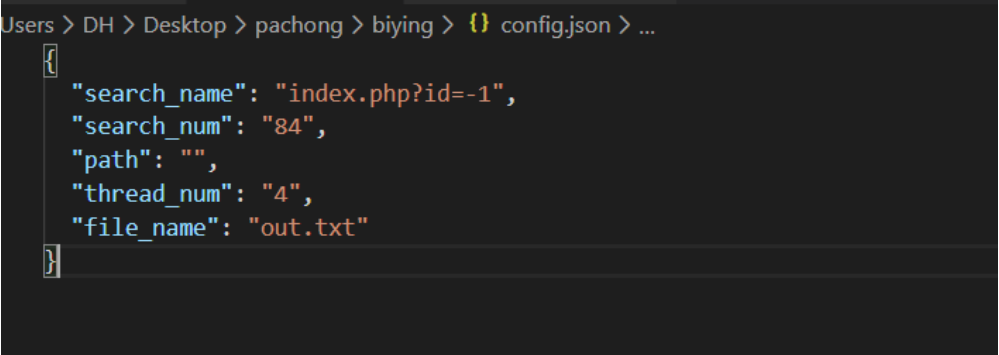
先总合上面,是不是这一个基本的模块就很清楚了,说的简单点 ,就是 我先定义 然后调用搜索接口,然后去调用并判断这个配置文件继续往下走!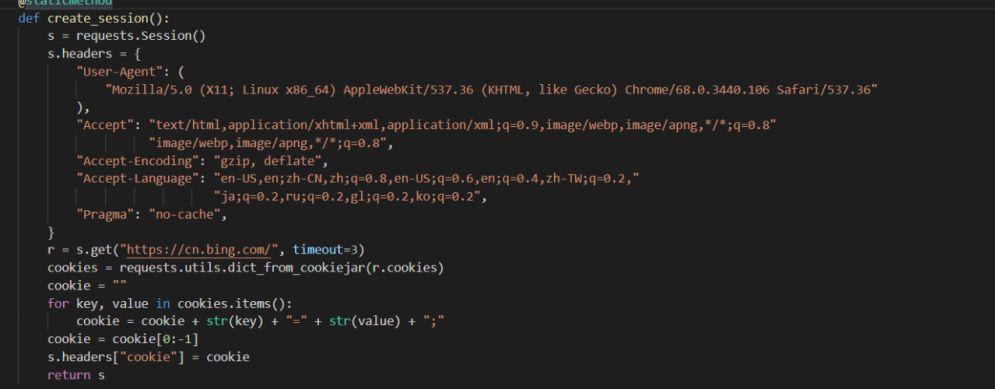
模拟请求头 ,这个就好比是一个标识,比如模拟手机的 谷歌的 火狐的 等等。
下面就是逻辑判断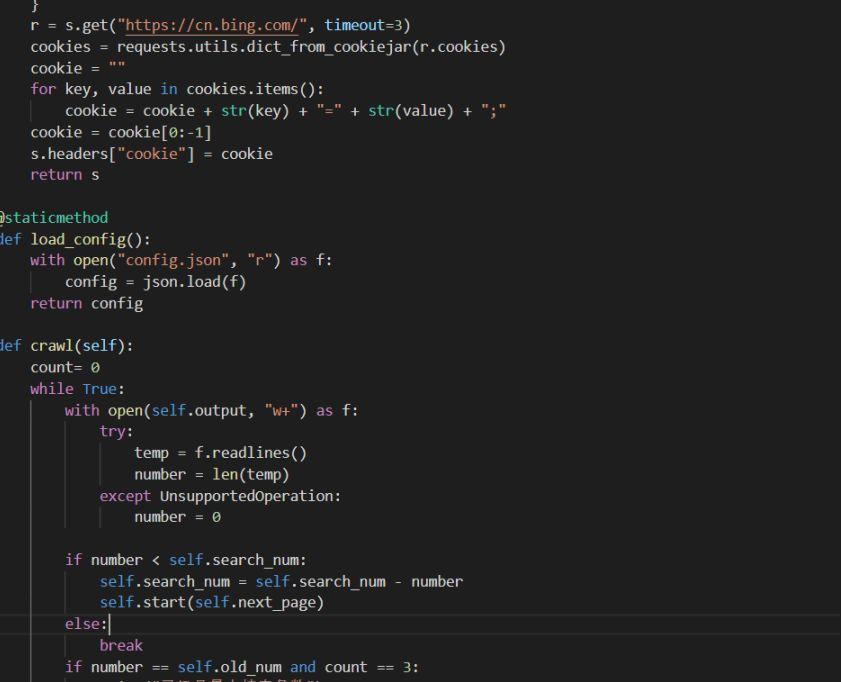
上诉总结:
其实很简单,我们把他集合并分解就是--该程序是通过必应搜索去进行搜索关键词,对搜索到的关键词取url 连接,结果并以txt 文本的方式去进行保存,我们所需要的是在 config.json 这个配置文件里面填写想要的爬行的关键词代码简单阐述:先定义需要使用的函数 ,通过函数去进行判断 配置文件,并模拟 inter 请求,去进行进行之后,使用函数对其进行判断所爬出的结果,取域名地址,保存到文本进程完结
相关代码:
其实我们只要注意以下几点,就可以完全做到编写简单的爬虫程序:
1:程序框架 (制定程序框架,要知道这个程序是做什么的 需要什么东西) 2:按需编写 (先对其进行定义,根据所定义的去进行编写,每定义一个,编写一个,这样会减少错误率)我们的Python学习扣②QUN:⑧⑤⑤-④零⑧-⑧⑨③
成长离不开与优秀的同伴共同交流,如果你需要好的学习环境,好的学习资源,这里欢迎每一位热爱Python的小伙伴,与你分享互联网人才需求以及怎么从零基础学习好python,和学习什么内容。

















 1624
1624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









