





第四次作业
作业一
1)要求:Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
2)思路:
使用scrapy框架,编写item类包含所需的数据、spider类、pipelines文件,设置settings文件,运行run文件。
使用mysql,安装后,使用pymysql进行pycharm和mysql的连接。(创建connection、获取cursor、增删改处理数据,关闭cursor 关闭connection)
使用Navicat for MySQL,连接MySQL,在其中通过命令行创建books表(其中的属性问题的类型必须要正确设置)

之后,常规的爬虫操作
3)代码:
items.py
import scrapy
class BookItem():
title = ()
author=()
date=()
publisher=()
detail=()
price=()
class P1Item():
# define the fields for your item here like:
# name = ()
pass
mySpider.py
import scrapy
from p1.items import BookItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class MySpider():
name = "mySpider"
key = 'python'
source_url=''
def start_requests(self):
url = "?key="+MySpider.key
yield scrapy.Request(url=url,callback=)
def parse(self, response):
try:
dammit = UnicodeDammit(, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = ("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = ("./a[position()=1]/@title").extract_first()
price =("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = ("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date =("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = ("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = ("./p[@class='detail']/text()").extract_first()
# detail有时没有,结果None
item = BookItem()
item["title"] = () if title else ""
item["author"] = () if author else ""
item["date"] = ()[1:] if date else ""
item["publisher"] = () if publisher else ""
item["price"] = () if price else ""
item["detail"] = () if detail else ""
yield item
link=("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
if link:
url=(link)
yield scrapy.Request(url=url, callback=)
except Exception as err:
print(err)
mpipelines.py
import pymysql
class BookPipeline(object):
def open_spider(self,spider):
print("opened")
try:
(host="",port=3306,user="root",passwd="mysql",db="hsddb",charset="utf8")
()
("delete from books")
self.opened = True
= 0
except Exception as err:
print(err)
self.opened=False
def close_spider(self, spider):
if self.opened:
self.con.commit()
()
self.opened=False
print("closed")
print("总共爬取",,"本书籍")
def process_item(self, item, spider):
try:
"""
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
"""
if self.opened:
("insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values(%s,%s,%s,%s,%s,%s)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
+=1
except Exception as err:
print(err)
return item
settings.py
添加以下命令
ITEM_PIPELINES = {
'': 300,
}
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())
4) 结果:
爬取结果:
数据库显示: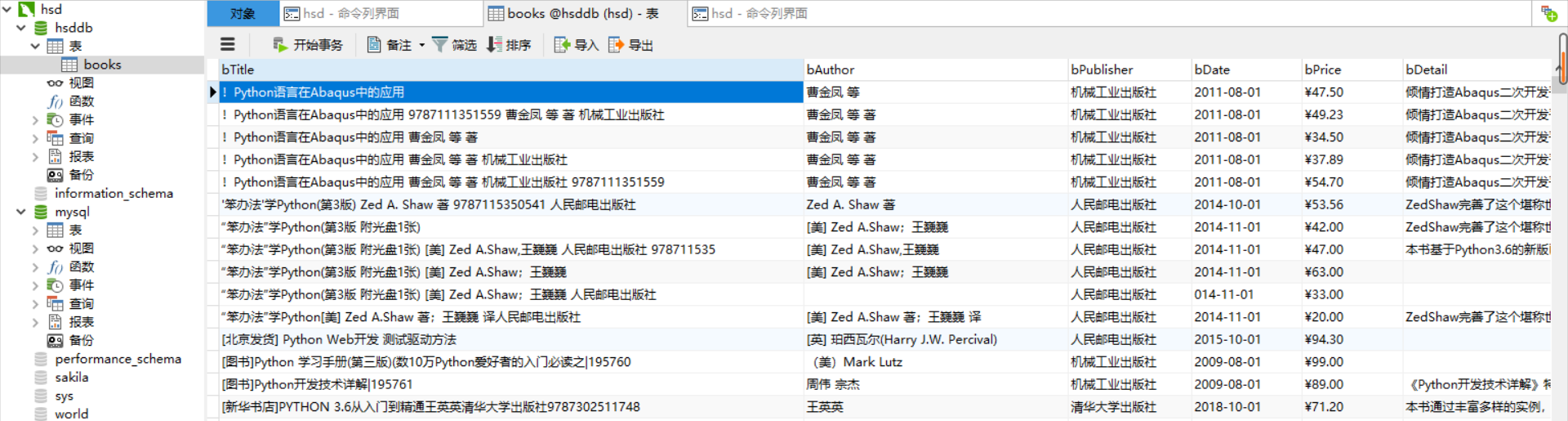
5)心得:
1.实验过程中,遇到的第一个坎是安装MySQL,过程中遇到需要安装MicrosoftVSc++,发现是磁盘中的package cache文件无法打开,可能是以前有什么误操作导致的失误,无法打开,冒着风险把它删掉,重新安装就可以了;之后可以顺利安装mysql。2.对scrapy框架的使用有更进一步的掌握,掌握了数据的序列化输出。3.学会MySQL的使用,以及在pycharm中使用pymysql库的调用。
作业二
1)要求:Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
2)思路:
因为此次爬取的网站是动态显示数据的,因此,需要使用selenium获取真正所需的HTML数据,才能使用Xpath爬取。
3)代码:
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class StockItem():
count = ()
id = ()
name = ()
new_price = ()
price_range = ()
change_amount = ()
turnover = ()
turnover_amount = ()
amplitude = ()
max = ()
min = ()
today = ()
yesterday = ()
pass
class P2Item():
# define the fields for your item here like:
# name = ()
pass
stockSpider.py
import scrapy
from p2.items import StockItem
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
import time
class stockSpider():
name = 'stockSpider'
start_urls = ['']
def parse(self, response):
# 创建浏览器对象
chrome_options = Options()
('--headless')
('--disable-gpu')
driver = (chrome_options=chrome_options)
(10)
("")
"""
html = driver.page_source
soup = BeautifulSoup(html, "lxml").prettify()
"""
blocks = ("//table[@id = 'table_wrapper-table']/tbody/tr")
for block in blocks:
item = StockItem()
item["count"] = ("./td[position()=1]/text()").extract_first()
item["id"] = ("./td[position()=2]/text()").extract_first()
item["name"] = ("./td[position()=3]/text()").extract_first()
item["new_price"] = ("./td[position()=5]/text()").extract_first()
item["price_range"] = ("./td[position()=6]/text()").extract_first()
item["change_amount"] = ("./td[position()=7]/text()").extract_first()
item["turnover"] = ("./td[position()=8]/text()").extract_first()
item["turnover_amount"] = ("./td[position()=9]/text()").extract_first()
item["amplitude"] = ("./td[position()=10]/text()").extract_first()
item["max"] = ("./td[position()=11]/text()").extract_first()
item["min"] = ("./td[position()=12]/text()").extract_first()
item["today"] = ("./td[position()=13]/text()").extract_first()
item["yesterday"] = ("./td[position()=14]/text()").extract_first()
print(item["name"])
yield item
driver.close()
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class StockPipeline(object):
def open_spider(self,spider):
print("opened")
try:
(host="",port=3306,user="root",passwd="mysql",db="hsddb",charset="utf8")
()
("delete from stocks")
self.opened = True
= 0
print("successfully open")
except Exception as err:
print(err)
self.opened=False
def process_item(self, item, spider):
try:
if self.opened:
"""
insert into stocks (count,id,name,new_price,price_range,change_amount,turnover,turnover_amount,amplitude,max,min,today,yesterday
"""
("insert into stocks (count,id,name,new_price,price_range,change_amount,turnover,turnover_amount,amplitude,max,min,today,yesterday) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(item["count"], item["id"], item["name"], item["new_price"], item["price_range"], item["change_amount"], item["turnover"], item["turnover_amount"], item["amplitude"], item["max"], item["min"], item["today"], item["yesterday"]))
+= 1
except Exception as err:
print(err)
return item
def close_spider(self, spider):
if self.opened:
self.con.commit()
()
self.opened = False
print("closed")
print("共爬取", , "条数据")
settings.py
ITEM_PIPELINES = {
'': 300,
}
4)结果:
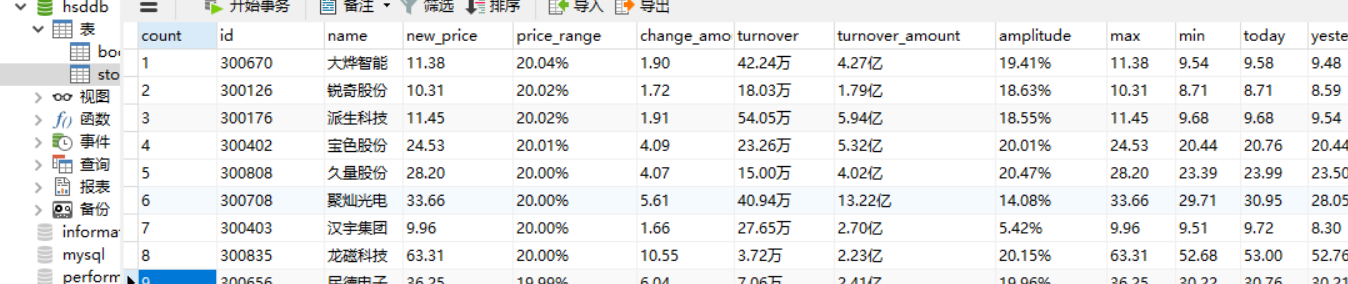
5)心得:
一开始使用的chrome浏览器版本是,找不到比这更高的85版本的chromedriver,因此下载了86版本的,匹配不了。所以卸载了chrome,重装版本,配置版本的chromedriver。中间卸载了chrome重装,除了删除安装目录文件外,还需要删除注册表里chrome相关记录,之后重装新版本即可。但是,重装了还是无法打开,尝试了几遍都不行,结果重启下电脑就可以了!但是,在命令行输入chromedriver还是显示86版本,在chrome安装目录下配置85版本都不行,最后发现是python安装目录下的scripts文件夹里还有一个驱动器,那个也需要替换。之后就可以顺利使用了。(不愧是我,踩坑大师 [泪目])
这次实验学会了selenium配合chrome驱动器的使用,同时对scrapy的使用愈加熟练。
作业三
1)要求:使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
2)思路:
- 爬取静态网页,直接使用BeautifulSoup配合scrapy的Selector使用。
- 数据库中创建表
- 爬取数据
3)代码:
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class currencyItem():
Currency = ()
TSP = ()
CSP = ()
TBP = ()
CBP = ()
TIME = ()
class P3Item():
# define the fields for your item here like:
# name = ()
pass
spider.py
import scrapy
from scrapy.selector import Selector
from p3.items import currencyItem
class spider():
name = "spider"
source_url = ''
def start_requests(self):
url = spider.source_url
yield scrapy.Request(url=url, callback=)
def parse(self, response):
try:
data = .decode("utf-8")
# print(data)
selector = Selector(text=data)
blocks = ("//div[@id='realRateInfo']/table[@class='data']/tr")
for block in blocks[1:]:
Currency= ("./td[position()=1]/text()").extract_first()
TSP= ("./td[position()=4]/text()").extract_first()
CSP= ("./td[position()=5]/text()").extract_first()
TBP= ("./td[position()=6]/text()").extract_first()
CBP= ("./td[position()=7]/text()").extract_first()
TIME= ("./td[position()=8]/text()").extract_first()
item=currencyItem()
item["Currency"]=() if Currency else ""
item["TSP"]=() if TSP else ""
item["CSP"]=() if CSP else ""
item["TBP"]=() if TBP else ""
item["CBP"]=() if CBP else ""
item["TIME"]=() if TIME else ""
yield item
except Exception as err:
print(err)
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class currencyPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="", port=3306, user="root", passwd="mysql", db="hsddb",charset="utf8")
self.cursor = self.con.cursor()
("delete from currency")
self.opened = True
= 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
()
self.opened = False
print("closed")
print("共爬取", , "条数据")
def process_item(self, item, spider):
try:
print(item["Currency"])
if self.opened:
+= 1
("insert into currency(id,Currency,TSP,CSP,TBP,CBP,Time) values(%s,%s,%s,%s,%s,%s,%s)",
(, item["Currency"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["TIME"]))
except Exception as err:
print(err)
return item
class P3Pipeline:
def process_item(self, item, spider):
return item
settings.py
ITEM_PIPELINES = {
'': 300,
}
4)结果:
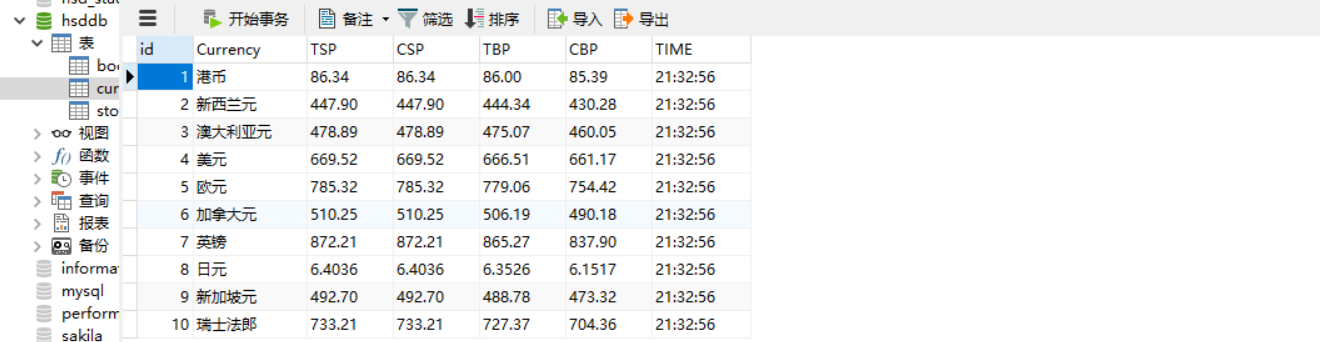
5)心得:
- 对使用scrapy中selector爬取静态网页更加熟练。
- 掌握了如何在python中使用数据库创建表及存储数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









