



 本文探讨了Spark SQL在2.4.x及以上版本中合并小文件的方法,包括INSERT...SELECT语句配合COALESCE或REPARTITION操作。在Spark 3.0中,启用自适应执行(spark.sql.adaptive.enabled=true)可以自动合并小文件,但还需要考虑其他相关参数如spark.sql.adaptive.coalescePartitions.enabled。文章指出,合理设置这些参数,特别是初始化分区数和阈值,能避免过多小文件并提高作业效率。作者提出了一种新的策略,以找到最佳的task启动数量平衡点。
本文探讨了Spark SQL在2.4.x及以上版本中合并小文件的方法,包括INSERT...SELECT语句配合COALESCE或REPARTITION操作。在Spark 3.0中,启用自适应执行(spark.sql.adaptive.enabled=true)可以自动合并小文件,但还需要考虑其他相关参数如spark.sql.adaptive.coalescePartitions.enabled。文章指出,合理设置这些参数,特别是初始化分区数和阈值,能避免过多小文件并提高作业效率。作者提出了一种新的策略,以找到最佳的task启动数量平衡点。
查看sparksql支持的参数:spark-sql set -v
需要注意这种方式对Spark的版本有要求,建议在Spark2.4.X及以上版本使用,示例: INSERT ... SELECT /*+ COALESCE(numPartitions) */ ... INSERT ... SELECT /*+ REPARTITION(numPartitions) */
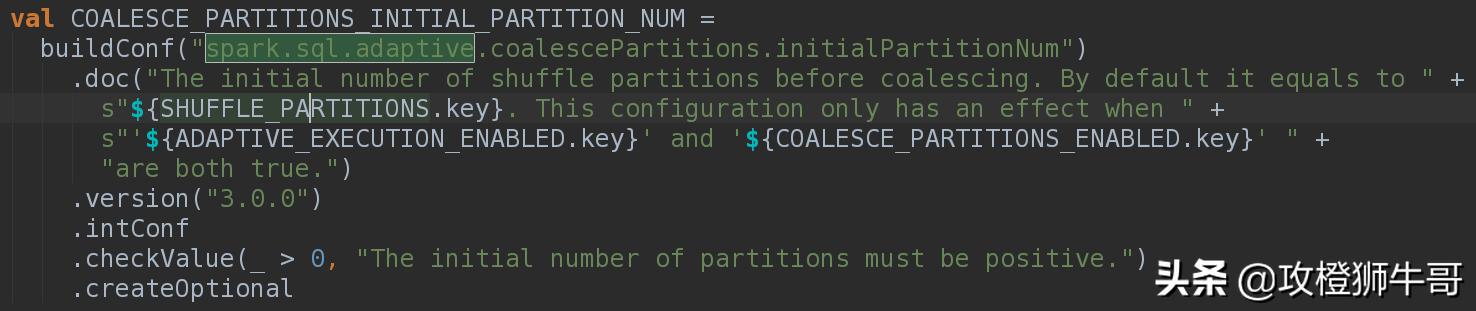
spark3.0支持自适应合并小文件,通过把参数spark.sql.adptive.enabled设置为true打开自适应。但是仅仅设置这个参数是不够,合并小文件还受其他参数影响。下面是我们生产的一个作业SQL,这个SQL执行完后这个表的每个分区都有800个文件,每个文件都是几M。当时就挺纳闷的,为什么都是800。于是去看生产spark的配置文件,发现如下关键参数

我们看看这个参数的描述:它和三个参数有关,这三个参数分别sparksql的默认分区数(spark.sql.shuffle.partitions,该值默认是200)、打开sparksql自适应参数spark.sql.adptive.enabled和分区合并小文件参数spark.sql.adptive.coalescePatitions.enabled有关。需要自适应和分区合并小文件都打开才生效。如果没有设置这个合并分区初始化分区数,那么合并小文件就按照sparksql的shuffle默认分区数启动。
测试SQL如下:
insert overwrite table dws_m.dws_dtfs_mbl_dpi_tag_hour_msk_d_test_20201022 partition (prov_id, day_id, biz_day_id, tag_flag) select a.mdn, a.meid, a.imsi, a.tag_id, substr(a.start_time, 9, 2) hour_range, count(*) all_cnt, sum(a.link_dur) link_dur, count(distinct a.start_time) m_cnt, sum(a.up_flow) up_flow, sum(a.down_flow) down_flow, a.type_id, b.is_holiday, a.refer, a.prov_id, a.day_id, a.biz_day_id, a.tag_flag from (select * from dwi_m.dwi_evt_blog_mbl_dpi_tag_msk_d where day_id = '20201020' and prov_id = '853' and tag_flag in ('url', 'app', 'site')) a left join dim.dim_date b on a.biz_day_id = b.day_id group by a.mdn, a.meid, a.imsi, a.tag_id, substr(a.start_time, 9, 2), a.type_id, a.prov_id, a.day_id, a.biz_day_id, a.tag_flag, b.is_holiday, a.refer;测试结果如下:
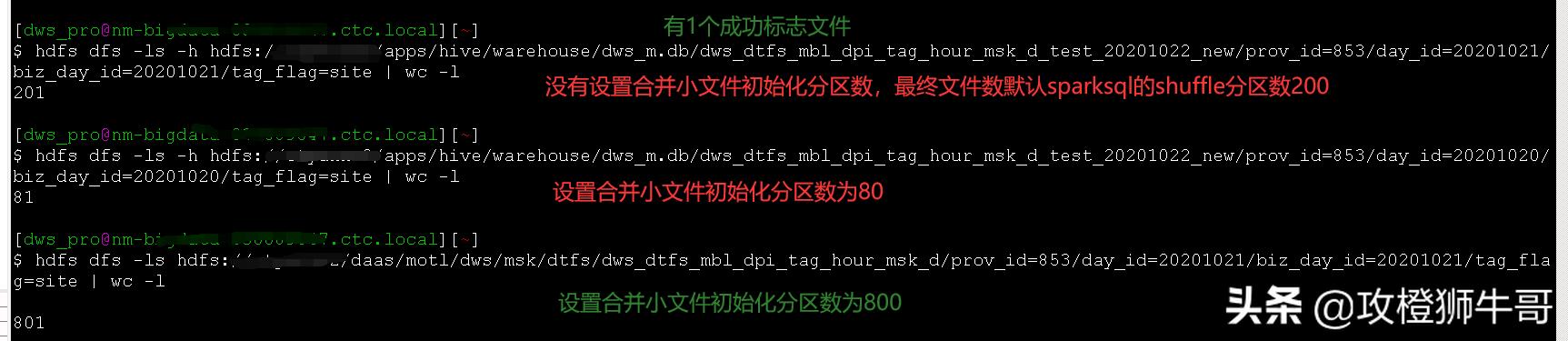
有shuffle时虽然合并达到了合并小文件的目的,但是个人认为这个还有待改进。我们看到合并小文件的阈值参数spark.sql.adaptive.advisoryPartitionSizeInBytes设置为200M了(和参数spark.sql.adaptive.shuffle.targetPostShuffleInputSize一样,这个默认值64M)。有合并小文件的最小分区数spark.sql.adptive.coalescePatitions.minPartitionNum。那么我们是否把spark.sql.adptive.coalescePatitions.initialPartitionNum改成spark.sql.adptive.coalescePatitions.maxPartitionNum参数,然后根据合并小文件的阈值spark.sql.adaptive.advisoryPartitionSizeInBytes和最大合并小文件分区数spark.sql.adptive.coalescePatitions.maxPartitionNum两者的最小值确定启动task数更合理呢?这样即不会导致初始化合并分区数太多导致小文件,又不会设置初始化分区数太少(会生成很大的文件数)而导致spark作业太慢
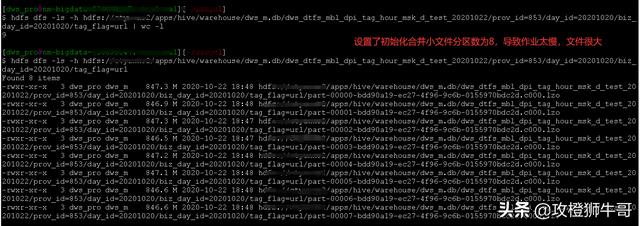
下面就是测试的一个极端情况

















 2732
2732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









