



Hive是Facebook实现的一个开源的数据仓库工具——
- Hive基于Hadoop实现,底层数据存放在HDFS中,计算(查询)使用MapReduce任务实现
- 将结构化的数据文件映射为数据库表,并提供HQL查询功能,将HQL语句转化为MapReduce任务运行
关于Hive的介绍,可以参考我之前的笔记。
Hive简介、基本架构与存储结构_大数据_机器学习,大数据-优快云博客blog.youkuaiyun.com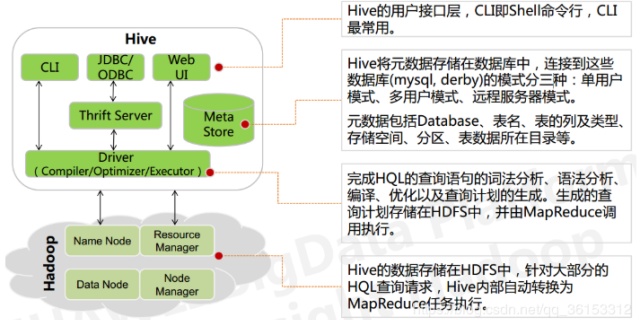
在实际应用中,我们主要通过编写HiveSQL来对数据进行查询等操作,本文介绍常用的HiveSQL如何转化为MapReduce任务,便于在编写SQL时写出更加高效的代码。
1. hive.fetch.task.conversion参数
在Hive中,有些简单任务既可以转化为MR任务,也可以Fetch抓取,即直接读取table对应的存储目录下的文件得到结果,具体的行为取决于Hive的hive.fetch.task.conversion参数。
在hive-default.xml.template中,可以找到这个参数描述如下:
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>- 当设置为none时,所有任务转化为MR任务;
- 当设置为minimal时,全局查找
SELECT *、在分区列上的FILTER(where...)、LIMIT才使用Fetch,其他为MR任务; - 当设置为more时,不限定列,简单的查找
SELECT、FILTER、LIMIT都使用Fetch,其他为MR任务。
默认情况下,使用参数more,本文也介绍参数为more时的SQL转化。
这里把SQL在命令行中运行验证,可以看到该SQL中SELECT指定列、包含WHERE、LIMIT子句,但没有转化为MR任务(若有会有相应的MapReduce提示,如后面的图中所示),说明为直接Fetch抓取结果。

2. 转化为MR任务的SQL
需要转化为MR任务的SQL通常会涉及到key的shuffle,比如JOIN、GROUP BY、DISTINCT等,此处介绍这三种任务的转化,示例使用的两个表如下:
page_view——
userinfo——

2.1 JOIN
JOIN任务转化为MR任务的流程如下:
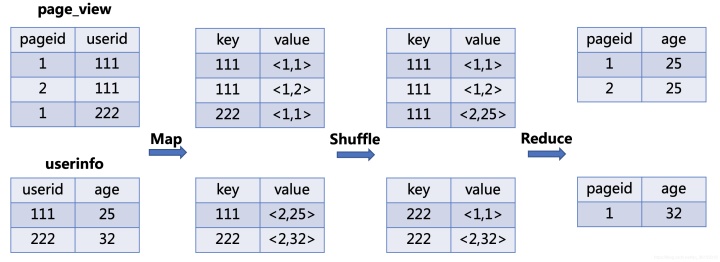
- Map:生成键值对,以
JOIN ON条件中的列作为Key,以JOIN之后所关心的列作为Value,在Value中还会包含表的 Tag 信息,用于标明此Value对应于哪个表 - Shuffle:根据
Key的值进行 Hash,按照Hash值将键值对发送至不同的Reducer中 - Reduce:Reducer通过 Tag 来识别不同的表中的数据,根据
Key值进行Join操作
编写SQL如下:
SELECT pageid, age
FROM page_view JOIN userinfo ON page_view.userid = userinfo.userid; 则转化后的MR任务流程如下图所示,其中键值对中value的第一个值为表的tag,表明数据属于那个表
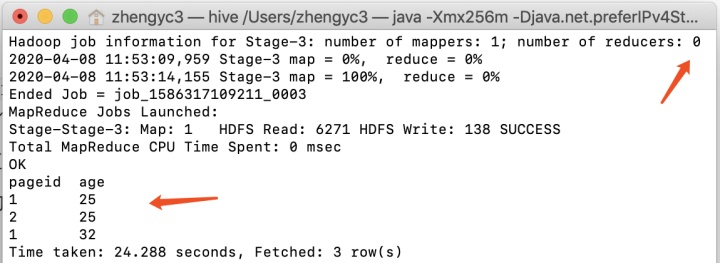
在Hive命令行工具中运行上述代码,结果如下,注意到reducer为0,原因是示例的表很小,Hive默认将其优化为mapjoin任务,关于mapjoin任务原理可以参考。
Hive调优策略--Fetch抓取 & 表的各种优化策略(mapjoin原理)blog.youkuaiyun.com
当表都较大时,则会按照上图所示流程进行MR任务。
2.2 GROUP BY
JOIN任务转化为MR任务的流程如下:
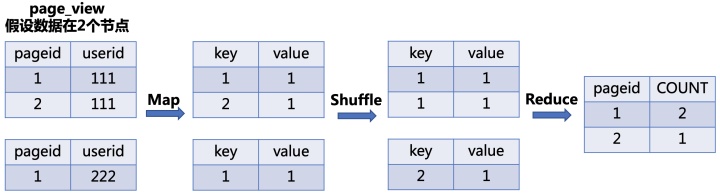
- Map:生成键值对,以
GROUP BY条件中的列作为Key,以聚集函数的结果作为Value - Shuffle:根据
Key的值进行 Hash,按照Hash值将键值对发送至不同的Reducer中 - Reduce:根据
SELECT子句的列以及聚集函数进行Reduce
编写SQL如下:
SELECT pageid, COUNT(1) as num
FROM page_view
GROUP BY pageid;则转化后的MR任务流程如下图所示:
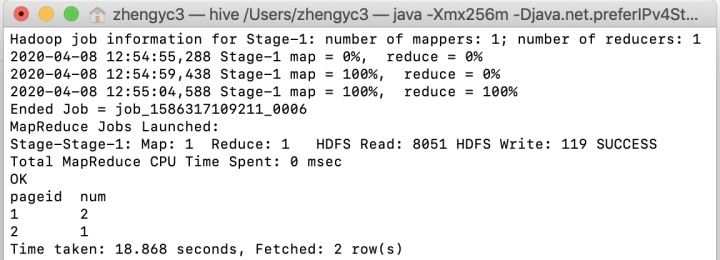
在Hive命令行工具中运行上述代码,结果如下,与上述过程一致。
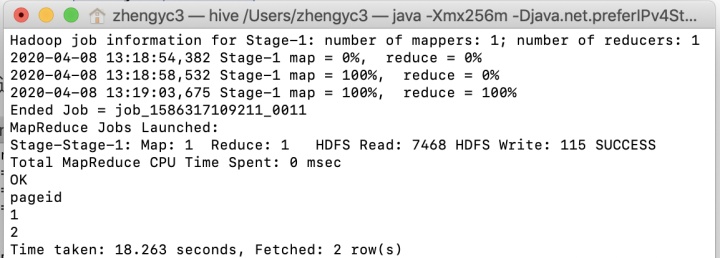
2.3 DISTINCT
相当于没有聚集函数的GROUP BY,操作相同,只是键值对中的value可为空。
SELECT DISTINCT pageid FROM page_view;在Hive命令行工具中运行上述代码结果如下:
Reference
- 《Hive用户指南》


















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









