






点击查看往期内容回顾
生物信息学初识篇——第一章:生物数据库
第二章:序列比对(1)
生物序列有自己的书写格式,而且格式很多。不同的处理软件会用到不同的格式,但是最常用的,大多数软件都识别的格式是 FASTA 格式。我们用一致度(identity)和相似度(similarity)这两个指标来定量描述序列有多相似。
一.替换记分矩阵
替换记分矩阵是反映残基之间相互替换率的矩阵。也就是说,它描述了残基两两相似的量化关系。比如图2.1 就是一个替换记分矩阵。矩阵中行和列分别是 20 种氨基酸,且两两之间有一个分值。根据这个分值就可以知道谁和谁相似,谁和谁不相似。替换记分矩阵有很多种。DNA 序列有 DNA 序列的替换记分矩阵,蛋白质序列有蛋白质序列的替换记分矩阵,两者不可混用。
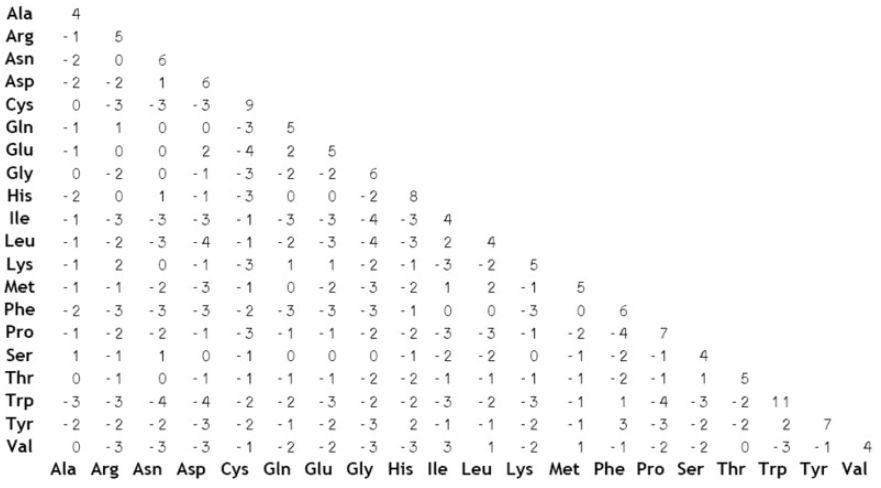
图 2.1. BLOSUM-62 替换记分矩阵
1、核酸序列的替换记分矩阵
DNA 序列的替换记分矩阵主要有三种。一个是等价矩阵(图2.2-1)。这个矩阵最简单.其中,相同核苷酸之间的匹配得分为 1,不同核苷酸间的替换得分为 0。由于不含有碱基的理化信息和不区别对待不同的替换,在实际的序列比较中很少使用,一般只用于理论计算。
另一种是转换-颠换矩阵(图2.2-2)。转换即嘌呤变嘌呤,嘧啶变嘧啶;颠换即嘌呤变嘧啶,或者嘧啶变嘌呤。大自然更倾向于接受嘌呤和嘌呤之间的替换,以及嘧啶和嘧啶之间的替换,而嘌呤和嘧啶之间的替换会导致不好的事情发生,这种替换大多在进化过程中已经被淘汰了。为了反映这一情况,转换-颠换矩阵中,转换的得分比颠换要高为-1 分,而颠换的得分为-5分。
还有一种叫 BLAST 矩阵。经过大量实际比对发现,如果令被比对的两个核苷酸相同时得分为+5 分,不相同为-4分,这时比对效果最好。这个矩阵广泛地被 DNA 序列比较所采用。

图2.2 DNA序列的三种替换记分矩阵
2、蛋白质序列的替换记分矩阵
蛋白质最常用的两种矩阵是PAM矩阵和BLOSUM矩阵。PAM矩阵基于进化原理。如果两种氨基酸替换频繁,说明自然界容易接受这种替换,那么这一对氨基酸替换的得分就应该高。PAM 矩阵是目前蛋白质序列比较中最广泛使用的记分方法之一。基础的 PAM-1矩阵反应的是进化产生的每一百个氨基酸平均发生一个突变的量值,由统计方法得到。PAM-1自乘n次,可以得到PAM-n ,表示发生了更多次突变。我们需要根据要比较的序列之间的亲缘关系远近,来选择适合的 PAM 矩阵。如果序列亲缘关系远,也就是说序列间会有很多突变,那就选 PAM 后面跟一个大数字的矩阵。如果亲缘关系近,也就是突变比较少,序列间大多数地方都是一样的,那就选 PAM 后面跟一个小数字的矩阵。
图2.3是 PAM250矩阵。对角线上的数值为匹配氨基酸的得分。其他位置上≥0 的得分代表对应的一对氨基酸为相似氨基酸,<0的是不相似的氨基酸。
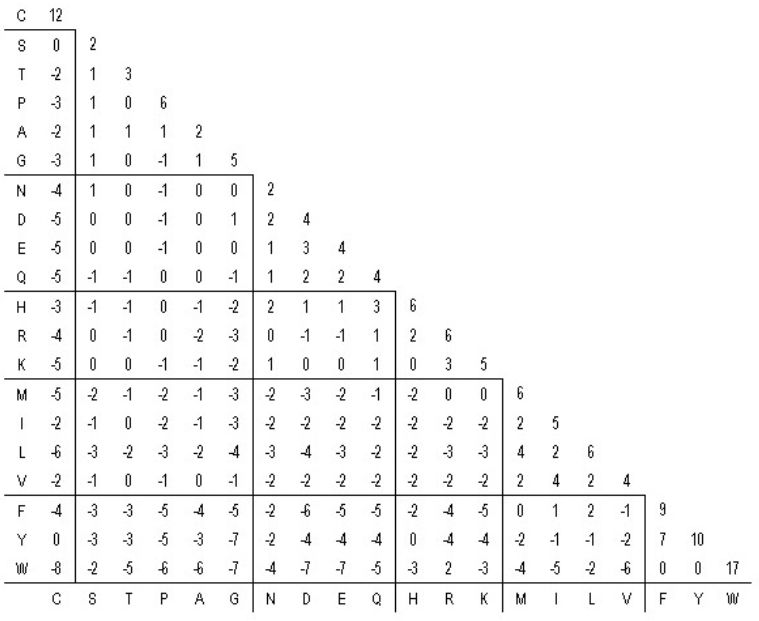
图2.3 PAM250 矩阵
BLOSUM 矩阵有和 PAM 矩阵相同的地方,也有不同的地方。相同的是,BLOSUM 矩阵后面也带有一个编号,有很多种 BLOSUM 矩阵。不同的是,BLOSUM 矩阵都是通过对大量符合特定要求的序列计算而来的。这点和 PAM 矩阵不同的。PAM-1 矩阵是基于相似度大于85%的序列计算产生的,也就是通过关系较近的序列计算出来的。那些进化距离较远的矩阵,如 PAM-250,是通过 PAM-1 自乘得到的。也就是说,BLOSUM 矩阵的相似性是根据真实数据产生的,而 PAM 矩阵是通过矩阵自乘外推而来的。和 PAM 矩阵的另一个不同之处是BLOSUM 矩阵的编号。这些编号,比如 BLOSUM80 中的 80,代表这个矩阵是由一致度≥80%的序列计算而来的。同理,BLOSUM62 是指这个矩阵是由一致度≥62%的序列计算而来的。因此,BLOSUM 后面跟一个小数字的矩阵适合用于比较相似度低的序列,也就是亲缘关系远的序列;而 BLOSUM 后面跟一个大数字的矩阵适合比较相似度高的序列,也就是亲缘关系近的序列。
图2.4是BLOSUM 62矩阵.样子和 PAM 矩阵差不多,但是里面的数值是不一样的。同样,≥0 的得分代表对应的一对氨基酸为相似氨基酸,<0 的是不相似的氨基酸。

图2.4 BLOSUM62 矩阵
总之,PAM1对应的氨基酸差异是1%,这是基础矩阵,由实际数据计算得出。而 PAM11 是由 PAM1 自乘 11 次得到的,他对应的氨基酸差异可不是 11%,而是大约在 10%左右(图2.5)。同样,PAM80 对应的差异也不是 80%,而是在 50%左右。如果你要比对的序列亲缘关系远,比如氨基酸差异在 80%左右,那就得选 PAM 自乘次数非常多的矩阵,适合的是 PAM246。但是现成的 PAM 矩阵也不是什么号的都有,只有几个关键号的。比如这个 PAM246 就没有,有的是 PAM250。

图2.5氨基酸差异与矩阵编号对照图
再来看BLOSUME。BLOSUME 后面的号和 PAM 刚好相反,因为它对应的是序列的相似度。差异在 80%左右意味着相似度在 20%左右,所以这个档次上的序列适合用的 BLOSUM 矩阵就是BLOSUM20。概括的说,PAM 后面的数体现的是序列的差异度,但不直接等于差异度,只是成对应关系而已;BLOSUM 后面的数体现是的序列的相似度并且直接等于相似度。所以我们看到,随着差异度的增大,适用的 PAM 矩阵后面的编号是增大的,而 BLOSUM 矩阵后面的编号是减小的(图2.5)。
进一步总结一下(图2.6),亲缘关系较近的序列之间的比较,用 PAM 数小的矩阵或BLOSUM 数大的矩阵;而亲缘关系较远的序列之间的比较,用 PAM 数大的矩阵或 BLOSUM数小的矩阵。对于关系较远的序列之间的比较,由于 PAM250 是通过矩阵自乘推算而来的,所以其准确度受到一定限制。相比之下BLOSUM 矩阵更具优势。对于关系较近的序列之间的比较,用 PAM 或 BLOSUM 矩阵做出的比对结果,差别不大。如果关于要比较的序列你不知道亲缘关系远近,那么就闭着眼睛用BLOSUM62 吧!

图2.6 序列亲缘关系远近与矩阵的选择
除了 PAM 和 BLOSUM 矩阵,还有两个蛋白质的替换记分矩阵。一个是遗传密码矩阵(图2.7),它是通过计算一个氨基酸转换成另一个氨基酸所需的密码子变化的数目而得到的。矩阵的值对应为据此付出的代价。如果变化一个碱基就可以使一个氨基酸的密码子转换为另一个氨基酸的密码子,则这两个氨基酸的替换代价为 1;如果需要 2 个碱基的改变,则替换代价为 2;再比如从蛋氨酸(Met)到酪氨酸(Tyr)三个密码子都要变,则代价为 3。遗传密码矩阵常用于进化距离的计算,它的优点是计算结果可以直接用于绘制进化树,但是它在蛋白质序列比对,尤其是相似程度很低的蛋白质序列比对中,很少被使用。
另一个疏水矩阵(图2.8),它是根据氨基酸残基替换前后疏水性的变化而得到的矩阵。若一次氨基酸替换导致疏水特性不发生太大的变化,则这种替换得分高,否则替换得分低。疏水矩阵物理意义明确,有一定的理化性质依据,适用于偏重蛋白质功能方面的序列比对。在这个矩阵里,氨基酸按照亲疏水性排列。前边是亲水的,后面是疏水的。
有了替换记分矩阵,就可以知道哪些氨基酸是相似的。比如下面这个例子里:
序列1:C LH K
序列2:C I H L
我们可以从替换记分矩阵中读出I和L相似,K和L不相似。因此,它们的相似度就是 2个相同的加上1个相似的,除以长度4,等于75%。
这是两个序列具有相同长度,如果两个序列的长度不相同,怎么计算它们的一致度和相似度呢?后面再做介绍。

图2.7遗传密码矩阵
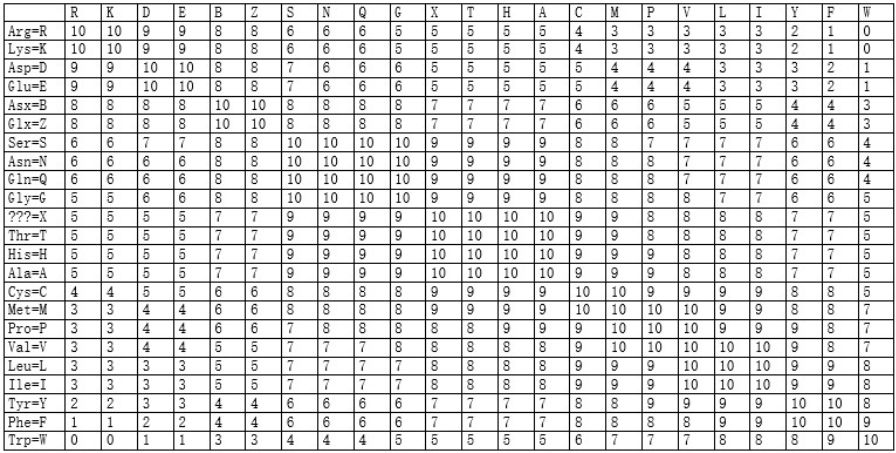
图2.8疏水矩阵
二.序列两两比较之打点法
1、打点法的用途
比较两个序列的方法有打点法和序列比对法。打点法是最简单的比较两个序列的方法,理论上可以用纸和笔来完成。如果要比较下面这两条序列:
Seq 1:THEFASTCAT
Seq 2:THEFATCAT
我们需要把序列 1 整齐的水平书写,然后把序列 2 整齐的竖直书写,然后依次横横竖竖的比较每一个位置上的残基。相同的话就在这个位置上打个点,不同话,什么也不干(图2.9)

图2.9 序列 1 和序列 2 的打点图
从这样一个打点矩阵上可以总结出一些东西来。首先,说是打点你也可以打叉。这就是做个标记,标记下这个位置上对应的两个残基是相同的。第二点发现,这个矩阵中绝大部分地方是没有点的,只有少数位置上有点。第三个发现,这个矩阵中打点打出了一条较为明显的对角线。在打点矩阵中,连续的对角线及对角线的平行线代表两条序列中相同的区域。这个矩阵中在主对角线位置上连续的红色的对角线说明这个位置对应的序列 1 的部分和序列 2 的部分是完全相同的,都是 THEFA。此外,跟红对角线平行的蓝色平行线和绿色平行线,同样指出了序列1和序列2中两条相同的序列。也就是序列1和序列2中对应位置的 TCAT,以及序列 1 和序列 2 中对应位置的 AT。由这三条线,我们找到了序列 1 和序列 2 中三条相同的子序列。最后,我们放眼全局,红色的线和蓝色的线加起来基本上构成了一条主对角线。由此我们可以得出结论:序列 1 和序列 2 是比较相似的两条序列。事实上,如果直接看一下这两条序列,确实是挺相似的。如果是风马牛不相及的两条序列,做出的打点矩阵里是不会出现对角线的,哪怕是模糊的对角线,也不会出现。比如,让序列 1 和序列 3 打点做出的打点图(图2.10)中,完全是散点,根本就没有连续的线,更别提主对角线了。

图2.10 序列1和序列3的打点图
除了可以用打点法给两条不同的序列打点,还可以用一条序列自己跟自己打点。这样可以发现序列中重复的片段。比如我们让下面这条序列自己和自己打点:
Seq4:THEFASTHESTHE
这样的打点矩阵必然是对称的,并且一定有一条主对角线(图2.11)。此外,在横向或纵向上,与主对角线平行的短平行线所对应的序列片段就是重复的部分。其中,红色短平行线对应的THE在序列中重复出现了3次。包括主对角线在内,平行线出现的次数就是重复的次数。

图2.11 序列自己和自己打点寻找重复序列
用这种方法我们还可以快捷的发现序列中的串联重复序列以及重复的次数。我们只要数数在半个矩阵中包括主对角线在内的所有等距的平行线的个数,就可以知道重复的次数,而且最短的平行线对应的序列就是重复单元(图2.12)。短的串联复序列具有高度多态性,也就是说不同的个体间重复次数存在差异,而且这种差异在基因遗传过程中一般遵循孟德尔共显性遗传规律,所以快速查找某些特定的短的串联复序列的重复次数可以用于法医学的个体识别或亲子鉴定等领域。
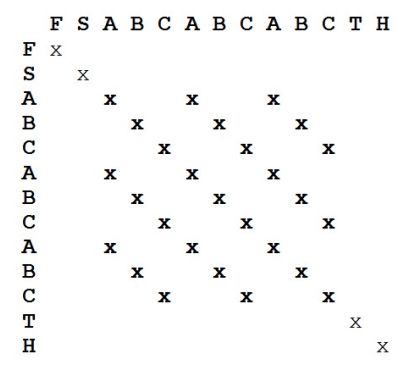
图2.12 打点法寻找串联重复序列
2、Dotlet介绍
打点用笔和纸有点不现实,我们得用计算机软件来执行,可以自动打点的软件有很多(表2.1)。我们挑其中最常用的 Dotlet 软件做为演示(http://myhits.isb-sib.ch/cgi-bin/dotlet)。Dotlet 基于Java开发,所以电脑需要安装Java,如果没有安装,可自行去JAVA官网下载安装。
表2.1 打点法在线软件

网页正常打开后如图2.13所示。我们看到上边一行是参数设置选项,包括选择水平位置的序列,选择垂直位置的序列,选择替换记分矩阵,选择以多长的序列为单元打一个点,还有窗口显示的比例,以及计算按钮。左边是打点图的显示窗口,右边是调控打点图显示效果的区域,下面还有一块是序列信息显示区。网页打开时除了 input 按钮,其他位置都是灰的。
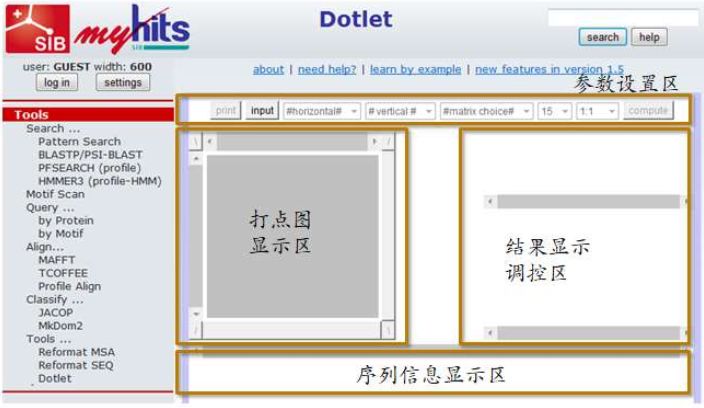
图2.13 Dotlet 在线打点工具界面
点击 input 按钮输入要打点的序列。在新打开的窗口里把要打点的序列拷贝进来。拷贝,黏贴。注意,序列输入窗口里只能输入纯序列部分。fasta格式里带大于号的第一行不能拷贝进来,否则Dotlet 会把这部分内容也当成序列进行打点。由于Dotlet不能自动识别FASTA格式里哪是名字,哪是序列,所以我们还需要手动的给这条序列取个名字,比如叫seq1,然后点ok,一条序列就输入进来了(图2.14)。
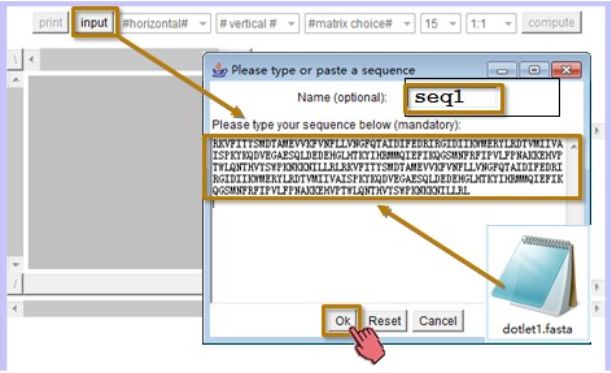
图2.14 打点序列的输入窗口
序列输入之后,参数设置行里水平序列的名字和垂直序列的名字都变成了seq1(图2.15)。
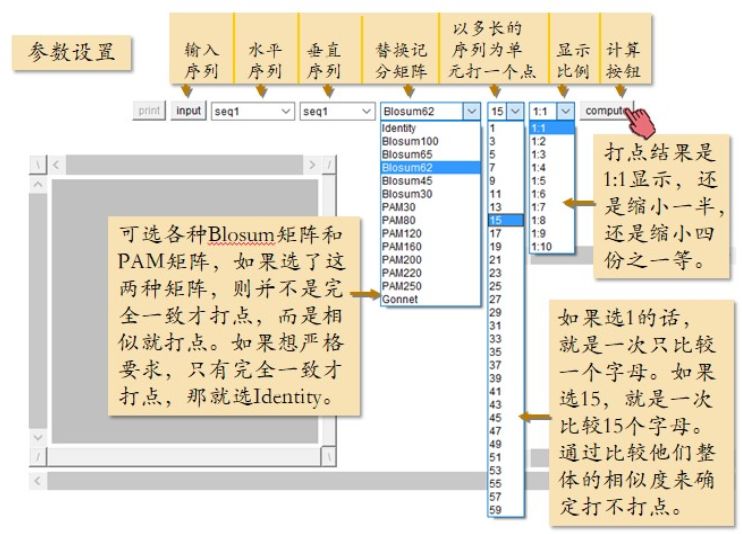
图2.15 Dotlet 参数选择
在这个例子里面我们让输入的这条 seq1 序列自己和自己打点。也就是水平位置的序列和垂直位置的序列都是 seq1。替换记分矩阵可以选讲过的各种 BLOSUM 矩阵或者PAM矩阵。如果选了这两种矩阵,表明并不是完全一致才打点,而是相似就打点。如果想要严格要求只有完全一致才打点的话,选Identity。再来看这个打点单元长度下拉条。这里如果选择1的话,就是一次只比较一个字母,这跟我们前面手动打点时的情况是一样的。如果选其他的,比如选择15,那就是一次比较15个字母,也就是看15个字母长度的序列整体的相似度如何来确定打不打点。注意这里不是比较完前15个字母,然后再从第16个字母开始比较后面的15个字母,而是第1次比较第1到第15个字母,然后再比较第2到第16个字母,再是第3到第17个字母,依次类推。所以选15和选1所进行的比较的次数是几乎一样多的,只是每次比较的序列单元长度不一样而已。显示比例窗口可以选择打点结果图是1:1原图显示,还是缩小为原图的 50%,或者25%显示。因为对于比较长的序列,这么小的窗口很难把原图显示完整。总结一下,第一个例子里水平序列seq1,垂直序列也是seq1,替换积分矩阵选Blosum62,比较单元长度15个字母,窗口显示比例1:1,最后点compute。
注意默认的颜色方案是在越相似的地方打的点的颜色越浅,越不相似的地方颜色越深。所以整体感觉像是在一张黑纸上打白点。因为是 seq1 自己和自己打点,所以应该有一条明显的主对角线,这是所有自己和自己打点的序列都会出现的情况。除此之外,还有一条与主对角线平行的次对角线,涉及 seq1大约1/2的长度。这说明 seq1 的前半部分和后半部分非常的相似(图2.16)。把鼠标点在这条次对角线上的任意位置,之后就可以从下面的序列显示区域看到,这一点,对应横着这条 seq1 的位置 153 开始的这一段,同时对应竖着这条seq1的位置11开始的这一段。为什么这一点对应的是一段呢?因为我们这里选的单元长度是15,也就是一次比较 15 个字母。从这里也可以看出,如果把 seq1 的前半段和后半段重合起来的话,它们是完全一样的序列。
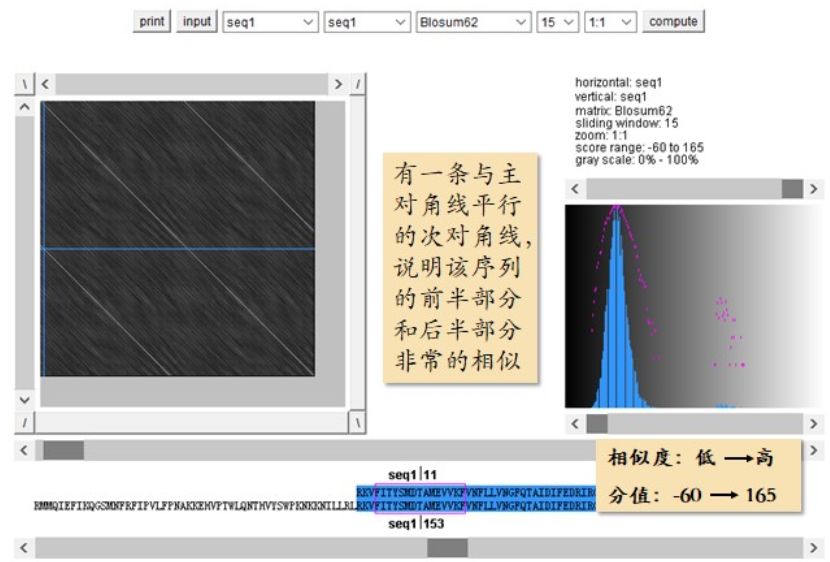
图2.16 Seq1 自己和自己打点计算出的打点图
可以通过调整灰度条,来屏蔽大多数低分值的点,让他们统统变成黑色背景,并且强化高分值的点,让他们以纯白色突出显示出来(图2.17)
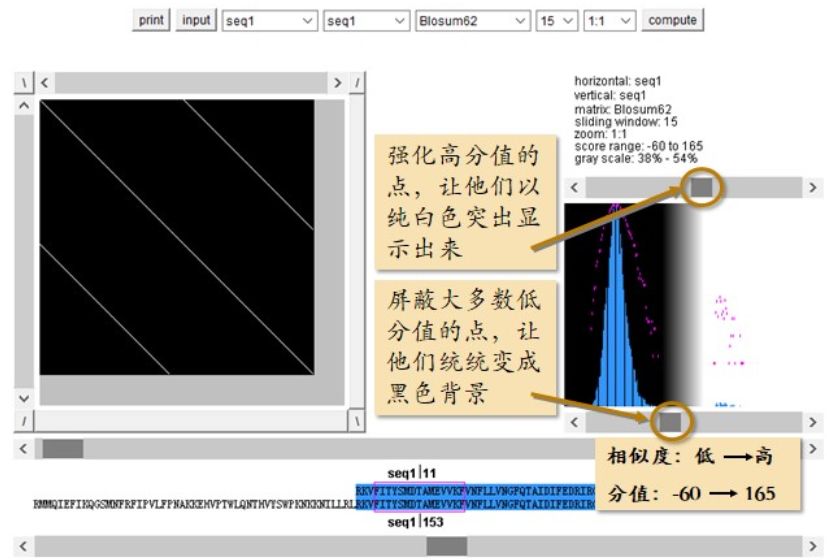
图2.17 调整灰度条改变打点图显示效果
上一个例子只是让大家熟悉一下 Dotlet 的使用界面及结果的查看方法,并没有实际的生物学意义。下面我们比较两条不同的序列,看看它们是否相似。将seq2 和 seq3 两条序列 input 进来。水平序列选 seq2,垂直序列选seq3,其他参数不变,点计算按钮。虽然这次的主对角线不如上一个例子里的明显,但是我们还是可以一眼就看出它来(图2.18)。说明这两条序列整体上十分相似。通过调整显示方案可以让主对角线清晰呈现。
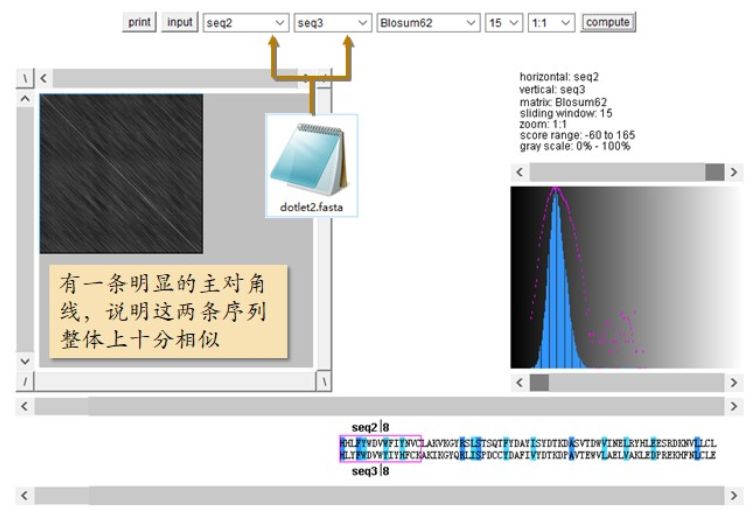
图2.18 Seq2 和 seq3 打点计算出的打点图
三、双序列全局比对
双序列全局比对,经典的全局比对算法是 Needleman-Wunsch 算法。用 Needleman-Wunsch 算法为序列 p 和序列 q 创建全局比对。输入值除了两条序列之外,还要有替换积分矩阵以确定不同字母间的相似度得分,以及空位罚分(图2.19),空位罚分就是当字母对空位的时候应该得几分。我们还是希望一致或相似的字母尽可能的对在一起,字母对空位的情况和不相似的字母对在一起的情况一样,都不是我们希望的,还是少出现为好,所以通常字母对空位会得到一个负分,这个负分就叫做空位罚分。这里我们让空位罚分,也就是 gap 分值为-5 分。在比对中没有空位对空位的情况。输入值就是这些。
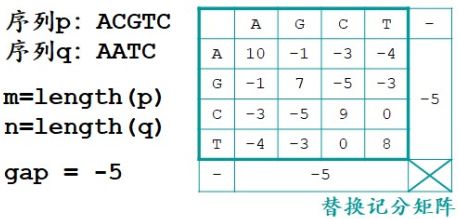
图2.19 全局比对输入值:序列 p 和序列 q,替换记分矩阵,空位罚分
接下来创建一个得分矩阵(图 2.20-A),并根据公式(图2.20-B)把得分矩阵填满。填满后全局比对就会跃然于纸上。得分矩阵的第一行是序列 p,第一列是序列 q,这一步和打点法很像。不过要注意,p和q的前面各留一个空列和一个空行,也就是第 0 列和第 0 行。
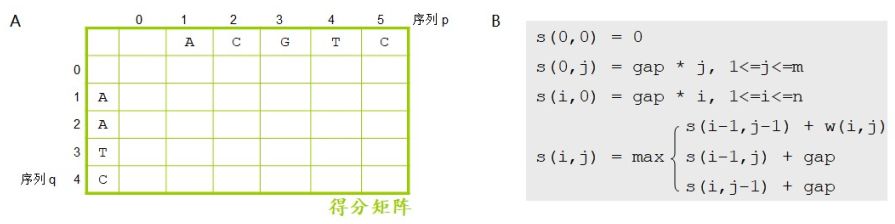
图 2.20 全局比对计算公式及得分矩阵
现在开始给得分矩阵赋值(图2.21)。根据公式:s(0,0)是初始值0。第0行:s(0,j) = gap * j,j 从 1 到 m,m 是序列 p 的长度。也就是 s(0,1)=gap*1=-5,s(0,2)=gap*2=-10,依次类推。第 0 行实际是一种极端情况的假设。也就是当序列 p 全部对空位时的得分。A 对空位是-5 分,AC 都对空位就累计到了-10 分,ACG 都对空位就累积到了-15 分,如果序列p 全部对空位,最终的累积得分就是-25 分。
第 0 列:s(i,0) = gap * i
第 0 列和第 0 行一样,也是反映了序列 q 如果全部对空位的累计得分。对一个空位累积gap*1=-5 分,对两个空位累积 gap*2=-10 分,对三个空位累积 gap*3=-15 分,对四个空位累积 gap*4=-20 分。
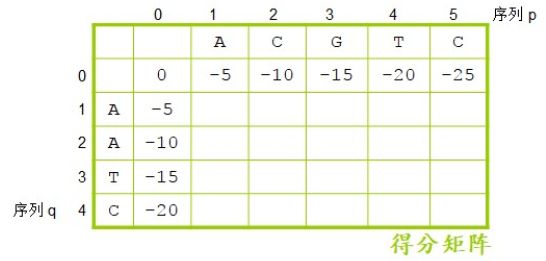
图2.21 得分矩阵中的第0行和第0列
第 0 行和第 0 列相对简单,其他的格就稍微复杂一点儿了。接下来填 s(1,1)(图2.22)。这个格里的值来源于三个值中的最大值。哪那三个值呢,一个是上面格 s(0,1)里的值加 gap,一个是左面格 s(1,0)里的值加 gap,还有一个是斜上格 s(0,0)里的值加当前这个位置字母对字母在替换记分矩阵里的分值 w(i,j)。什么意思呢?就是累积到这个位置时,是字母对字母得分高,还是序列 p 的字母对空位得分高,还是序列 q 的字母对空位得分高?有且只有这三种情况,我们要的是得分最高的那种情况。逐个看一下,上面格 s(0,1)+gap=-5+-5=-10。左面格 s(1,0) +gap=-5+-5=-10。斜上格 s(0,0)+w(1,1)=0+10=10。max(-10,-10,10)=10。所以当前这个格 s(1,1)的分值就是 10。此外,我们还需要用箭头记录一下这个 10 是从哪里来的。它是从斜上这个格来的,所以我们画一个指向斜上的箭头。
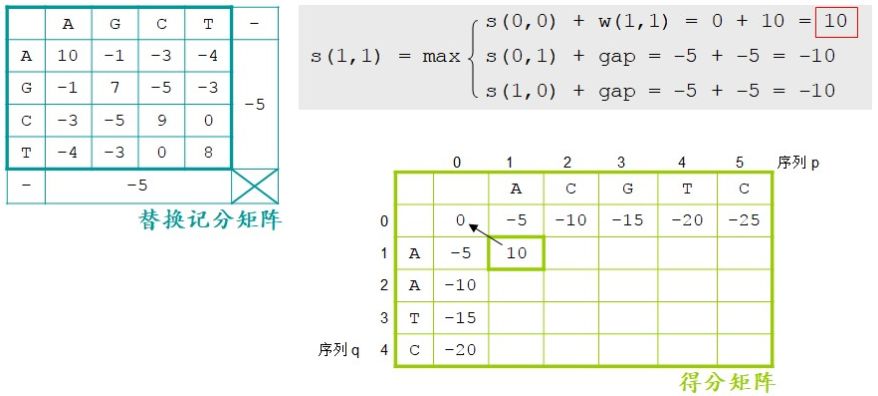
图2.22 得分矩阵中的 s(1,1)
接下这个格 s(1,2)值的计算(图2.23),仍然是找三个值中的最大值。上面格 s(0,2)+gap=-10+-5=-15。左面格 s(1,1)+gap=10+-5=5。斜上格 s(0,1)+w(1,2)=-5+-3=-8。max(-15,5,-8)=5。大值是5,来源于左面格 s(1,1),画上向左的箭头。

图2.23 得分矩阵中的 s(1,2)
按照上面的公式,将整个得分矩阵填满。这时,我们再回过头来看一下第一行和第一列(图2.24)。其实,第一行的每一个值都是从左边的格加 gap 来的。所以我们给它们补上向左的箭头。第一列的每一个值都是从上边的格加 gap 来的。所以我们给它们补上向上的箭头。至此,所有的箭头和数值就都填好了。填满之后,右下角的分数就是整个全局比对最终的得分。然后从这个位置开始追溯箭头一直到左上角的零,并且把这些箭头标记出来。
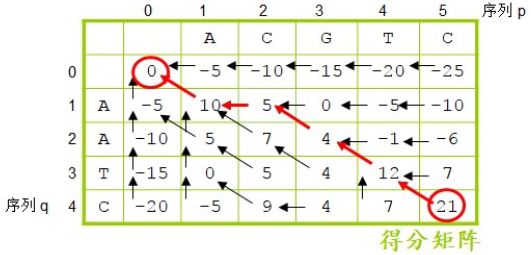
图2.24 填满分值和箭头的得分矩阵
图2.24中标出的红色箭头是写出全局比对的唯一依据。追溯箭头是从右下角到左上角,但是写全局比对是从左上角开始,如果是斜箭头则是字符对字符,如果是水平箭头或垂直箭头则是字符对空位,箭头指着的序列为空位。我们看第一个是斜箭头,字母对字母,就是 A对 A,第二个是水平箭头,字母对空位,箭头指着的序列是空位,也就是C对空位。然后斜箭头G对A,斜箭头T对 T,斜箭头 C 对 C,一直写到右下角,全局比对就出现了(图2.25)。唯一的一个空位插在序列 q 的 A 与 A 之间,这样最终的比对得分最高。不信的话可以试试,其他任何一种插入空位的比对结果,得分都不会超过 21 分。因为我们在得分矩阵的创建过程中,每一步都是在上一步最优的情况下得出的当前最优结果。

图2.25 序列 p 和序列 q 的全局比对
往期回顾生物信息学初识篇——第一章:生物数据库




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









