



 本实验模拟了编译器的词法分析过程,通过自底向上的方式产生规约序列。程序能处理LR(0)和LR(1),并根据用户输入的文法和解析表进行词法分析。
本实验模拟了编译器的词法分析过程,通过自底向上的方式产生规约序列。程序能处理LR(0)和LR(1),并根据用户输入的文法和解析表进行词法分析。
一、目标
本次实验的目的是对编译器进行词法分析的过程进行模拟,我选择了在实际中更为通用的自底向上的词法分析器的分析过程,最终产生规约序列。对于LR(0)和LR(1)问题,我的程序对于LR(0)和LR(1)是通用的,因为只要给出合法的parsing table和上下文无关文法, 程序就能进行相应的词法分析,而parsing table和文法都是用户输入文件给出。
二、内容概述
本文档描述了编译原理课程实验中,语法分析器部分的实验内容,实验方案以及结果。
三、实验环境操作系统:win8.1
编译器:eclipse
使用的工具:github
编码格式:utf-8
四、思路和核心思想
根据给出的文法,文法要求是非二义性的、非左递归的上下文无关文法,输入到product的文件中。从文件中读出输入的文法,先通过对输入的文法求每一个产生式中的非终结符的first和follow集合。来构建LL(1)的预测分析表。然后使用预测分析表来进行表格驱动,对于输入的串进行预测分析,使用书上的算法,现在在此处附上这算法,因为比较难打字,我附图:

五、测试输入与输出:
测试输入的文法产生式是书中的例子文法4-28,因为表示空的字符我打不出,就使用了#代替。书中的产生式还中的左边可以有或(|)进行连接,在我的输入中只能分开,当作多个产生式,同时不能有其他字符。对于终结符,只能有一个字母限定,书中的id我使用i代替。由于输入的原因,我把把书中的输入形式做了一下转变,实质上是同一个文法。
同时,输入串中输入的文件在项目当中,截图如下:

程序中产生的first和follow,如下,也存在项目中的文件first_follow.txt中:
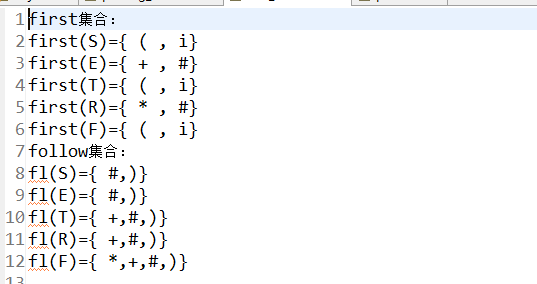
产生的预测分析表:

预测分析过程:
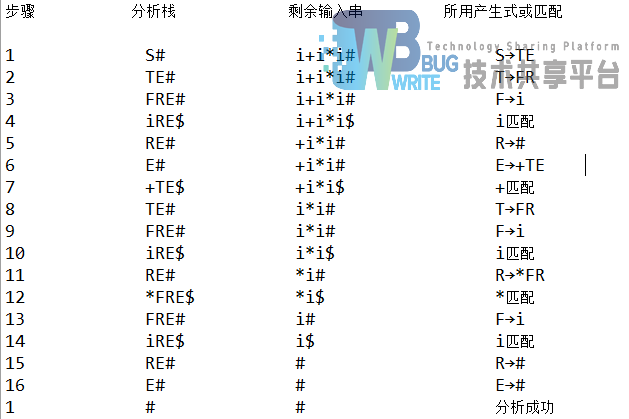
这些测试的结果都会以文件的形式产生在项目里的文件中。也会打印到控制台上。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









