





 本文围绕自动代码生成展开,提及VDA Guideline通用规则及ISO26262标准要求。指出Simulink模型生成C代码已成熟,介绍自动代码生成相关原则,如用正确模型、不手工改代码、管理关心数据等,还强调代码需验证与模型一致。
本文围绕自动代码生成展开,提及VDA Guideline通用规则及ISO26262标准要求。指出Simulink模型生成C代码已成熟,介绍自动代码生成相关原则,如用正确模型、不手工改代码、管理关心数据等,还强调代码需验证与模型一致。
编者按:原文转载于2018年10月29日,阅读量530。现因内容勘误的目的,再次编辑。
基于模型开发的场合,大家常常会纠结于如下两个问题:
需要还是不需要关注代码?
需要还是不需要在代码层面进行验证活动(如:静态代码分析、单元测试)呢?
在VDA Guideline中,定义有如下的规则:
[MBD.RL.8]如果在模型层面进行了验证(静态验证+单元测试),且使用可信赖的工具将模型生成代码,并且生成的代码没有再被修改,那么代码层面可以不再进行验证
注:VDA Guideline中关于模型的规则可参照:ASPICE VDA Guideline解读: 基于模型开发
VDA Guideline中给出的是通用的规则,但如果某领域标准要求在代码层面做验证,则需要遵照某领域的标准,例如:
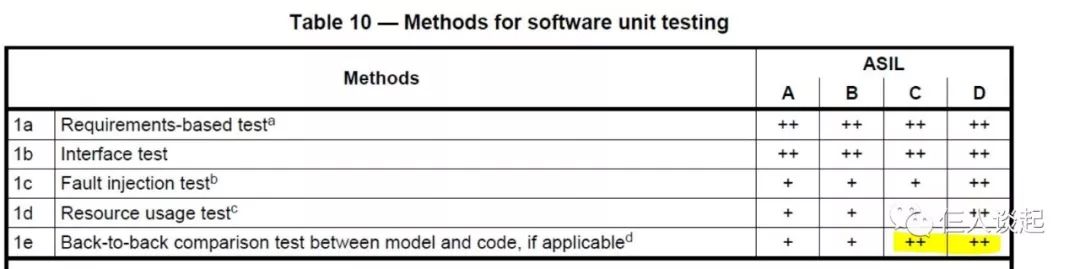
ISO26262标准中要求,在ASIL C, ASIL D场合,要求实施Back-to-Back测试,也就是要求在代码层面做SIL或PIL测试,验证代码与模型的一致性。
关于模型与代码之间的关系,接下来听听国内模型开发大佬老胡的文章
(原文载于”基于模型设计“公众号:自动代码生成那点事儿)
“10年前,我们经历了从汇编语言到C语言的转变,现在,我们是时候经历从C语言到Simulink模型的转变了….”
从第一次看到这句话到现在又一个10年过去了,10年的时间,很多领域在控制算法软件开发中已经完成了从C语言到Simulink模型的转变,当然,也有一些行业正在经历这样的转变,Simulink模型生成C代码已经成为非常成熟的技术。稍微有些遗憾的是,10年的时间,并没有像汇编语言到C语言的转变那样,让工程师们几乎彻底忘掉汇编语言,即便是在基于模型设计最为成熟的汽车行业,也依然有工程师还有翻看自动生成代码的习惯。
下面我来简单说说和自动代码生成相关的几个原则:
拿正确的模型去生成代码,代码生成工具不具备纠错功能,最完美的代码生成工具,也只能忠实于模型的描述,并将其转化为C代码。如果我们不确定模型正确与否,那我们得到的代码也同样是不能确保正确。
不对自动生成的代码做任何手工修改。从软件工程的角度上来讲,在基于模型的开发模式下,模型应该是我们工作和维护的工作产品,所有我们希望在代码里实现的内容,都应该通过模型或者模型配置去实现。如果我们手工修改自动生成的代码,那么整个开发过程的可维护性就大大降低,每次面对模型发生变更后生成的代码,我们都需要经过手工修改。
不看代码,不看代码并不绝对,这里主要是指不看算法的实现代码。在生成的.C和.H文件中,H文件作为和其他模块的接口文件,还是会有工程师去看看你这个模块到底定义了哪些全局的函数以及变量的。
管理你关心的数据,代码生成阶段的主要工作是数据管理工作,配置Simulink模型中需要关注的数据,这里主要是信号和参数,并将其按照项目的要求,生成为C代码中的变量和参数。对于那些不需要关注的数据,不建议做过多的配置,只要按照默认的规则生成变量即可。再罗嗦一句,我们只管理我们关心的数据,比如,跟其他模块之间的接口数据、需要标定的参数以及需要观测的变量。
代码的验证,这里我要扯一下ISO 26262的大旗,没办法,ISO26262出现之前,我也曾坚持在这种开发模式下无需对代码做静态验证,也无需对代码做动态测试,很多人难以接受我的观点,现在好了,在客户面前,我不再说这是我的观点,而是ISO26262里面的条款。传统模式下的静态、动态验证不需要了,但是,代码是否就无需验证了呢?非也,代码依然要经过充分验证,只是,在假设模型已经经过充分验证的前提下,这里只要再验证代码和模型一致即可,验证的方法,也就是我们非常熟悉的SIL和PIL,ISO26262里面称之为back-to-back测试。
我个人观点,尽量不要在代码生成这件事上耗费过多的心思。当然,“强迫症患者”我也接触过一些,虽说道理上讲理解可以不看代码,但还是忍不住要去关心代码,希望代码生成工具能够生成出来自己希望看到的代码。我是工程师,不是老中医,我这里没有药到病除的方子,我希望能做到的是让你的病情转移。你不是因为强迫症要关注代码吗?那你的模型测试是否充分?MC/DC覆盖是否已经达到了100%?强迫自己把模型测到尽可能充分吧,这才是有利于你产品品质提升的事情。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









