



 本文介绍了Spark SQL与Hive的集成。Spark SQL编译时可包含Hive支持,无需事先安装Hive。连接部署好的Hive需复制hive - site.xml到Spark配置目录。还阐述了内嵌Hive、外部Hive应用的使用方法,以及Spark SQL CLI的启动和代码中使用Hive的步骤。
本文介绍了Spark SQL与Hive的集成。Spark SQL编译时可包含Hive支持,无需事先安装Hive。连接部署好的Hive需复制hive - site.xml到Spark配置目录。还阐述了内嵌Hive、外部Hive应用的使用方法,以及Spark SQL CLI的启动和代码中使用Hive的步骤。
Apache Hive是Hadoop上的SQL引擎,Spark SQL编译时可以包含Hive支持,也可以不包含。包含Hive支持的Spark SQL可以支持Hive表访问、UDF(用户自定义函数)以及 Hive 查询语言(HiveQL/HQL)等。需要强调的一点是,如果要在Spark SQL中包含Hive的库,并不需要事先安装Hive。一般来说,最好还是在编译Spark SQL时引入Hive支持,这样就可以使用这些特性了。如果你下载的是二进制版本的 Spark,它应该已经在编译时添加了 Hive 支持。
若要把Spark SQL连接到一个部署好的Hive上,你必须把hive-site.xml复制到 Spark的配置文件目录中($SPARK_HOME/conf)。即使没有部署好Hive,Spark SQL也可以运行。 需要注意的是,如果你没有部署好Hive,Spark SQL会在当前的工作目录中创建出自己的Hive 元数据仓库,叫作 metastore_db。此外,如果你尝试使用 HiveQL 中的 CREATE TABLE (并非 CREATE EXTERNAL TABLE)语句来创建表,这些表会被放在你默认的文件系统中的 /user/hive/warehouse 目录中(如果你的 classpath 中有配好的 hdfs-site.xml,默认的文件系统就是 HDFS,否则就是本地文件系统)。
3.5.1 内嵌Hive应用
如果要使用内嵌的Hive,什么都不用做,直接用就可以了。
可以通过添加参数初次指定数据仓库地址:--conf spark.sql.warehouse.dir=hdfs://hadoop102/spark-wearhouse
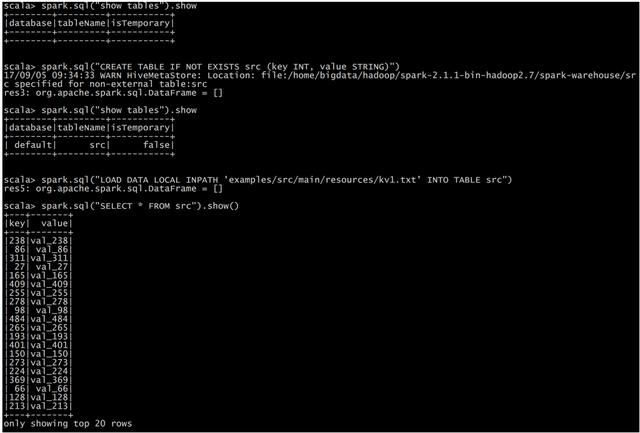
注意:如果你使用的是内部的Hive,在Spark2.0之后,spark.sql.warehouse.dir用于指定数据仓库的地址,如果你需要是用HDFS作为路径,那么需要将core-site.xml和hdfs-site.xml 加入到Spark conf目录,否则只会创建master节点上的warehouse目录,查询时会出现文件找不到的问题,这是需要使用HDFS,则需要将metastore删除,重启集群。
3.5.2 外部Hive应用
如果想连接外部已经部署好的Hive,需要通过以下几个步骤。
1) 将Hive中的hive-site.xml拷贝或者软连接到Spark安装目录下的conf目录下。
2) 打开spark shell,注意带上访问Hive元数据库的JDBC客户端
$ bin/spark-shell --jars mysql-connector-java-5.1.27-bin.jar3.5.3 运行Spark SQL CLI
Spark SQL CLI可以很方便的在本地运行Hive元数据服务以及从命令行执行查询任务。在Spark目录下执行如下命令启动Spark SQL CLI:
./bin/spark-sql3.5.4 代码中使用Hive
(1)添加依赖:
org.apache.spark spark-hive_2.11 2.1.1org.apache.hive hive-exec 1.2.1(2)创建SparkSession时需要添加hive支持
val warehouseLocation: String = new File("spark-warehouse").getAbsolutePathval spark = SparkSession .builder() .appName("Spark Hive Example") .config("spark.sql.warehouse.dir
















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









