



 本文详细探讨了Java中线程的实现方式,对比了实现Runnable接口与继承Thread类的优劣,并介绍了线程的六种状态及其转换过程。
本文详细探讨了Java中线程的实现方式,对比了实现Runnable接口与继承Thread类的优劣,并介绍了线程的六种状态及其转换过程。
全文共2496个字,阅读仅需10分钟
概述:
本章会围绕下面几点来进行讲解:
1、线程实现的方式有哪些?
2、实现Runnable接口和继承Thread类哪一种更好?
3、线程是如何在六种状态之间转换的?
一、线程实现的方式有哪些
先来一波总结:实现线程只有一种方式,就是调用Thread类的构造方法,实现一个线程,通过start()方法运行线程:例:
new Thread().start(),下面通过几个不同实现方式讲讲为什么
1、直接通过Thread类的方式(Thread抢占资源)
public class ExtendsThread extends Thread {
@Override
public void run() {
System.out.println("用Thread类实现线程");
}
}
//运行线程方式
new ExtendsThread().start();
以上等价于下面几个
// 匿名内部类
// 方式一:Thread方式
new Thread(){
public void run(){
System.out.println('用Thread类实现线程');
}
}.start();
// 方式二:Runnable接口
Runnable r = new Runnable(){
public void run(){}
};
new Thread(r).start();
// 方式三:lamdba
new Thread(()->{
System.out.println("111");
}).start();
这种方式构造方法里参数再千奇百怪,实现方式都一样,重写run()方法【表明线程要做什么】,通过start()方法来启动线程
缺点: 继承只能继承一个类,有局限;而且无返回值
2、实现Runnable接口(Runnable执行任务)
这里明确一个点,其实Runnable只是一个任务,通过Runnable的run()方法来表明线程要做什么
// 这只是一个任务哦,定义了线程需要做什么
public class RunnableDemo implements Runnable {
@Override
public void run() {
System.out.println("用Runnable实现线程");
}
}
// 这里才是线程跑起来了
new Thread(new RunnableDemo()).start();
优点:
1、可以用setPriority():配置线程优先级
2、可以实现多个接口
3、解耦:把设置线程任务【实现类中run()方法】和开启新线程【start()】进行分离
3、Callable+Future方式
第一步,实现Callable接口,这里说明一下Callable是有返回值的 ,可以抛出异常,有缓存 ,见Callable源码,泛型
V就是返回值类型@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
static class MyCall implements Callable<String> {
@Override
public String call() {
System.out.println("Hello MyCall");
return "success";
}
}
第二步:FutureTask
FutureTask futureTask=new FutureTask(new MyCall());
// FutureTask的构造方法:啊懂?
Public FutureTask(Callable callable){ }
第三步:运行线程
new Thread(futureTask).start();
第四步:获取线程运行结果
Object obj=futureTask.get();
Future也是一个很有魅力的类,会有会专门写一篇讲到;
Future的get()方法可以获取到Callable的返回值,但是这个方法可能会产生阻塞,异步任务
4、线程池创建线程
// 创建线程池实现多线程
ExecutorService service = Executors.newCachedThreadPool();
service.execute(()->{
System.out.println("Hello ThreadPool");
});
service.shutdown();
看起来也没什么啊,来分析一波线程池源码告诉你为什么
第一步:进入Executors.newCachedThreadPool()查看线程池的创建
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}第二步:进入线程池构造函数,划重点
Executors.defaultThreadFactory()
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
第三步:进入线程工厂内部类里
// 内部类
private static class DefaultThreadFactory implements ThreadFactory {
// 线程工厂构造函数
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
// 创建线程的具体方法
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
对于线程池而言,本质上是通过线程工厂创建线程的,默认采用 DefaultThreadFactory ,它会给线程池创建的线程设置一些默认值,比如:线程的名字、是否是守护线程,以及线程的优先级等。但是无论怎么设置这些属性,最终它还是通过 new Thread() 创建线程的 ,只不过这里的构造函数传入的参数要多一些,由此可以看出通过线程池创建线程并没有脱离最开始的那两种基本的创建方式,因为本质上还是通过 new Thread() 实现的。
线程池原理以后也会开一章讲一下(坑two)
实现线程的方式只有一种
总结: 线程创建的方式不只以上的四种,但是归根结底也就是构造一个Thread类来创建。
二、实现Runnable接口和继承Thread类哪一种更好?
结论
实现Runnable接口比继承Thread类好
好在哪里呢
解耦:Runnable负责线程执行内容,Thread负责线程启动和属性设置等内容,实现了Runnable和Thread的解耦;
某些情况下可以提高性能:
使用实现 Runnable 接口的方式,可以把任务直接传入线程池,使用一些固定的 线程来完成任务,不需要每次新建销毁线程,大大降低了性能开销。
继承 Thread 类方式,每次执行一次任务,都需要新建一个独立的线程,执行完任务后线程走到生命周期的尽头被销毁,如果还想执行这个任务,就必须再新建一个继承了 Thread 类的类。整个线程从开始创建到执行完毕被销毁,这一系列的操作比 run() 方法打印文字本身带来的开销要大得多。
扩展性好: Java语言特性就是继承只能继承一个,这样不利于后续的功能扩展;但是却可以实现多个接口。
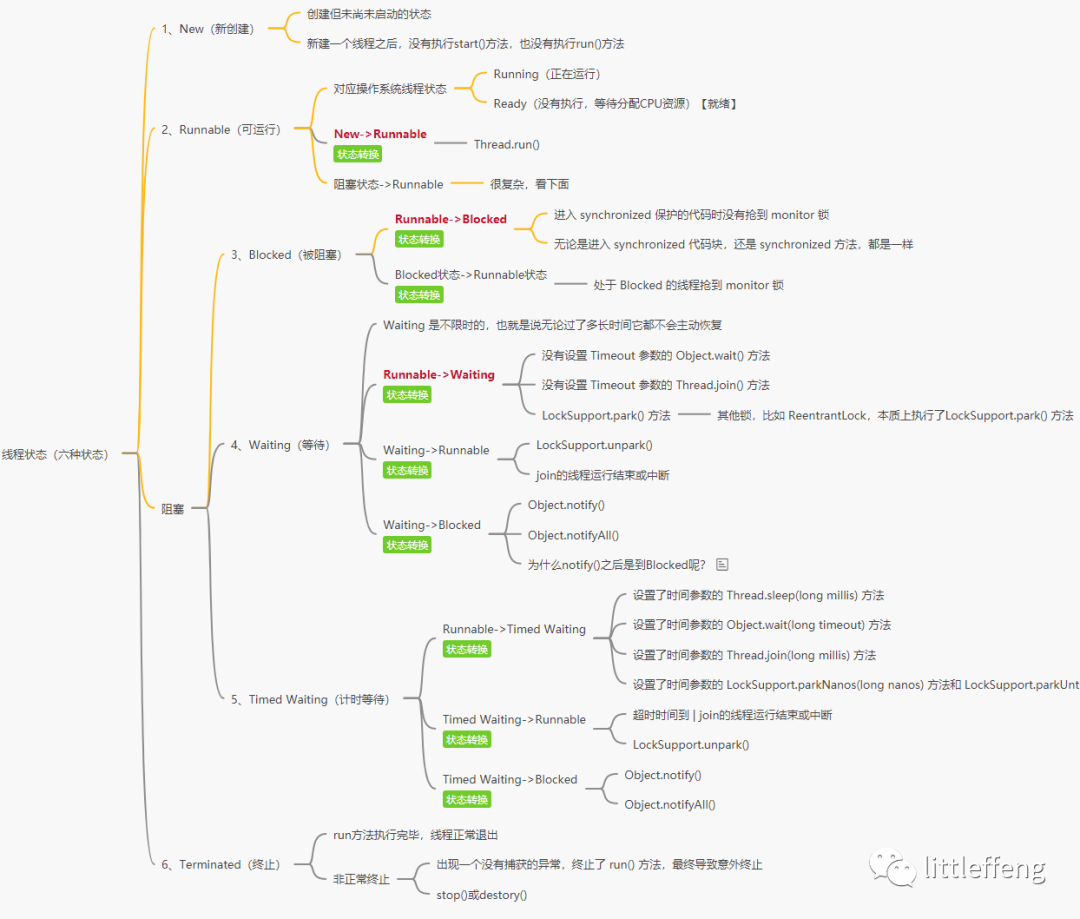
三、线程是如何在六种状态之间转换的?
线程一共有6种状态
确定当前线程状态:Thread.getState() 方法,并且线程在任何时刻只可能处于 1 种状态。六种状态之间的转换关系又可以聊很久。
New(新创建)、Runnable(可运行)、Blocked(阻塞)、Waiting(等待)、Timed Waiting(计时等待)、Terminated(终止)
1、New新建

就是new Thread()的状态
2、Runnable 可运行
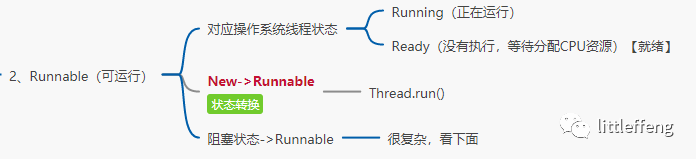
所以,如果一个正在运行的线程是 Runnable 状态,当它运行到任务的一半时,执行该线程的 CPU 被调度去做其他事情,导致该线程暂时不运行,它的状态依然不变,还是 Runnable,因为它有可能随时被调度回来继续执行任务。
划重点:Runnable执行一半没有CPU资源停了,也是Runnable状态
Java 中阻塞状态通常不仅仅是 Blocked,实际上它包括三种状态,分别是Blocked(被阻塞)、Waiting(等 待)、Timed Waiting(计时等待),这三 种状态统称为阻塞状态
各个状态之间转换的图,这个图很重要哦,以下内容都是围绕图讲的
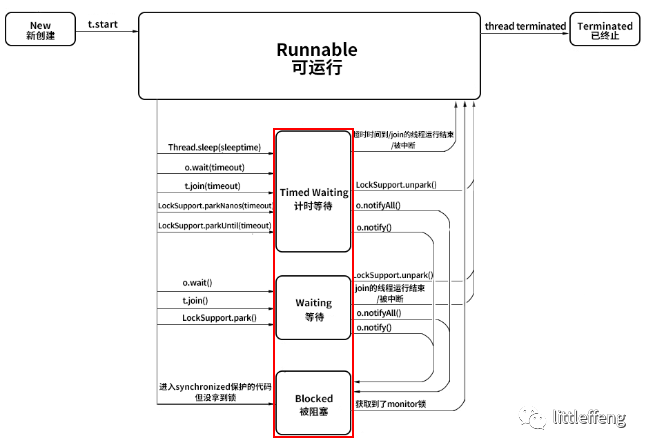
3、Blocked(阻塞)

状态转换:
Runnable->Blocked
进入 synchronized 保护的代码时没有抢到 monitor 锁
无论是进入 synchronized 代码块,还是 synchronized 方法,都是一样
Blocked状态->Runnable状态
处于 Blocked 的线程抢到 monitor 锁
4、Waiting(等待)

Waiting 是不限时的,也就是说无论过了多长时间它都不会主动恢复
状态转换:
Runnable->Waiting
没有设置 Timeout 参数的 Object.wait() 方法
没有设置 Timeout 参数的 Thread.join() 方法
LockSupport.park() 方法 【其他锁,比如 ReentrantLock,本质上执行了LockSupport.park() 方法】
Waiting->Runnable
LockSupport.unpark()
join的线程运行结束或中断
Waiting->Blocked
Object.notify() || Object.notifyAll()
提问:为什么notify()之后是到Blocked呢?
如果其他线程调用 notify() 或 notifyAll()来唤醒它,它会直接进入 Blocked 状态,这是为什么呢?因为唤醒 Waiting 线程的线程如果调用 notify() 或 notifyAll(),要求必须首先持有该 monitor 锁,所以处于 Waiting 状态的线程被唤醒时拿不到该锁,就会进入 Blocked 状态,直到执行了 notify()/notifyAll() 的唤醒它的线程执行完毕并释放 monitor 锁,才可能轮到它去抢夺这把锁,如果它能抢到,就会从 Blocked 状态回到 Runnable 状态。
5、Timed Waiting(计时等待)

Runnable->Timed Waiting
设置了时间参数的 Thread.sleep(long millis) 方法
设置了时间参数的 Object.wait(long timeout) 方法
设置了时间参数的 Thread.join(long millis) 方法
设置了时间参数的 LockSupport.parkNanos(long nanos) 方法和 LockSupport.parkUntil(long deadline) 方法
Timed Waiting->Runnable
超时时间到 | join的线程运行结束或中断
LockSupport.unpark()
Timed Waiting->Blocked
Object.notify() || Object.notifyAll()
6、 Terminated(终止)
两种情况会终止线程:
run()执行完毕,线程正常退出
非正常终止
出现一个没有捕获的异常,终止了 run() 方法,最终导致意外终止
执行 stop()或destory()
注意点
线程的状态是需要按照箭头方向来走的,比如线程从 New 状态是不可以直接进入 Blocked 状态的,它需要先经历 Runnable 状态。
线程生命周期不可逆:一旦进入 Runnable 状态就不能回到 New 状态;一旦被终止就不可能再有任何状态的变化。所以一个线程只能有一次 New 和 Terminated 状态,只有处于中间状态才可以相互转换。
附件
线程状态流转脑图
参考资料
1、各种并发资料
2、《Java 并发编程 78 讲》徐隆曦 课程很棒,条理清晰


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









