





本文用于复习pandas相关代码。
代码取自Datawhale仓库
joyful pandasgithub.com首先要安装Pandas 版本在1.0.1以上
import 查看Pandas版本
pdcsv/txt/xlsx文件读取
df 这里要注意读取excel文件要先安装xlrd包
# Anaconda用户
将数据保存回csv/xlsx(写入)
df保存回xlsx要先安装openpyxl包
# Anaconda用户
教程里面没有保存成txt的,这里挖个坑,有空再填
Pandas基本数据结构
Series
对于一个Series,其中最常用的属性为值(values),索引(index),名字(name),类型(dtype)
s 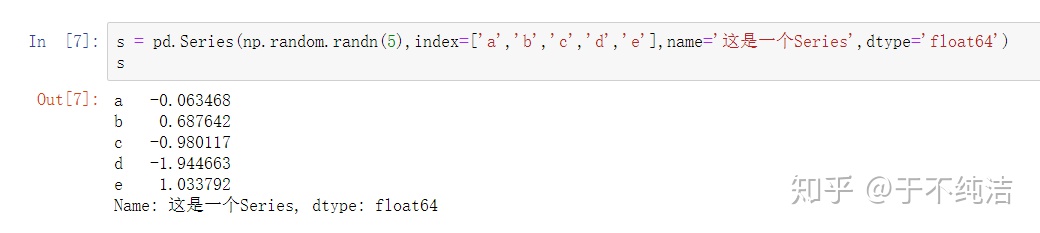
Series相当于一个列向量,包含值,列坐标和向量名。
访问Series的四个属性——值(values),索引(index),名字(name),类型(dtype)
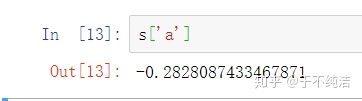
s取出Series的某一个元素,根据索引index来提取
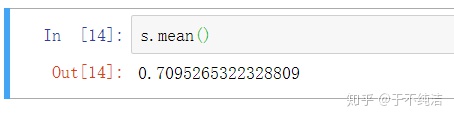
调用某些函数进行计算,如求平均值
DataFrame
相较于Series的列向量,DataFrame就像是完整的一个列表
这里一定要注意DataFrame的DF都需要大写,牢记!
创建一个Dataframe
df 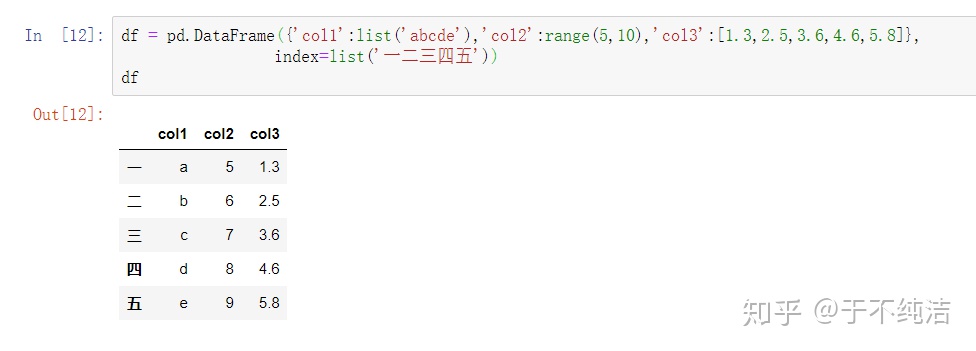
可以看到DataFrame的基本组成要有列名,每一列有什么和index
从DataFrame取出一列为Series
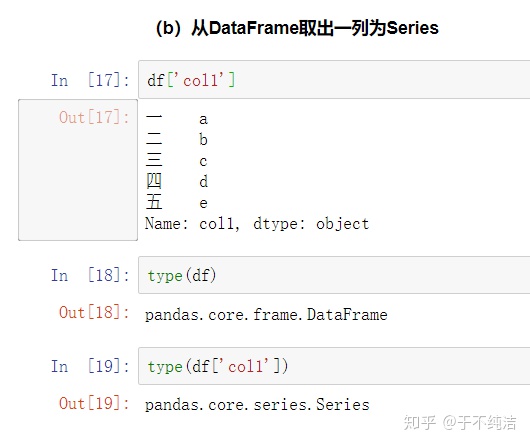
方法和数组是类似的,使用df['列名']的方法
修改行名或列名
df使用rename函数

类似地,也有调用属性的方法

索引对齐特性
这是Pandas中非常强大的特性,不理解这一特性有时就会造成一些麻烦

是index对应的元素相减
列的删除与添加
删除使用drop/del/pop函数
df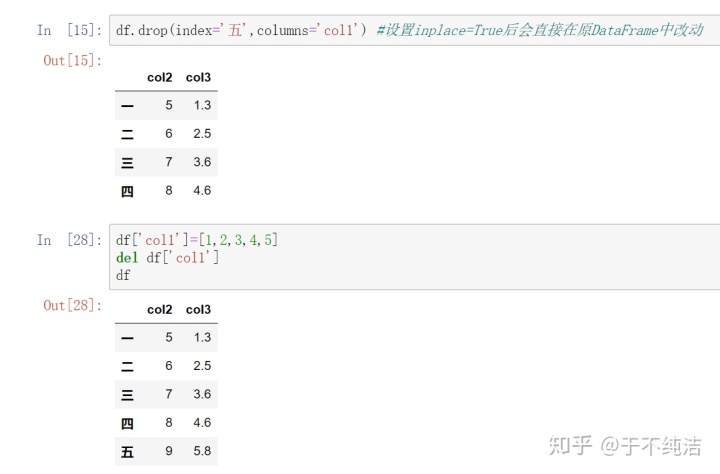
drop函数可以指定行名和列名,删除对应的行列,但不会影响原DataFrame,如果在drop中设置inplace=True后会直接在原DataFrame中改动
del函数指定列名直接删除原DataFrame对应的列,会改变原DataFrame
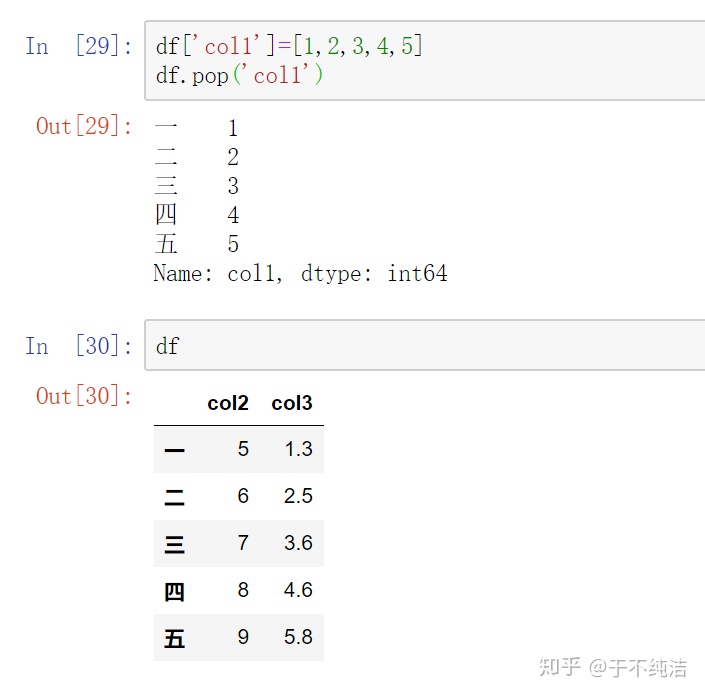
pop函数英文上是冒出泡泡的意思,所以你是把不要的东西冒出来,因此pop函数指定列名,直接输出该列,同时也会改变原DataFrame
增加新列
直接指定列名增加,也可使用assgin函数,增加一个Series

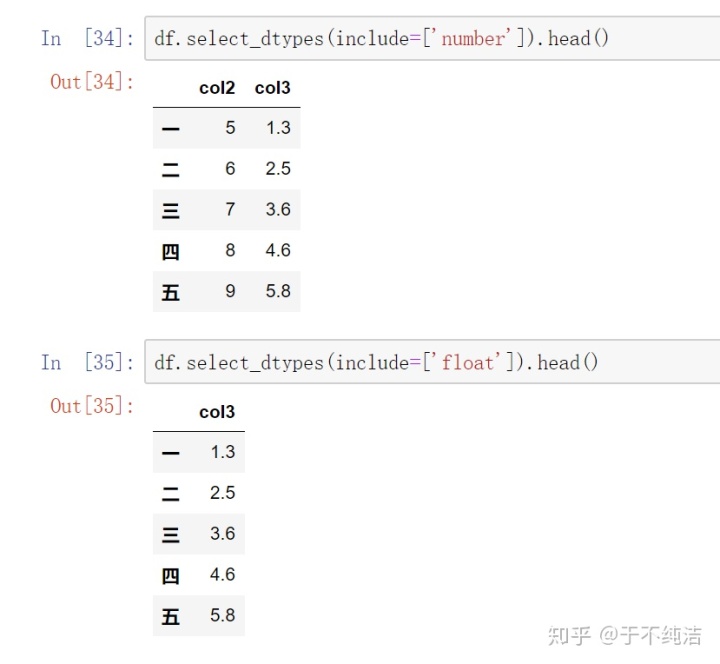
根据数据类型选择对应的列
将Series转换为DataFrame

使用T符号可以转置


















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









