 X-Engine内存表索引设计与性能评估
X-Engine内存表索引设计与性能评估




 本文以X-Engine为例,分析了“内存增量更新+磁盘基线数据”架构下内存表索引面临的挑战,提出了由字典树和有序双向链表组成的索引设计方案,并进行了详细实验评估。结果表明,该索引在点查询、范围查询、写入方面性能提升,内存占用降低,还能避免不必要转储,减少性能抖动。
本文以X-Engine为例,分析了“内存增量更新+磁盘基线数据”架构下内存表索引面临的挑战,提出了由字典树和有序双向链表组成的索引设计方案,并进行了详细实验评估。结果表明,该索引在点查询、范围查询、写入方面性能提升,内存占用降低,还能避免不必要转储,减少性能抖动。
目录
- 背景
- 问题分析
- 索引设计
- 基本结构
- 并发控制
- 内部自合并
- 内存管理
- 基于Epoch的内存回收
- 压缩的值节点存储格式
- 实验结果
- Micro Benchmarks
- 写入
- 点查询
- 范围查询
- 空间占用
- 读写混合(少量数据频繁更新)
- Macro Benchmarks
- 写入
- 点查询
- 范围查询
- 读写混合(少量数据频繁更新)
- 实验结果总结
- Micro Benchmarks
- 参考文献
背景
在X-Engine的基线数据内存索引设计一文中我们以X-Engine为例,介绍了在“增量更新+基线数据”的架构下,如何设计基线数据的内存索引。我们设计的基线数据内存索引点查询性能达到了和Masstree一致的水平,范围查询性能达到了和B+树一致的水平,在不同行长和不同并发度下的扩展性都很好。
然而,在“增量更新+基线数据”的架构下,用于缓存“增量更新”的内存表对系统的整体性能也有很大的影响。内存表是一个有序的内存结构,一方面需要处理持续的写入,另一方面,在读取路径上会先查询内存表,再查询基线数据。特别是当基线数据的查询性能非常高时,类似木桶原理,内存表的性能就成为了决定系统实际性能的短板。
许多索引结构都能满足内存表的功能需求,但是并不一定能达到理想的性能。LSM-Tree的原有设计使用B+树作为内存表的索引,后来Skiplist也被用于内存表的索引,X-Engine的内存表使用的就是Skiplist。Skiplist的优点是实现较为简单,特别是在并发控制方面,使用CAS语义就能很容易地实现无锁操作。然而在Skiplist中进行查询和写入时,访问需要在不同节点之间跳跃,后一次的访问很难利用前一次访问时加载进CPU缓存的内容,对CPU缓存不友好,因此Skiplist的查询和写入性能,特别是查询性能,不是非常理想。
同时,“增量更新+基线数据”架构下追加的写入方式也对内存表的索引设计产生一定的影响。在这样的架构下,更新通过写入新版本记录的方式来实现,因此一条记录可能在内存表中存在多个版本。在某些工作负载下,比如对少量的记录进行频繁的更新时,内存表中会存在大量的无效的旧版本记录,产生严重的空间膨胀。这会导致仅包含少量有效数据的内存表因为达到内存阈值被过早的转储到磁盘上,影响这部分数据的读性能,同时加剧了写放大。
因此,我们以X-Engine为例,分析了“内存增量更新+磁盘基线数据”这样的架构下,用于处理“增量更新”的内存表所面对场景的特点和挑战,提出了内存表的索引设计方案,并进行了详细的实验评估。
问题分析
处理“增量更新”的内存表的索引面对的挑战有以下四点:
- 同时具有优异的写入和查询性能。内存表需要提供的功能主要是写入、点查询和范围查询,因此内存表的索引在这三方面需要具有较高的综合性能。
- 轻量的并发控制。不同于基线数据的索引,内存表的索引需要同时处理并发的写入和查询,因此需要轻量的并发控制在保证正确性的同时避免对读写性能产生较大影响,实现高可扩展性。
- 缓解空间膨胀。内存表的索引结构需要支持对无效旧版本记录的回收。在内存表被转储前就及时的回收无效的旧版本可以缓解空间膨胀的问题,避免内存表在某些工作负载下被过早的转储,影响系统的读性能。
- 高效的内存管理。
- 快速的小内存并发分配。由于需要处理持续的写入,内存表的索引结构会发生频繁的更新,因此会发生频繁的小块内存的并发分配,这会对索引性能,特别是写入性能,产生极大的影响。
- 内存利用率高的存储格式。内存表的内存使用是受限的,因此需要尽可能地减少索引自身的内存开销,提升内存表的内存利用率,存储更多的记录。
- 及时安全轻量的内存回收。索引结构更新时产生的旧对象以及追加写入产生的无效记录被删除后,都需要及时地进行内存回收,才能减少实际内存占用。然而,在多线程并发读写的场景下,旧对象或无效记录被逻辑删除时,可能正在被其他线程访问,因此需要保证旧对象或无效记录不会再被任何线程访问后,才能安全地进行内存空间的物理回收。同时,多线程安全的内存回收机制应该尽可能地轻量,避免对内存表的整体性能产生影响。
索引设计
基本结构
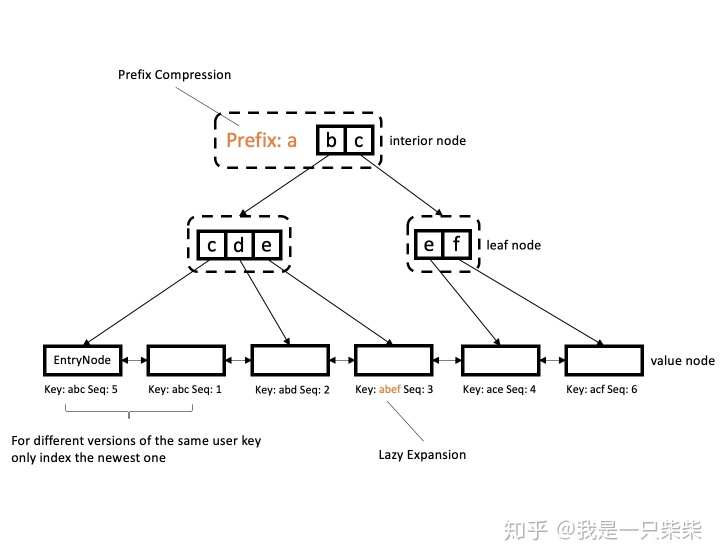
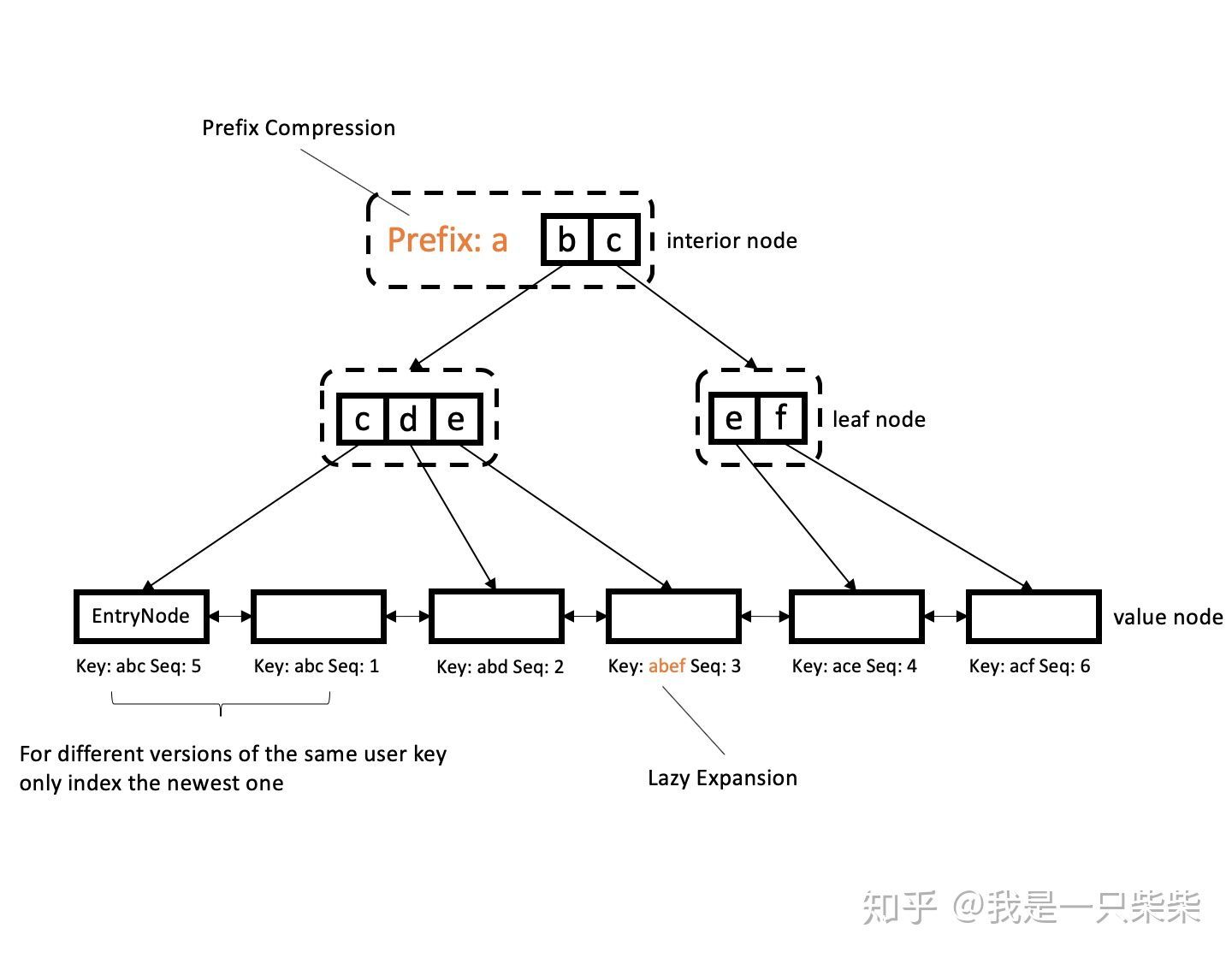
我们设计的内存表索引由一个字典树和一个有序双向链表组成,如上图所示。字典树仅索引user key,完整的internal key和对应的value存储在字典树的值节点中,所有值节点使用双向链表有序连接(user key指用户写入的key,因为同一user key在存储引擎中可能存在多个版本,因此存储引擎会为每一个user key分配一个sequence number,user key、sequence number和key的type组成全局唯一的internal key)。字典树采用了prefix compression和lazy expansion优化,同时采用了ART自适应节点格式的设计。字典树叶节点中的指针指向包含最新版本user key的值节点。
我们采用“字典树仅索引user key和双向链表有序存储internal key”的设计基于如下三点考虑:
- 同时具有较高的写入、点查询和范围查询性能。根据我们的前期调研和测试,字典树一类的数据结构相对搜索树一类的数据结构在写入和点查询方面具有极大的性能优势,而范围查询性能却不如搜索树一类的数据结构。经过分析,字典树范围查询性能不佳的原因是因为底层节点无序,范围查询时向后迭代的过程需要回溯到上层节点。因此我们使用字典树来作为内存表的索引,使得内存表具有较高的写入和点查询性能,同时使用双向链表将字典树索引的值节点有序连接,弥补字典树范围查询性能不足的缺陷。
- 减少索引自身的内存开销。如果使用字典树索引完整的internal key,则字典树的层数会增加,自身内存开销增大。而如果仅索引user key,因为绝大部分的查询需要的是user key的最新版本,所以在通过字典树找到user key之后就已经找到了需要的结果。即便查询需要的是旧版本的user key,因为双向链表有序存储了完整的internal key,所以在通过字典树找到user key之后,可以很快地借助双向链表找到这个user key的任何一个版本。因此该方案在减少索引自身内存开销的同时几乎不会带来性能的损失。
- 便于无效旧版本记录的回收,缓解空间膨胀。因为字典树仅索引user key,所以如果需要回收无效的旧版本记录,只需要在有序的双向链表中做删除即可,而不需要更新字典树的结构,代价极低。如果字典树索引internal key,那么回收无效的旧版本记录时还需要更新字典树的相关节点,产生额外开销。
并发控制
读写内存表的过程可以拆分为读写字典树和读写双向链表这两个阶段,我们在字典树和双向链表中分别采用独立的并发控制策略来保证各自并发读写的正确性。同时,我们通过一个commit标志位来保证读写内存表的两阶段的原子性,避免读取到处于中间状态的值节点(例如仅完成了写字典树的阶段)而出现正确性问题。
对于字典树,我们采用[1]中提出的Optimistic Lock Coupling(简称OLC)的并发控制策略。OLC是Lock Coupling[2]的乐观版本,两者读写时获取和释放读写锁的流程是一致的,区别在于读写锁的实现。OLC中的读写锁包含锁和一个版本号,锁和版本号共享对齐的8字节内存。获取写锁时会实际加锁并在完成后更新版本号,因为共享对齐的8字节内存,所以对锁和版本号的操作是原子的,释放写锁时会实际解锁。获取读锁时并不需要实际加锁或更新版本号,只需要获取当前的版本快照(如果已加写锁则等待锁释放),释放读锁时比较当前的版本号和之前获得的版本快照是否一致,并判断当前是否加锁,否则从根节点开始重做。
// write
1. lock latch
2. update current node content
3. release latch and increase version
// read
1. record version
2. read current node content
3. if node is latched, retry
4. if version differs, retry对于双向链表,我们基于自旋锁和原子变量实现了“读无锁,写加锁,写不阻塞读”的并发控制策略。双向链表中每个节点的prev和next指针使用原子变量实现,同时每个节点包含一个自旋锁。在双向链表中插入新节点时,需要将插入位置左侧的节点加锁,使用原子操作修改相关节点的prev和next指针。只需要对插入位置一侧的节点加锁,我们就可以保证同一个插入位置只有一个线程在插入节点。当多个线程试图在同一个位置插入节点时,只有第一个获得插入位置左侧节点的锁的线程可以完成插入,其余线程后续获得锁之后需要重新判断插入位置,以保证双向链表的有序。在双向链表中遍历时,只需要使用原子操作获得prev和next指针的值即可访问下一个节点。
我们使用一个commit标志位来保证分阶段读写内存表的原子性。因为读写字典树和读写双向链表这两个阶段的并发控制策略彼此独立,因此如果不保证这两个阶段操作的原子性,读可能会遇到处于写的中间状态的值节点,从而读到错误的结果。所以我们为每一个插入的值节点设计了一个commit标志位,插入前标志位被清除,只有在完成写内存表的两个阶段后,标志位才会被设置。读内存表时在读取双向链表中值节点的阶段会检查每个值节点的标志位,如果标志位未被设置,则需等待该节点完成写内存表的全部过程后才能继续读取。
内部自合并
由于采用追加写入的更新方式,在内存表中同一条记录可能会产生多个版本。基于“增量更新+基线数据”架构的存储引擎往往采用版本快照来支持事务的不同隔离级别,在同一条记录的不同版本中,在所有存在的版本快照中都不可见的就是过期的无效数据,这些过期的无效数据会在内存表转储的过程中被回收。
然而在某些工作负载下,例如对少量的数据进行频繁更新时,内存表中会存在大量的无效数据,仅包含少量有效数据的内存表被频繁转储到磁盘上,造成很大的性能抖动。同时,每次转储保留下来的少量有效数据需要合并到基线数据上,频繁的转储加剧了磁盘的写放大。
因此,我们设计了内存表的内部自合并来缓解因无效数据带来的空间膨胀的问题。内部自合并由内存表的空间占用或无效数据的比例触发,通过后台线程执行。和内存表的转储以及基线数据的合并操作类似,自合并操作会在开始前获取并缓存当前存在的版本快照,然后遍历内存表结构中的双向链表,根据缓存的版本快照回收无效数据。由于内存表结构中的字典树只索引同一条记录的最新版本,因此对无效数据的回收只需要修改双向链表,代价极低。
无效数据的回收分为双向链表删除和内存空间回收两个阶段。虽然无效数据已经不会被点查询访问到,然而前台线程进行范围查询时在双向链表中遍历的过程依然可能访问无效数据,因此第一阶段仅在双向链表中删除无效数据的值节点,同时保持被删除值节点的prev和next指针的指向,确保当无效数据被删除时,如果有前台线程进行范围查询并遍历到无效数据的值节点,前台线程依然能够经由被删除的值节点继续完成遍历过程。当被删除的无效数据不会被任何前台线程访问后,执行自合并的后台线程才会进行第二阶段的内存空间回收,该过程通过下文所述的基于Epoch的内存回收方案实现。
内存管理
我们通过以下两个手段来提升内存管理效率:
基于Epoch的内存回收
在多核并发的场景下,被逻辑删除的过期对象可能正在被其他线程访问,因此不能立即进行物理回收,需要采用多线程安全的方案在保证过期对象不再被任何线程访问后再进行物理回收。多线程安全的内存回收方案主要可以分为两类,基于引用计数的方案和基于Epoch的方案。因为内存表是纯内存数据结构,如果使用基于引用计数的方案,读写内存对象时都需要修改引用计数,造成对应CPU缓存行失效,在多核并发的场景下会大大增加coherence cache miss,同时还会出现false sharing的问题,根据我们前期的验证,这会对整体性能产生严重的影响,因此我们采用了基于Epoch的内存回收方案。
我们设计的方案大致如下:维护一个全局的Epoch对象,读写线程在访问内存表前会获取全局Epoch的快照并保存在线程局部存储中,并在访问结束后释放持有的快照。逻辑删除时也会将过期对象的指针保存在线程局部存储中,同时保存逻辑删除发生时全局Epoch的快照。全局Epoch会随着逻辑删除次数的增加而不断推进,不同线程和被删除对象持有的Epoch快照版本也不同。假设当前所有读写线程持有的快照中最小的版本是e,持有的快照版本小于e的被删除对象不可能再被任何读写线程访问到,可以被安全地回收。所以我们在每次内存回收前遍历所有读写线程的局部存储,计算出当前最小的快照版本,然后基于前述规则安全地回收过期对象的内存。
// Foreground thread
thread_local_var.local_epoch = get_snapshot(global_epoch)
// ...
thread_local_var.delete_list.add(DeleteEntry(deleted_obj))
// ...
thread_local_var.local_epoch = MAX_EPOCH
if thread_local_var.delete_counter > forward_threshold:
forward_global_epoch()
if thread_local_var.delete_list.reach_reclaim_threshold() is true:
oldest_epoch = traverse_all_thread_local()
thread_local_var.delete_list.do_memory_reclaim(oldest_epoch)
// Delete function
DeleteEntry(deleted_obj) {
local_epoch = get_snapshot(global_epoch)
return {deleted_obj, local_epoch}
}在上述方案中,我们进行了如下优化:
- 使用线程局部存储减少共享内存。除了全局Epoch对象被多线程共享外,其余对象(包括线程的Epoch快照、被删除对象的指针和相应快照)都保存在线程局部存储中,相对于基于引用计数的方案,极大地减少了共享内存的多核访问,从而缓解了coherence cache miss和false sharing问题。
- 内存回收保持合适频率。由于遍历所有读写线程的局部存储开销较大,因此出现可以被安全回收的过期对象时我们不会立即进行内存回收,而是当可以被安全回收的过期对象累积到一个合适的量后才进行内存回收,在避免产生过多空间浪费的同时摊还遍历所有读写线程局部存储的开销。
- 由前台线程完成内存回收,减少线程调度,及时回收内存。每个前台读写线程在结束内存表的访问后检查各自线程局部存储中保存的被删除对象的量,达到阈值后直接在前台线程中完成内存回收的工作,而不是将内存回收任务分发给后台线程完成,减少线程调度的开销,同时可以保证内存的及时回收。
- 减少全局Epoch不必要的推进。全局Epoch的推进只会影响到被删除对象的回收,因此在我们的方案中全局Epoch的推进只和逻辑删除操作的次数有关,相对于其他推进机制(比如按一定时间间隔推进),减少了不必要的Epoch推进。
压缩的值节点存储格式
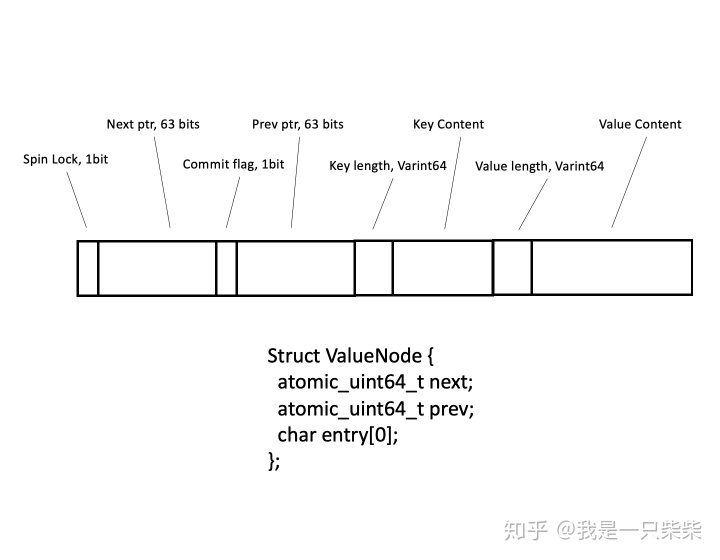
一个值节点理论上需要包含next和prev指针、一个自旋锁、一个commit标志位、实际键值对。我们观察到当前系统的逻辑地址空间实际上只需要使用一个8字节指针中的48bits就可以完全覆盖,因此我们将next指针变量的Most Significant Bit(简称MSB)用作自旋锁,将prev指针变量的MSB用作commit标志位。同时我们并不会在值节点中存储指向实际键值对的指针,而是采用flexible array member的方式,将实际键值对的内容紧接着存储在值节点对象之后。值节点的压缩存储格式如下图所示。
实验结果
Micro Benchmarks
写入
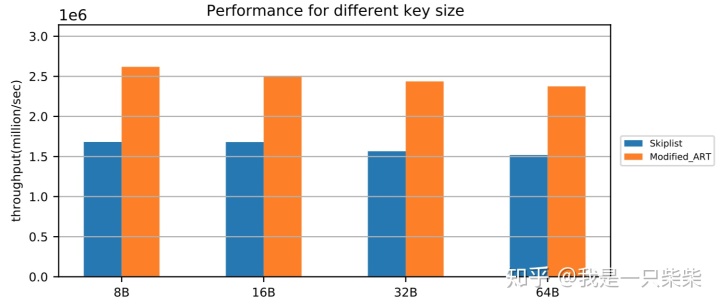
我们以基于Skiplist的内存表为baseline,使用db_bench fillrandom workload测试了我们设计的内存表索引的随机写性能,测试使用32线程压测32个subtable,value长度为8B,写入key的范围为20million,横坐标为key的长度。实验结果如下图所示。
从实验结果中我们可以看出,我们设计的内存表索引随机写性能在不同行长下相对baseline提升48%-56%。
点查询
改变数据量
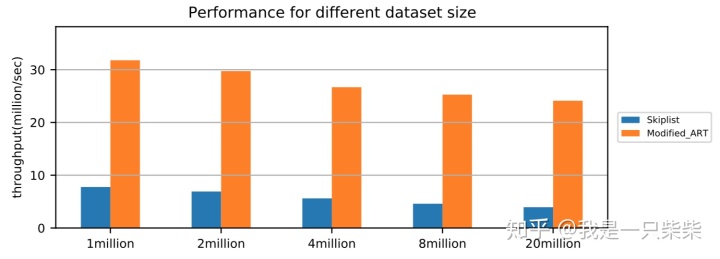
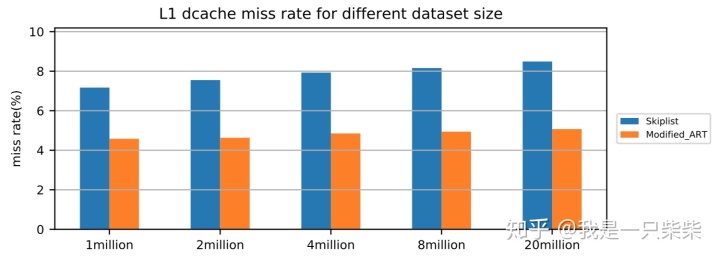
我们以基于Skiplist的内存表为baseline,使用db_bench readrandom workload测试了我们设计的内存表索引的点查询性能,测试使用32线程压测32个subtable,key长度为16B,value长度为8B,横坐标为Memtable中key的数量。实验结果如下图所示。
从实验结果中我们可以看出,我们设计的内存表索引点查询性能在不同数据量下相对baseline提升309%-512%,数据量越大性能提升也越大。
改变并发数
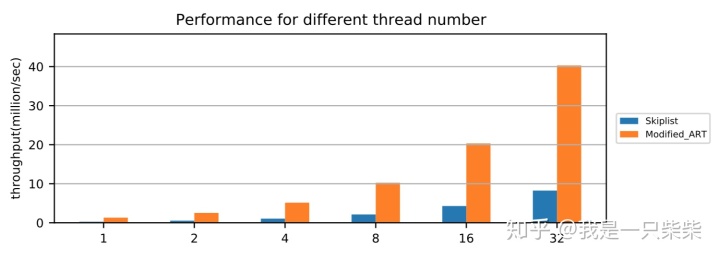
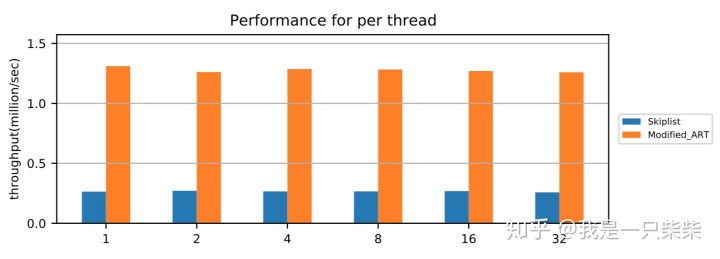
我们以基于Skiplist的内存表为baseline,使用db_bench readrandom workload测试了我们设计的内存表索引的点查询性能,测试中使用不同数量的线程压测一个subtable,key长度为16B,value长度为8B,数据量大小为20million条记录,横坐标为并发线程数。实验结果如下图所示。
从实验结果中我们可以看出,我们设计的内存表索引点查询性能在不同并发数下具有极好的可扩展性。
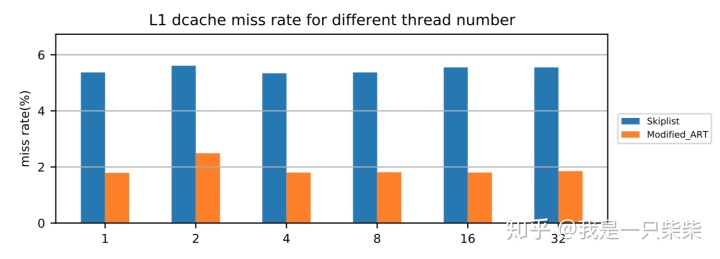
改变行长
我们以基于Skiplist的内存表为baseline,使用db_bench readrandom workload测试了我们设计的内存表索引的点查询性能,测试使用32线程压测32个subtable,value长度为8B,数据量大小为20million条记录,横坐标为key长度。实验结果如下图所示。
从实验结果中我们可以看出,我们设计的内存表索引点查询性能在不同行长下也具有极好的可扩展性。
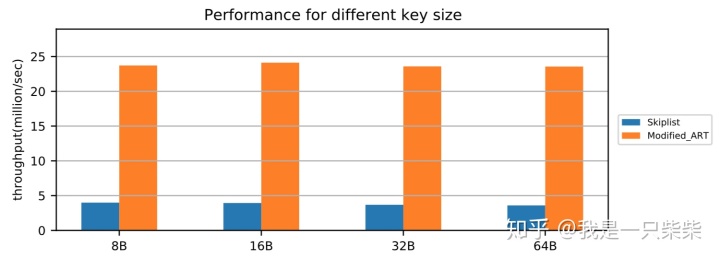
范围查询
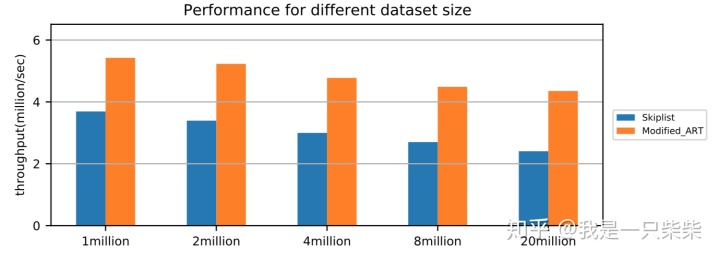
改变数据量
我们以基于Skiplist的内存表为baseline,使用db_bench seekrandom workload测试了我们设计的内存表索引的范围查询性能,测试使用32线程压测32个subtable,key长度为16B,value长度为8B,范围查询长度为5-20(均匀随机),横坐标为Memtable中key的数量。实验结果如下图所示。
从实验结果中我们可以看出,我们设计的内存表索引范围查询性能在不同数据量下相对baseline提升47%-81%,数据量越大性能提升也越大。
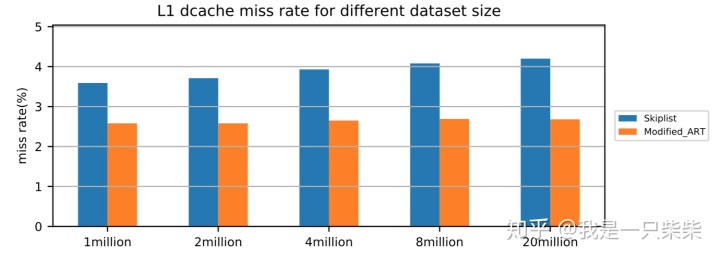
改变并发数
我们以基于Skiplist的内存表为baseline,使用db_bench seekrandom workload测试了我们设计的内存表索引的范围查询性能,测试中使用不同数量的线程压测一个subtable,key长度为16B,value长度为8B,数据量大小为20million条记录,横坐标为并发线程数。实验结果如下图所示。
从实验结果中我们可以看出,我们设计的内存表索引范围查询性能在不同并发数下具有极好的可扩展性。
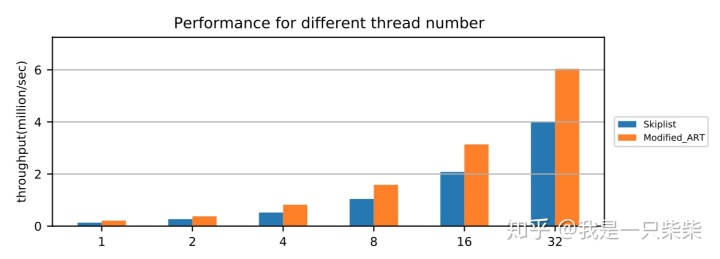
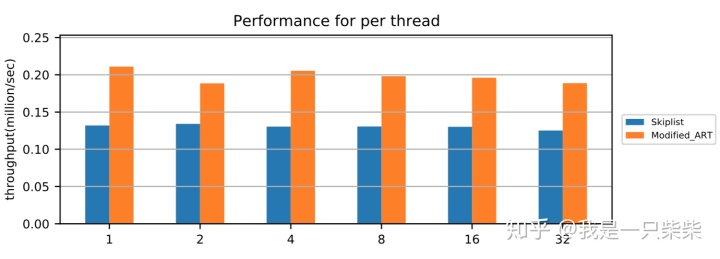
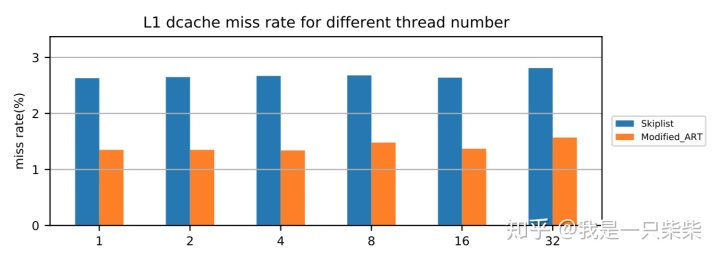
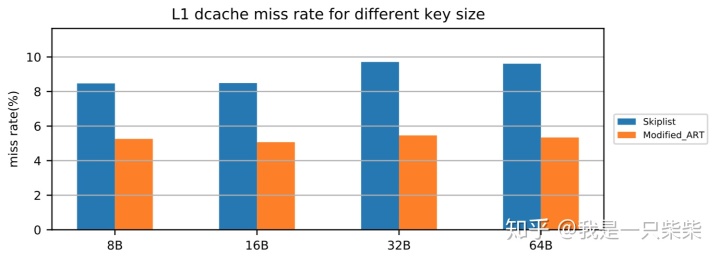
改变行长
我们以基于Skiplist的内存表为baseline,使用db_bench seekrandom workload测试了我们设计的内存表索引的范围查询性能,测试使用32线程压测32个subtable,value长度为8B,范围查询长度为5-20(均匀随机),数据量大小为20million条记录,横坐标为key长度。实验结果如下图所示。
从实验结果中我们可以看出,我们设计的内存表索引范围查询性能在不同行长下也具有极好的可扩展性。

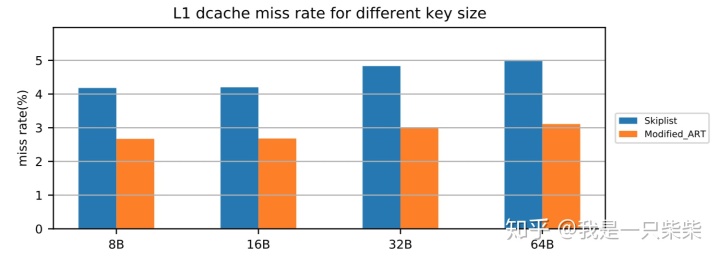
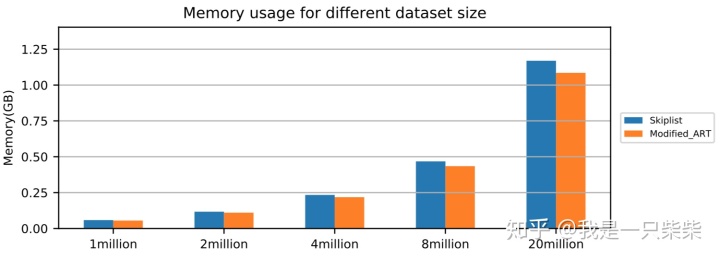
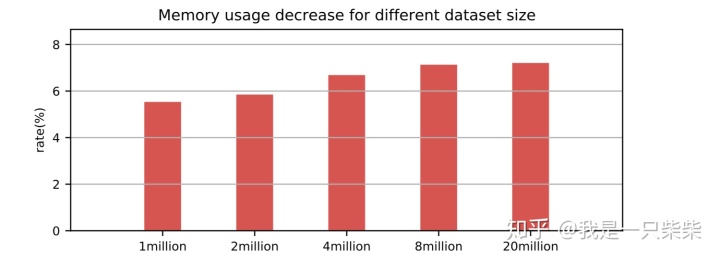
空间占用
改变数据量
我们以基于Skiplist的内存表为baseline,测试了不同数据量下我们设计的内存表索引的空间占用情况,测试使用单线程顺序向内存表内写入一定数量的记录,key长度为16B,value长度为8B,横坐标为数据量大小。实验结果如下图所示。
从实验结果中我们可以看出,在行长一定的情况下,随着数据量的增加,我们设计的内存表索引的空间占用相对baseline降低的比例逐渐提升,从5.5%提升至7.2%。
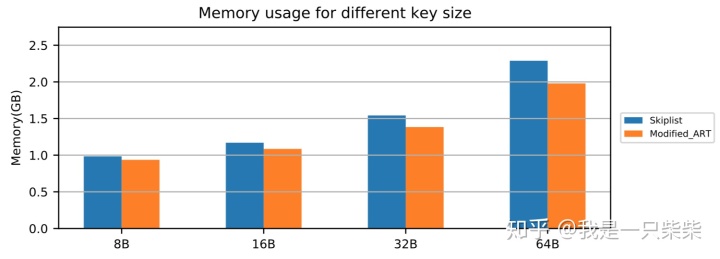
改变行长
我们以基于Skiplist的内存表为baseline,测试了不同行长下我们设计的内存表索引的空间占用情况,测试使用单线程顺序向内存表内写入20million的记录,value长度为8B,横坐标为key长度。实验结果如下图所示。
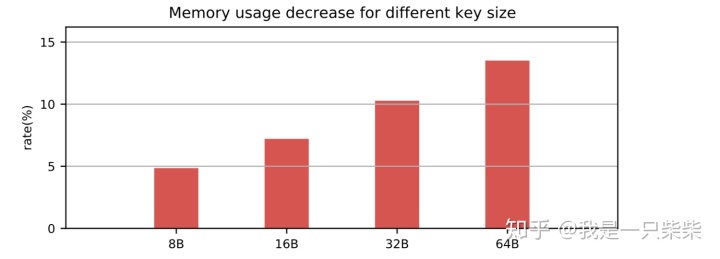
从实验结果中我们可以看出,在数据量一定的情况下,随着key长度的增加,我们设计的内存表索引的空间占用相对baseline降低的比例逐渐提升,从4.8%提升到13.5%。
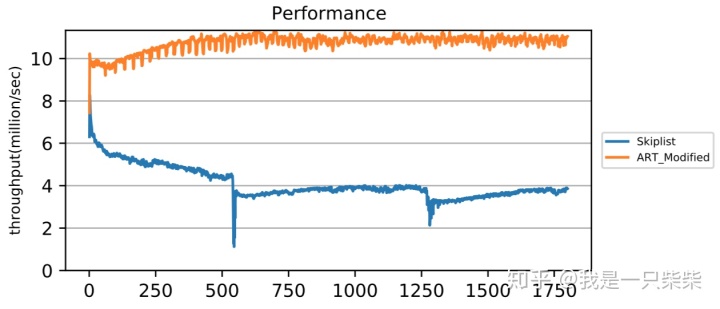
读写混合(少量数据频繁更新)
我们以基于Skiplist的内存表为baseline,使用db_bench readrandomwriterandom workload测试了我们设计的内存表索引在少量数据频繁更新的场景下的整体性能,以验证我们设计的内部自合并操作的效果。测试使用32线程压测32个subtable,key长度为16B,value长度为8B,读写比为95:5,数据量大小为2million条记录,内存表空间阈值为256M,并设置转储相关参数保证内存表被切换后立即被转储,使用4个后台线程来执行内部自合并任务,横坐标表示时间。实验结果如下图所示。
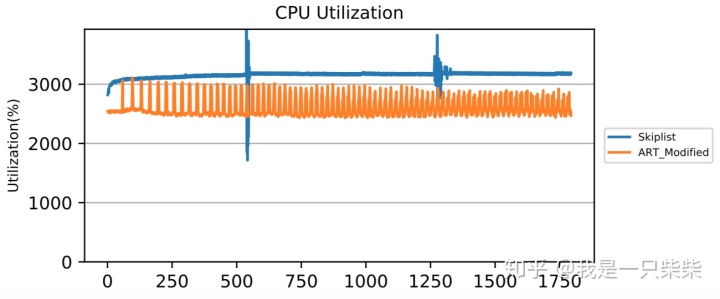
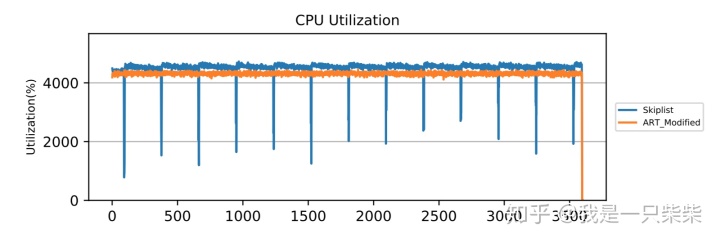
从实验结果中我们可以看出,在少量数据频繁更新的场景下,由于无法回收无效数据,baseline的内存表频繁迅速地达到空间阈值并被转储到磁盘上,造成极大的性能抖动。而我们设计的内存表索引由于采用内部自合并操作对无效数据进行及时回收,内存表的空间占用始终没有超过阈值,从而不会触发切换被转储,性能始终保持在较高的水平,仅在内部自合并操作发生时出现小幅波动。另外,由于我们设计的内存表索引,在发生读写冲突进行重做前会通过shed_yield短暂释放线程的CPU时间片来减少竞争,因此在使用相同数量的前台线程压测时,前台线程的CPU利用率比baseline更低,所以即便使用了额外的后台线程执行内部自合并操作,我们设计的内存表索引的整体CPU利用率依然低于baseline。
Macro Benchmarks
写入
改变数据量
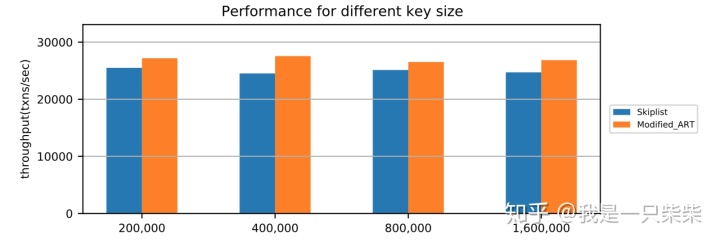
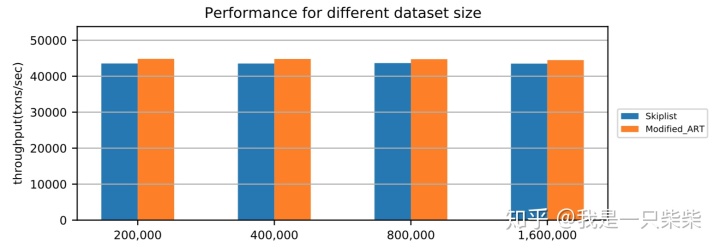
我们以基于Skiplist的内存表为baseline,使用sysbench oltp_write_only workload测试了我们设计的内存表索引的写入性能,测试使用256连接压测16个表,每个事务包含10次非索引列更新,横坐标为数据量(对应约128M-1G大小的数据量)。实验结果如下图所示。
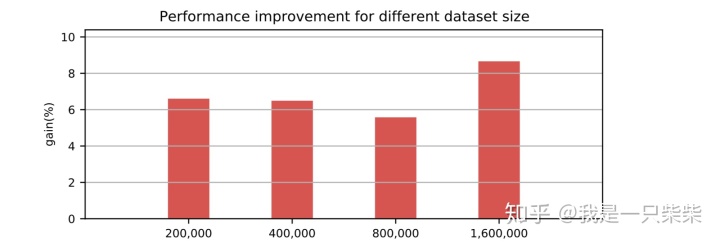
改变事务大小
我们以基于Skiplist的内存表为baseline,使用sysbench oltp_write_only workload测试了我们设计的内存表索引的写入性能,测试使用256连接压测16个表,数据量为400,000条记录(约256M数据量),横坐标为单个事务包含的非索引列更新次数。实验结果如下图所示。
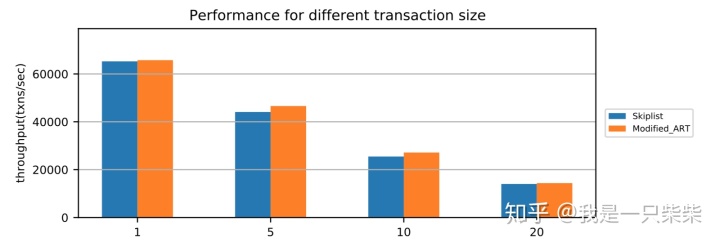
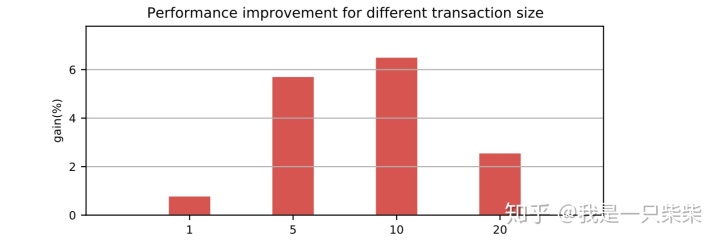
点查询
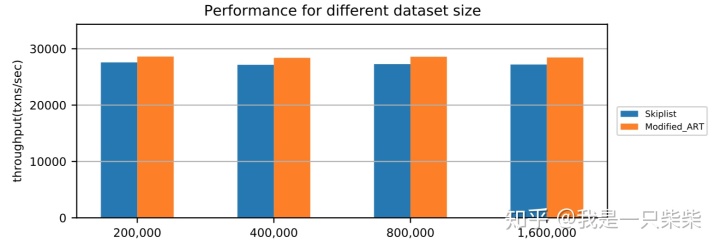
改变数据量
我们以基于Skiplist的内存表为baseline,使用sysbench oltp_read_only workload测试了我们设计的内存表索引的点查询性能,测试使用256连接压测16个表,每个事务包含10次点查询,横坐标为Memtable中key的数量(对应约128M-1G大小的数据量)。实验结果如下图所示。
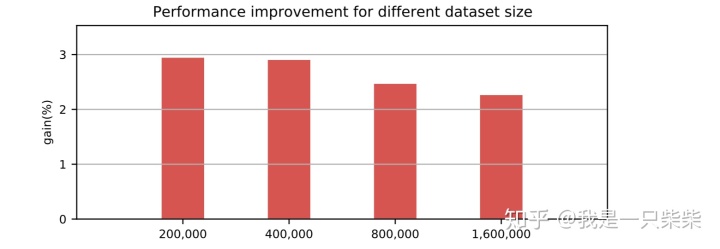
改变事务大小
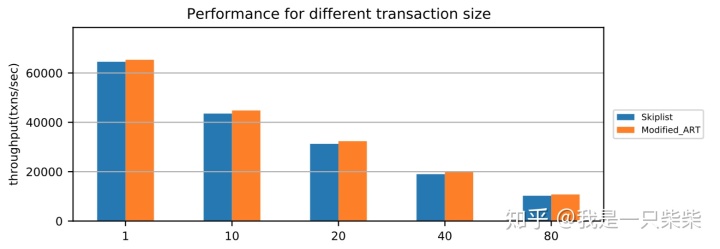
我们以基于Skiplist的内存表为baseline,使用sysbench oltp_read_only workload测试了我们设计的内存表索引的点查询性能,测试使用256连接压测16个表,每个Memtable包含400,000条记录(约256M数据量),横坐标为单个事务包含的点查询次数。实验结果如下图所示。
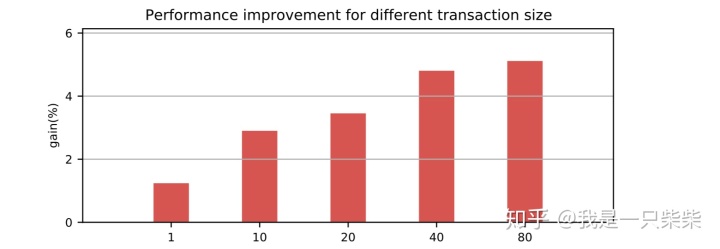
范围查询
改变数据量
我们以基于Skiplist的内存表为baseline,使用sysbench oltp_read_only workload测试了我们设计的内存表索引的范围查询性能,测试使用256连接压测16个表,每个事务包含10次范围查询,范围查询长度为20,横坐标为Memtable中key的数量(对应约128M-1G大小的数据量)。实验结果如下图所示。
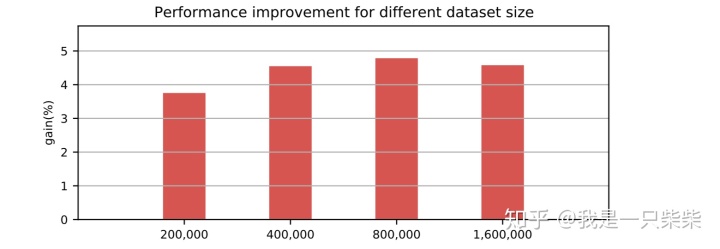
改变事务大小
我们以基于Skiplist的内存表为baseline,使用sysbench oltp_read_only workload测试了我们设计的内存表索引的范围查询性能,测试使用256连接压测16个表,每个Memtable包含400,000条记录(约256M数据量),范围查询长度为20,横坐标为单个事务包含的范围查询次数。实验结果如下图所示。
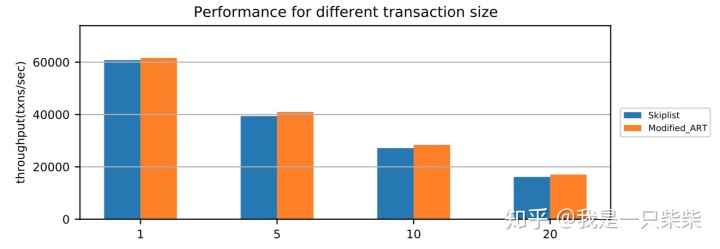
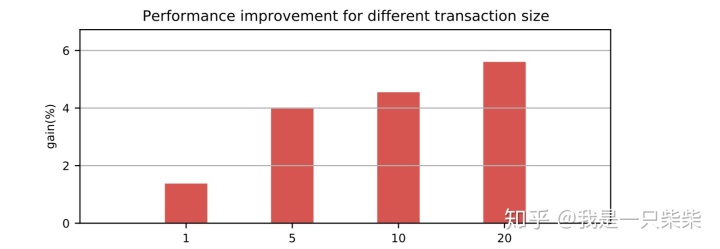
读写混合(少量数据频繁更新)
我们以基于Skiplist的内存表为baseline,使用sysbench oltp_read_write workload测试了我们设计的内存表索引在少量数据频繁更新的场景下的整体性能,以验证我们设计的内部自合并操作的效果。测试使用256连接压测16个表,每个事务包含19次点查询和一次非索引列更新,数据量大小为300,000条记录,内存表空间阈值为256M,并设置转储相关参数保证内存表被切换后立即被转储,同时禁用基线数据的compaction,避免基线数据的compaction对系统性能产生影响,使用1个后台线程来执行内部自合并任务,横坐标表示时间。实验结果如下图所示。
从实验结果中我们可以看出,在少量数据频繁更新的场景下,我们设计的内存表索引能够避免频繁的转储,使得系统整体性能稳定在一个较高的水平,且CPU利用率更低。
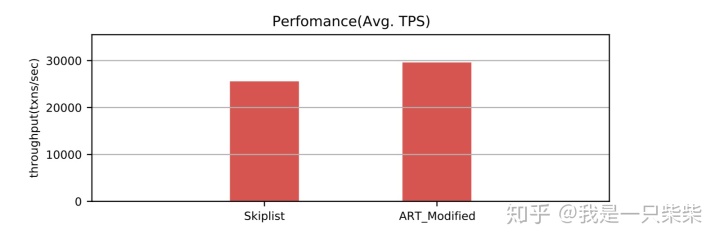
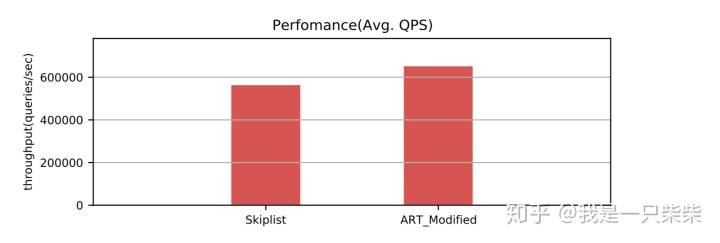
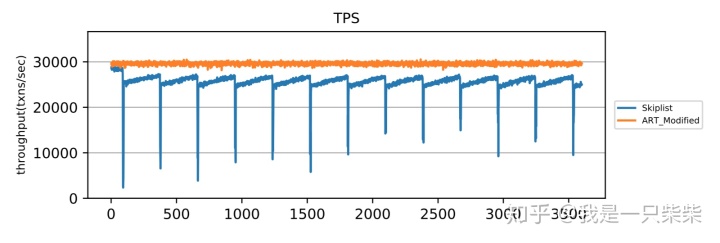
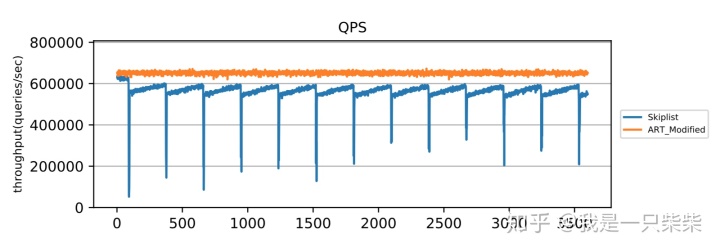
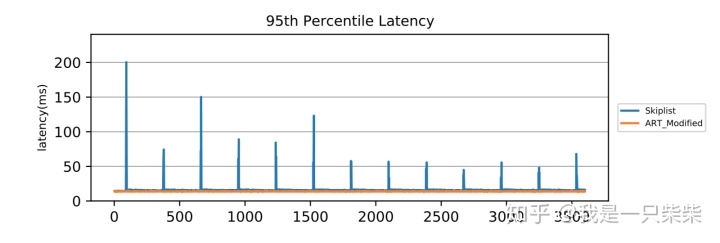
实验结果总结
从KV接口和SQL接口的实验结果我们可以看出,我们设计的内存表索引在点查询、范围查询、写入方面的性能相对baseline都有提升,且相同数据量下内存空间占用更低。最重要的是我们设计的内存表索引通过内部自合并操作及时回收无效数据,提高了内存空间的利用率,特别是在少量数据频繁进行非索引列更新的场景下,能够避免发生不必要的转储,从而减少性能抖动。
值得注意的一点是,我们设计的内存表索引虽然在KV接口的测试中性能提升十分显著,但是在SQL接口的测试中性能提升极低,原因是当查询都在内存表中命中时,内存表查询消耗的CPU cycle在系统整体消耗的CPU cycle中占比很小,因此即便我们显著地提升了内存表的性能,但是反映在SQL接口上的性能提升并不大。
例如,我们在sysbench oltp_read_only workload测试中抓取了两个CPU cycle火焰图。实验使用256连接压测16个表,每个Memtable包含400000条记录,每个事务包含一次点查询。从火焰图上看,我们设计的内存表索引查询消耗的CPU cycle占比仅2.42%,相对baseline的占比3.67%已有很大提升,但是实际性能提升并不大。
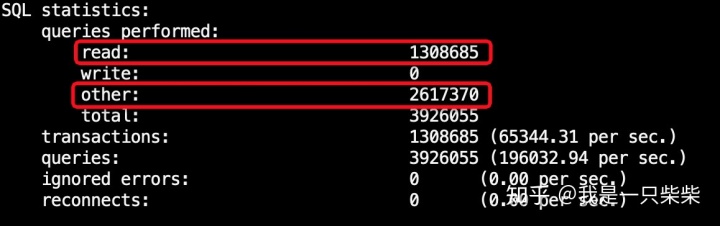
从sysbench的输出结果中我们也可以看出,锁、事务commit等语句的占比远超实际查询语句。
参考文献
[1] Viktor Leis, Florian Scheibner, Alfons Kemper, and Thomas Neumann. 2016. The ART of practical synchronization. In DaMoN.
[2] Bayer R, Schkolnick M. Concurrency of operations on B -trees[J]. Acta Informatica, 1977, 9(1):1-21.

















 1181
1181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









