





引言&目录
引言:
在 TF2.0-RNN原理和实践:循环核→循环神经网络【循环核按时间步骤打开】+字母预测实践【one-hot或Embedding】中,我们了解到了传统RNN的基本原理和组成,使用的是tf.keras.layers.SimpleRNN(),提出了SimpleRNN,tf.keras还给我们提供了另外两个可用循环层:
LSTM
GRU 问题一:SimpleRNN的弊端在哪里?我们知道ht,即循环核的状态ht,表征短期记忆,他是按照时刻更新的,从理论上来说,在时刻t,它应该能够记住许多时间步之前见过的信息,但实际上是不可能学到这种长期依赖。simpleRNN可以通过记忆体实现短期长短记忆进行连续数据的预测,但是当连续数据的序列变长时,会使展开时间步过长, 在反向传播更新参数时,梯度要按照时间步连续相乘,会导致梯度消失!
于是在1997年Hochereiter和Schmidhuber提出了LSTM长短期记忆网络——LSTM[ Long Short-Term Memory],这是研究梯度消失问题的重要成果。2014年有学者在LSTM的基础上发展出了GRU。 问题二:LSTM的原理是什么?—Ⅲ问题三:GRU的原理是什么?—Ⅳ
ps:
本文结合股票开盘价格预测实践使用了SimpleRNN,LSTM,GRU,因此先介绍实践背景
,因为只是model发生了改变,也先介绍数据的处理。
目录:
Ⅰ.实践背景介绍——股票价格预测 Ⅱ.数据处理部分——以SimpleRNN搭建模型 Ⅲ.LSTM长短期记忆网络的原理,及实验结果 Ⅳ.GRU的原理,及实验结果【数据获取和代码在文中partⅡ全有,后续只需修改model】
一、实践背景介绍——股票价格预测
实践目标:预测股票开盘价
实践数据:茅台股票2426天的开盘价(即open)数据
数据获取:直接通过第三方接口获取
# 通过Tushare获得股票价格数据,存到csv文件中import tushare as tsimport matplotlib.pyplot as pltdf1 = ts.get_k_data('600519',ktype='D',start='2010-04-26',end='2020-04-26')datapath1 = './SH600519.csv'df1.to_csv(datapath1)数据概况:
...
实践方式:共2426天的数据,
①划分训练集和测试集
训练集trainning_set:前(2426-300)个样本
测试集test_set:后300个样本
②使用前60天的开盘价预测第61天的开盘价
对于测试集:就有 2126-60 =2066组训练数据
对于训练集:就有 300-60 = 240组训练数据
③定义模型,进行训练,可视化
实践使用模型:
传统循环网络 ——SimpleRNN
长短期记忆网络 ——LSTM
简化了的LSTM ——GRU
实践结果:
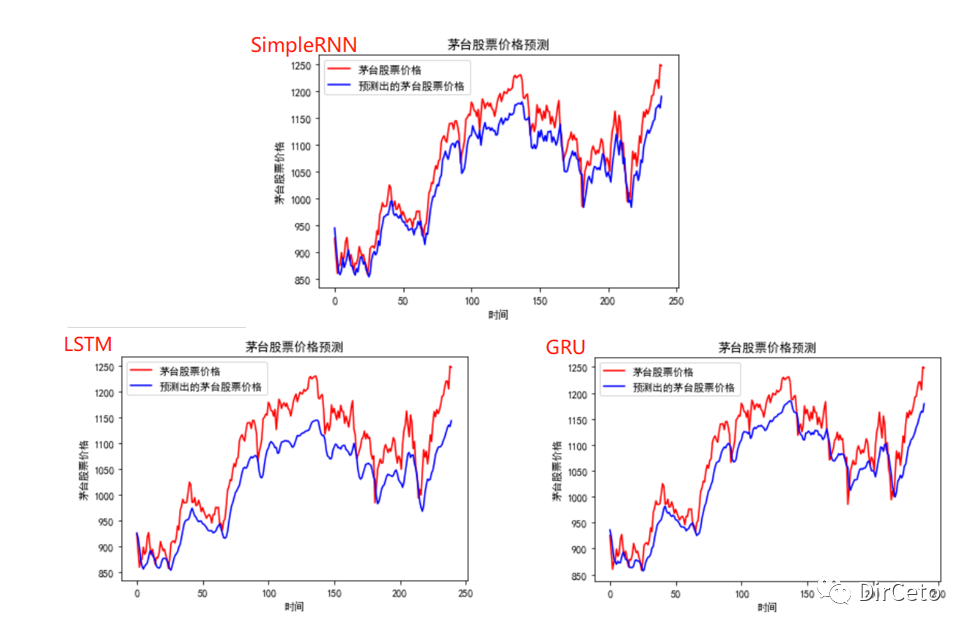
二.实验数据的预处理等内容——以SimpleRNN为例子,后不再单独写SimpleRNN
1.获得数据
# 通过Tushare获得股票价格数据,存到csv文件中import tushare as tsimport matplotlib.pyplot as pltdf1 = ts.get_k_data('600519',ktype='D',start='2010-04-26',end='2020-04-26')datapath1 = './SH600519.csv'df1.to_csv(datapath1)
2.训练集和测试集归一化和划分等处理:
# 共2427行,2426个样本,只使用每天开盘价格第[2:3]列# 将前(2426-300)个样本作为训练集# 后300个样本做测试集training_set = maotai.iloc[0:2426 - 300, 2:3].valuestest_set = maotai.iloc[2426 - 300:, 2:3].values# 归一化# 定义归一化:归一化到(0,1)之间sc = MinMaxScaler(feature_range=(0, 1))# 求得训练集的固定属性:最大值,最小值。并对训练集进行归一化#fit_transform是fit和transform的组合,既包括了训练又包含了转换。#transform()和fit_transform()二者的功能都是对数据进行某种统一处理#(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等)training_set_scaled = sc.fit_transform(training_set) # 用定义的归一化和训练集的属性对测试集也进行归一化test_set = sc.transform(test_set)# 建立空列表分别用于接收训练集输入特征,训练集标签,测试集输入特征,测试集标签x_train = []y_train = []x_test = []y_test = []# 训练集和测试集划分# 上面的到训练集:csv表格中的前2126天的数据 # 第61天的数据作为对应标签y_train,# 一共生成 2126-60 = 2066组训练数据# 遍历整个训练数据,每连续60天数据作为输入特征x_train,使用的是已经for i in range(60, len(training_set_scaled)): # 每60天作为训练数据x_train x_train.append(training_set_scaled[i - 60:i, 0]) # 第61天数据作为对应标签y_train y_train.append(training_set_scaled[i, 0])#打乱x_trainnp.random.seed(7)np.random.shuffle(x_train)np.random.seed(7)np.random.shuffle(y_train)tf.random.set_seed(7)# 将列表格式转换为arrayx_train, y_train = np.array(x_train), np.array(y_train)#RNN所需格式#[样本个数,循环核时间展开步数,每个时间步输入特征个数]# 样本个数:每次输入的是60天的,x_train中有2066组,# 循环核时间展开步数:输入60天即60时间步# 每个时间步输入特征个数:只输入开盘价 为1x_train = np.reshape(x_train, (x_train.shape[0], 60, 1))# 测试集:300-60 =240组for i in range(60, len(test_set)): x_test.append(test_set[i - 60:i, 0]) y_test.append(test_set[i, 0])x_test, y_test = np.array(x_test), np.array(y_test)x_test = np.reshape(x_test, (x_test.shape[0], 60, 1))3.建模:以SimpleRNN为例子
# 建模model = tf.keras.Sequential([ # 第一层循环计算层:记忆体80个,每个时间步推送ht给下一层 SimpleRNN(80,return_sequences = True), Dropout(0.2), # 最后一个循环计算层 都用False ,其之前的每一个都设置为T SimpleRNN(100), Dropout(0.2), # 因输出值是第61天的开盘价,只有一个值,所以Dense是1 Dense(1)])4.训练,模型存储,参数存储:
# 优化器adam ,损失函数:均方误差[回归常用]# 该应用只关注Loss值,不关注准确值,所以没有输入metrics选项,只显示loss值model.compile(optimizer=tf.keras.optimizers.Adam(0.001), loss='mean_squared_error') checkpoint_save_path = "./checkpoint/rnn_stock.ckpt"if os.path.exists(checkpoint_save_path + '.index'): print('-------------加载模型----------------') model.load_weights(checkpoint_save_path) cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path, save_weights_only=True, save_best_only=True, monitor='val_loss')history = model.fit(x_train, y_train, batch_size=64, epochs=50, validation_data=(x_test, y_test), validation_freq=1, callbacks=[cp_callback])model.summary()# 参数提取file = open('./weights.txt', 'w') for v in model.trainable_variables: file.write(str(v.name) + '\n') file.write(str(v.shape) + '\n') file.write(str(v.numpy()) + '\n')file.close()
5.loss可视化
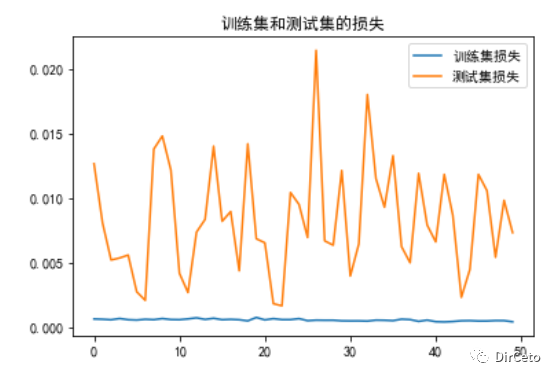
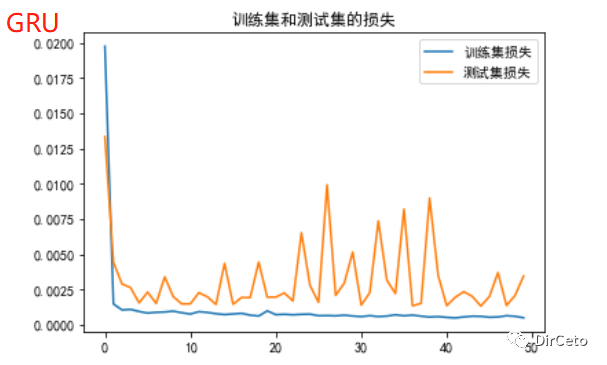
plt.rcParams['font.sans-serif'] = ['SimHei']loss = history.history['loss']val_loss = history.history['val_loss']plt.plot(loss, label='训练集损失')plt.plot(val_loss, label='测试集损失')plt.title('训练集和测试集的损失')plt.legend()plt.show()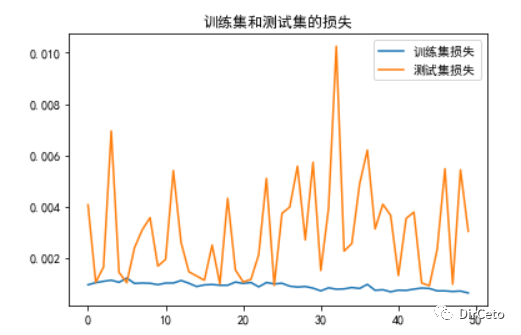
6.预测——归一化还原
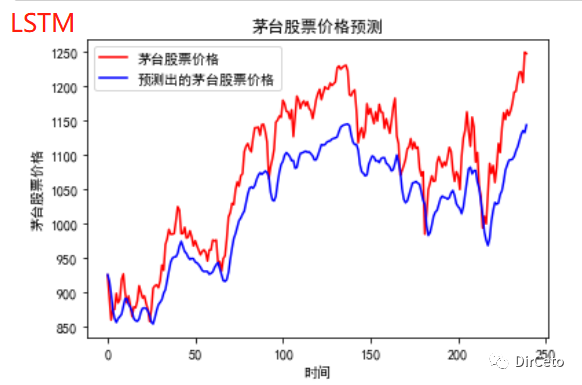
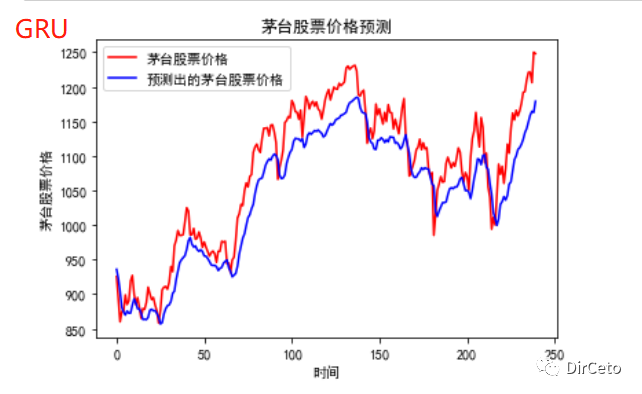
# 预测# 测试集输入模型进行预测predicted_stock_price = model.predict(x_test)# 对预测数据还原---从(0,1)反归一化到原始范围predicted_stock_price = sc.inverse_transform(predicted_stock_price)# 对真实数据还原---从(0,1)反归一化到原始范围real_stock_price = sc.inverse_transform(test_set[60:])# 画出真实数据和预测数据的对比曲线plt.plot(real_stock_price, color='red', label='茅台股票价格')plt.plot(predicted_stock_price, color='blue', label='预测出的茅台股票价格')plt.title('茅台股票价格预测')plt.xlabel('时间')plt.ylabel('茅台股票价格')plt.legend()plt.show()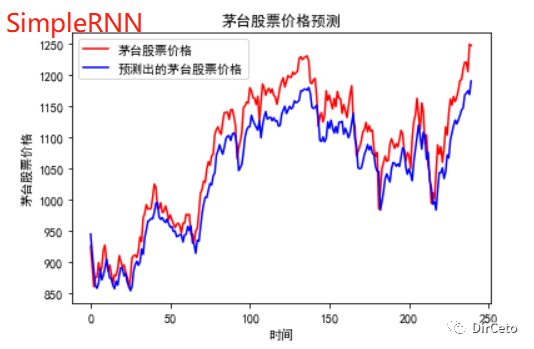
7.评价——误差
# 评价:误差越小越好# MSE 均方误差 ---> E[(预测值-真实值)^2] (预测值减真实值求平方后求均值)mse = mean_squared_error(predicted_stock_price, real_stock_price)# RMSE 均方根误差--->sqrt[MSE] (对均方误差开方)rmse = math.sqrt(mean_squared_error(predicted_stock_price, real_stock_price))# MAE 平均绝对误差----->E[|预测值-真实值|](预测值减真实值求绝对值后求均值)mae = mean_absolute_error(predicted_stock_price, real_stock_price)print('均方误差: %.6f' % mse)print('均方根误差: %.6f' % rmse)print('平均绝对误差: %.6f' % mae)
3.LSTM的原理与实现
1997年提出了长短记忆网络LSTM: 通过门控单元改善了RNN长期依赖问题 一.原理: 提出了三个 门限 : 输入门it,遗忘门ft,输出门ot 引入了 表征长期记忆 的 细胞态 : Ct 引入了 等待存入长期记忆 的 候选态 : Ct~
①三个门限:
都是当前时刻的输入特征xt和上一个时刻的短期记忆ht-1的函数。 Wi,Wf,Wo是待训练参数矩阵,bi,bf,bo是待训练偏置项。 都经过sigmoid激活函数,使得门限的范围在0~1之间②细胞态Ct:表示长期记忆
等于 上个时期的长期记忆* 遗忘门ft,加上当前时刻归纳出的新知识*输入门③记忆体ht:表示短期记忆
是 长期记忆的一部分,是 细胞态经tanh激活函数* 输入门的结果④候选态:表示归纳出的带存入细胞态的新知识
是 当前的输入特征xt和 上个时刻的短期记忆ht-1的函数,Wc是带训练参数矩阵,bc是待训练偏置项ok,我们可以这么理解:
假设, 今天我学了10页PPT的内容,从第1页到第10页,此时此我正在学习第10页。我假设我学习一页PPT代表一个时刻,学到第10页,我的长期记忆C10:第1页到第10页PPT的内容。这个长期记忆由两部分组成: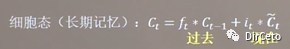
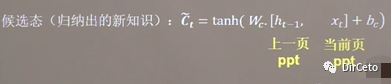 现在的记忆*输入门+过去的记忆→一同存储为长期记忆
现在的记忆*输入门+过去的记忆→一同存储为长期记忆
当我把今天学习到的知识,分享给别的同学的时候,我就在输出了!我肯定不能做到一字不落的讲出来,我讲的东西一定是我的长期记忆C10经过输出门Ot筛选后的内容,就好比我在写文章总结内容给同学分享。这就是记忆体的输出h10。

tf.keras.layers.LSTM(记忆体个数,return_sequence =是否返回输出)model = tf.keras.Sequential([ LSTM(80, return_sequences=True), Dropout(0.2), LSTM(100), Dropout(0.2), Dense(1)])

4.GRU-简化了的LSTM结构
一.原理:
GRU使记忆体ht融合了长期记忆和短期记忆更新门:zt
重置门:rt
两个门限的取值范围:0~1
记忆体:ht =(1-zt)*ht-1 + zt*ht~
ht包含了过去记忆ht-1和现在信息ht~
现在信息ht~:是过去信息ht-1过重置门rt与当前输入xt共同决定、过激活函数tanh
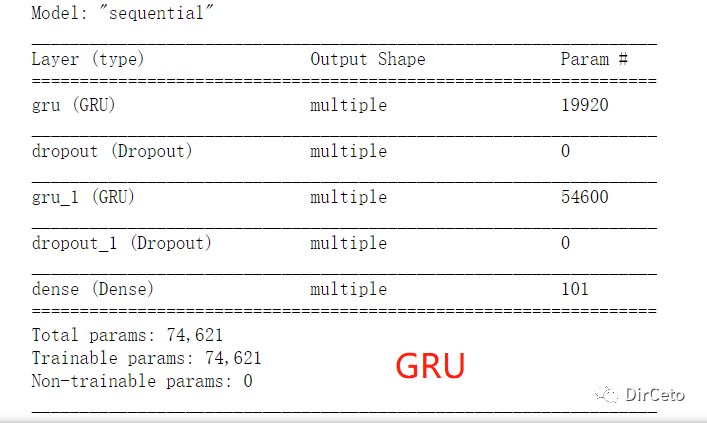
二.TF2.0实现:
tf.keras.layers.GRU(记忆体个数,return_sequence =是否返回输出)股票预测实例中,只修改了Model即可:

谢谢阅读!

















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









