



 本文介绍了Spark的基础知识,包括安装配置、主要抽象RDD的概念及操作示例,同时提供了Scala和Java版本的入门示例。此外,还介绍了Spark Streaming的原理和使用方法,包括实时流数据处理的基本流程。
本文介绍了Spark的基础知识,包括安装配置、主要抽象RDD的概念及操作示例,同时提供了Scala和Java版本的入门示例。此外,还介绍了Spark Streaming的原理和使用方法,包括实时流数据处理的基本流程。
一、Spark入门
Spark是开源类Hadoop MapReduce的通用并行框架。
Spark拥有HadoopMapReduce所具有的优点,但不同于MapReduce的是,Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此,Spark能更好地适用于数据挖掘与机器学习等需要迭代的场景
1. Spark概述
Spark是一种与Hadoop相似的开源集群计算环境,但是两者之间还是存在一些不同之处的,这些不同之处使Spark在某些工作负载方面表现得更加优越。
Spark启用了内存分布数据集,除了能够提供交互式查询外,还可以优化迭代工作负载。
Spark是在Scala语言中实现的,它将Scala用作其应用程序框架。
与Hadoop不同,Spark和Scala能够紧密集成,其中的Scala可以像操作本地集合对象一样轻松地操作分布式数据集。
2. Spark伪分布式安装
安装Scala
解压:
# 传到目录/usr/localcd /usr/localtar -xvf scala-2.11.8.tgzmv scala-2.11.8scala配置环境变量
vim /etc/profile# 添加以下内容export SCALA_HOME=/usr/local/scalaexport PATH=$SCALA_HOME/bin# 通过以下命令使环境变量立即生效source /etc/profile下载:https://www.scala-lang.org/download/2.11.8.html
安装Spark
下载:https://www.apache.org/dyn/closer.lua/spark/spark-2.3.2/spark-2.3.2-bin-hadoop2.7.tgz
解压
配置环境变量
vim /etc/profile# 添加以下内容export SPARK_HOME=/usr/local/scalaexport PATH=$SPARK_HOME/bin# 通过以下命令使环境变量立即生效source /etc/profile
配置spark
# 切换到Spark配置文件目录,复制模板并修改其中的配置文件slaves、spark-env.sh、spark-defaults.confcd /usr/local/spark/confcp slaves.template slavescp spark-env.sh.template spark-env.shcp spark-defaults.conf.template spark-defaults.conf# 1vim slaves# 修改localhost为hadoop0# 2vim spark-env.sh# 追加以下内容export JAVA_HOME=/usr/local/jdkexport SCALA_HOME=/usr/local/scalaexport HADO0P_HOME=/usr/local/hadoopexport HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoopexport SPARK_MASTER_HOST=hadoop0export SPARK_PID_DIR=/usr/local/spark/data/pidexport SPARK_LOCAL_DIRS=/usr/local/spark/data/spark_shuffleexport SPARK_EXECUTOR_MEMORY=1Gexport SPARK_WORKER_MEMORY=4G# 3vim spark-defaults.confspark.master spark://hadoop0:7077spark.eventLog.enabled truespark.eventLog.dirhdfs://hadoop0:9000/eventLogspark.serializerorg.apache.spark.serializer.KryoSerializerspark.driver.memory1gspark.jars.packagesAzure:mmlspark:0.12slaves
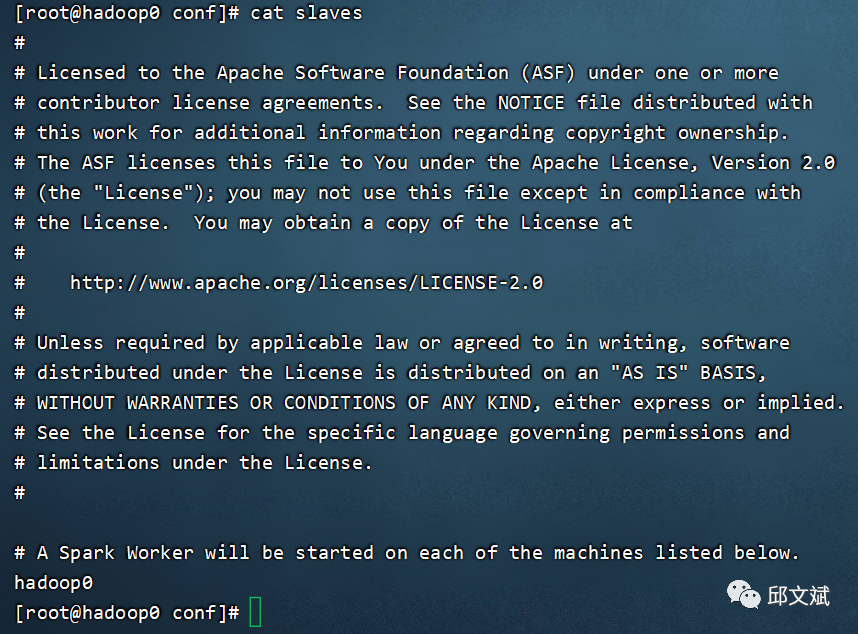
spark-env.sh
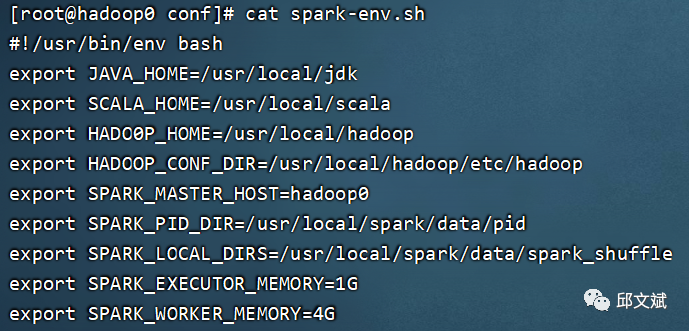
spark-defaults
配置中要使用hdfs://hadoop0:9000/eventLog来存放日志,我们需要手动创建这个目录
hadoop fs -mkdir /eventLog
测试Spark(启动Spark之前要启动Hadoop)
/usr/local/spark/sbin/start-all.sh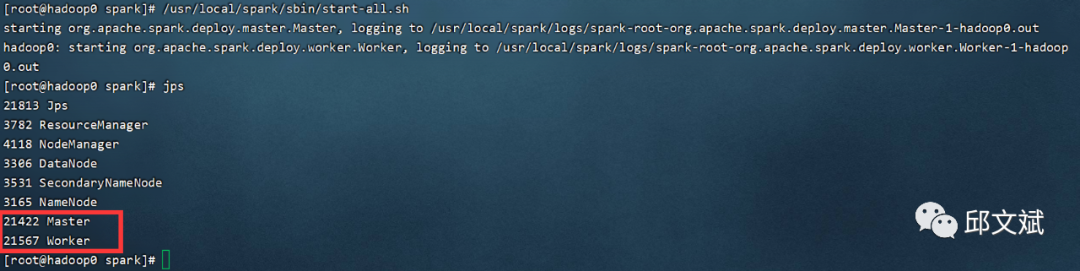
在
./examples/src/main目录下有一些Spark的示例程序,包括Scala、Java、Python、R等语言的版本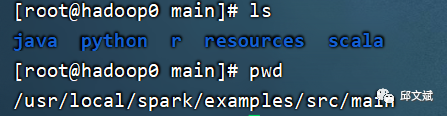
通过
spark-shell命令启动Spark Shell可以 通过访问
http://hadoop0:4040和http://hadoop0:8080两个URL来查看Spark的运行状态/usr/local/spark/bin/run-example SparkPi

3. 由Java到Scala
Spark内存计算框架由Scala语言编写,其交互式环境也支持直接编写Scala表达式来进行数据操作,因此在介绍Spark之前,首先来了解Scala和Java的区别。
Scala是一门多范式的编程语言,一种类似Java的编程语言,设计初衷是实现可伸缩的语言,并集成面向对象编程和函数式编程的各种特性。
Scala具备如下的核心特征
Scala中的每个值都是一个对象,包括基本数据类型(即布尔值、数字等)在内,连函数也是对象。
与只支持单继承的语言相比,Scala具有更广泛意义上的类重用。Scala允许定义新类的时候重用“一个类中新增的成员定义”。
Scala还包含若干函数式语言的关键概念,包括高阶函数、局部套用、嵌套函数、序列解读等。
Scala是静态类型的,这就允许它提供泛型类、内部类,甚至多态方法。
Scala可以与Java互操作。用scalac这个编译器把源文件编译成Java的class文件,可以从Scala中调用所有的Java类库,也同样可以从Java应用程序中调用Scala的代码。
Scala 数据类型
Scala 与 Java有着相同的数据类型,下表列出了 Scala 支持的数据类型:
| 数据类型 | 描述 |
|---|---|
| Byte | 8位有符号补码整数。数值区间为 -128 到 127 |
| Short | 16位有符号补码整数。数值区间为 -32768 到 32767 |
| Int | 32位有符号补码整数。数值区间为 -2147483648 到 2147483647 |
| Long | 64位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807 |
| Float | 32 位, IEEE 754 标准的单精度浮点数 |
| Double | 64 位 IEEE 754 标准的双精度浮点数 |
| Char | 16位无符号Unicode字符, 区间值为 U+0000 到 U+FFFF |
| String | 字符序列 |
| Boolean | true或false |
| Unit | 表示无值,和其他语言中void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()。 |
| Null | null 或空引用 |
| Nothing | Nothing类型在Scala的类层级的最底端;它是任何其他类型的子类型。 |
| Any | Any是所有其他类的超类 |
| AnyRef | AnyRef类是Scala里所有引用类(reference class)的基类 |
Scala 基础字面量
Scala 非常简单且直观。接下来我们会详细介绍 Scala 字面量。
整型字面量
整型字面量用于 Int 类型,如果表示 Long,可以在数字后面添加 L 或者小写 l 作为后缀。:
003521 0xFFFFFFFF 0777L浮点型字面量
如果浮点数后面有f或者F后缀时,表示这是一个Float类型,否则就是一个Double类型的。实例如下:
0.0 1e30f 3.14159f 1.0e100.1布尔型字面量
布尔型字面量有 true 和 false。
符号字面量
符号字面量被写成:' ,这里 可以是任何字母或数字的标识(注意:不能以数字开头)。这种字面量被映射成预定义类scala.Symbol的实例。
如:符号字面量 'x 是表达式 scala.Symbol("x") 的简写,符号字面量定义如下:
package scalafinal case class Symbol private (name: String) { override def toString: String = "'" + name}字符字面量
在 Scala 字符变量使用单引号 ' 来定义,如下:
'a' '\u0041''\n''\t'其中 ** 表示转义字符,其后可以跟 u0041** 数字或者 \r\n 等固定的转义字符。
字符串字面量
在 Scala 字符串字面量使用双引号 " 来定义,如下:
"Hello,\nWorld!""菜鸟教程官网:www.runoob.com"多行字符串的表示方法
多行字符串用三个双引号来表示分隔符,格式为:""" ... """。
实例如下:
val foo = """菜鸟教程www.runoob.comwww.w3cschool.ccwww.runnoob.com以上三个地址都能访问"""Null 值
空值是 scala.Null 类型。
Scala.Null和scala.Nothing是用统一的方式处理Scala面向对象类型系统的某些"边界情况"的特殊类型。
Null类是null引用对象的类型,它是每个引用类(继承自AnyRef的类)的子类。Null不兼容值类型。
Scala 转义字符
下表列出了常见的转义字符:
| 转义字符 | Unicode | 描述 |
|---|---|---|
| \b | \u0008 | 退格(BS) ,将当前位置移到前一列 |
| \t | \u0009 | 水平制表(HT) (跳到下一个TAB位置) |
| \n | \u000a | 换行(LF) ,将当前位置移到下一行开头 |
| \f | \u000c | 换页(FF),将当前位置移到下页开头 |
| \r | \u000d | 回车(CR) ,将当前位置移到本行开头 |
| " | \u0022 | 代表一个双引号(")字符 |
| ' | \u0027 | 代表一个单引号(')字符 |
| \ | \u005c | 代表一个反斜线字符 '' |
object Test { def main(args: Array[String]) { println("Hello\tWorld\n\n" ); }}$ scalac Test.scala$ scala TestHello WorldScala 变量
变量是一种使用方便的占位符,用于引用计算机内存地址,变量创建后会占用一定的内存空间。
基于变量的数据类型,操作系统会进行内存分配并且决定什么将被储存在保留内存中。因此,通过给变量分配不同的数据类型,你可以在这些变量中存储整数,小数或者字母。
变量声明
在学习如何声明变量与常量之前,我们先来了解一些变量与常量。
变量:在程序运行过程中其值可能发生改变的量叫做变量。如:时间,年龄。
常量 在程序运行过程中其值不会发生变化的量叫做常量。如:数值 3,字符'A'。
在 Scala 中,使用关键词 "var" 声明变量,使用关键词 "val" 声明常量。
声明变量实例如下:
var myVar : String = "Foo"var myVar : String = "Too"以上定义了变量 myVar,我们可以修改它。
声明常量实例如下:
val myVal : String = "Foo"以上定义了常量 myVal,它是不能修改的。如果程序尝试修改常量 myVal 的值,程序将会在编译时报错。
变量类型声明
变量的类型在变量名之后等号之前声明。定义变量的类型的语法格式如下:
var VariableName : DataType [= Initial Value]// 或val VariableName : DataType [= Initial Value]Scala 多个变量声明
Scala 支持多个变量的声明:
// xmax, ymax都声明为100val xmax, ymax = 100 //如果方法返回值是元组,我们可以使用 val 来声明一个元组:scala> val pa = (40,"Foo")pa: (Int, String) = (40,Foo)Scala 闭包
闭包是一个函数,返回值依赖于声明在函数外部的一个或多个变量。
闭包通常来讲可以简单的认为是可以访问一个函数里面局部变量的另外一个函数。
如下面这段匿名的函数:
val multiplier = (i:Int) => i * 10 函数体内有一个变量 i,它作为函数的一个参数。如下面的另一段代码:
val multiplier = (i:Int) => i * factor在 multiplier 中有两个变量:i 和 factor。其中的一个 i 是函数的形式参数,在 multiplier 函数被调用时,i 被赋予一个新的值。然而,factor不是形式参数,而是自由变量,考虑下面代码:
var factor = 3 val multiplier = (i:Int) => i * factor 这里我们引入一个自由变量 factor,这个变量定义在函数外面。
这样定义的函数变量 multiplier 成为一个"闭包",因为它引用到函数外面定义的变量,定义这个函数的过程是将这个自由变量捕获而构成一个封闭的函数。
object Test { def main(args: Array[String]) { println( "muliplier(1) value = " + multiplier(1) ) println( "muliplier(2) value = " + multiplier(2) ) } var factor = 3 val multiplier = (i:Int) => i * factor }$ scalac Test.scala $ scala Test muliplier(1) value = 3 muliplier(2) value = 6 4. Spark架构
Spark遵循主从架构。它的集群由一个主服务器和多个从服务器组成。
Spark架构依赖于两个抽象:
弹性分布式数据集(RDD)
有向无环图(DAG)
RDD
Spark的主要抽象是分布式的元素集合,称为弹性分布式数据集(ResilientDistributedDataset,RDD),它可被分发到集群的各个节点上进行并行操作。
RDD可以通过Hadoop InputFormats创建(如HDFS),或者从其他RDD转化而来。
从Spark的./README文件新建一个RDD:
scala> var textFile = sc.textFile("file:///usr/local/spark/README.md")textFile: org.apache.spark.rdd.RDD[String] = file:///usr/local/spark/README.md MapPartitionsRDD[1] at textFile at :24scala> textFile.count()res10: Long = 103 file://前缀指定读取本地文件Spark Shell默认是读取HDFS中的文件,需要先上传文件到HDFS中,否则会有
org.apache.hadoop.mapred.InvalidInputException:Input path does notexist的错误提示
RDD是一种特殊集合,支持多种来源,有容错机制,可以被缓存,支持并行操作,一个RDD代表一个分区里的数据集。
RDD有两种操作算子:
Transformation(转换):Transformation属于延迟计算,当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住了数据集的逻辑操作。Transformations操作是Lazy懒加载的,不是立刻执行,只会记录需要这样的操作,需要等到有Actions操作的时候才会真正启动计算过程进行计算。
Ation(执行):触发Spark作业的运行,真正触发转换算子的计算。Actions操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。
# filter提供了一个元素过滤器,只有符合过滤条件的元素才会被包含到新集合中val linesWithSpark = textFile.filter(line => line.contains("Spark"))# 文件中含有Spark的内容行数linesWithSpark.count()# 找到包含单词最多的那一行内容共有多少个单词textFile.map(line => line.split(" ").size).reduce((a,b) => if(a>b) a else b)# 统计包含单词最多的那一行内容共有多少个单词,使用Math.max()函数(需要导入Java的Math库)textFile.map(line => line.split(" ").size).reduce((a,b) => Math.max(a,b))# 数据流模式单词数统计val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey((a, b) =>a + b)wordCounts.collect常用的Spark函数
| 转换 | 作用 |
|---|---|
| reduce(func) | 通过函数func聚集数据集中的所有元素。func函数接收两个参数,返回一个值。这个函数必须是关联性的,确保可以被正确地并发执行 |
| collect() | 在 Driver的程序中,以数组的形式返回数据集的所有元素。这通常会在使用filter或者其他操作后,返回一个足够小的数据子集再使用,直接将整个RDD集Collect返回,很可能会让 Driver程序OOM |
| count() | 返回数据集的元素个数 |
| take(n) | 返回一个数组,由数据集的前n个元素组成。注意:这个操作目前并非在多个节点上并行执行,而是 Driver程序所在机器,单机计算所有的元素(Gateway的内存压力会增大,需要谨慎使用) |
| first() | 返回数据集的第一个元素,类似于take(1) |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到本地文件系统、HDFS或者任何其他Hadoop支持的文件系统。Spark将调用每个元素的toString方法,并将它转换为文件中的一行文本 |
| saveAsSequenceFile(path) | 将数据集的元素以sequencefile的格式保存到指定的目录、本地系统、HDFS或者任何其他Hadoop支持的文件系统。RDD的元素必须由key-value对组成,并都实现了Hadoop的Writable接口,或隐式可以转换为Writable ( Spark包括基本类型的转换,例如 Int、Double、String 等) |
| foreach(func) | 在数据集的每一个元素上运行函数func。这通常用于更新一个累加器变量或者与外部存储系统进行交互 |
一个基本的RDD transformations示例
RDD包含{1, 2, 3, 3},transformations操作示例
| 函数名 | 功能 | 例子 | 结果 |
|---|---|---|---|
| map() | 对每个元素应用函数 | rdd.map(x => x+1) | {2,3,4,4} |
| flatMap() | 压扁,常用来抽取单词 | rdd.flatMap(x => x.to(3)) | {1,2,3,2,3,3,3} |
| filter() | 过滤 | rdd.filter(x => x!=1) | {2,3,3} |
| distinct() | 去重 | rdd.distinct() | {1,2,3} |
RDD transformations也支持两个RDD的集合操作。一个RDD包含{1, 2, 3},另一个RDD包含{3, 4, 5}
| 函数名 | 功能 | 例子 | 结果 |
|---|---|---|---|
| union() | 并集 | rdd.union(other) | {1,2,3,4,5} |
| intersection() | 交集 | rdd.intersection(other) | {3} |
| subtract() | 取存在第一个RDD而不存在第二个RDD的元素(使用场景,机器学习中,移除训练集) | rdd.subtract(other) | {1,2} |
| cartesian() | 笛卡尔积 | rdd.cartesian(other) | {(1,3),(1,4),...(3,5)} |
RDD action操作,RDD包含{1, 2, 3, 3}
| 函数名 | 功能 | 例子 | 结果 |
|---|---|---|---|
| collect() | 返回RDD的所有元素 | rdd.collect() | {1,2,3,3} |
| count() | 计数 | rdd.count() | 4 |
| countByValue() | 返回一个map,表示唯一元素出现的个数 | rdd.countByValue() | {(1,1),(2,1),(3,2)} |
| take(num) | 返回几个元素 | rdd.take(2) | {1,2} |
| top(num) | 返回前几个元素 | rdd.top(2) | {3,3} |
| reduce(func) | 合并RDD中元素 | rdd.reduce((x,y) => x+y) | 9 |
| foreach(func) | 对RDD的每个元素作用函数,什么也不返回 | rdd.foreach(func) | 什么也没有 |
5.Spark入门示例
Scala版
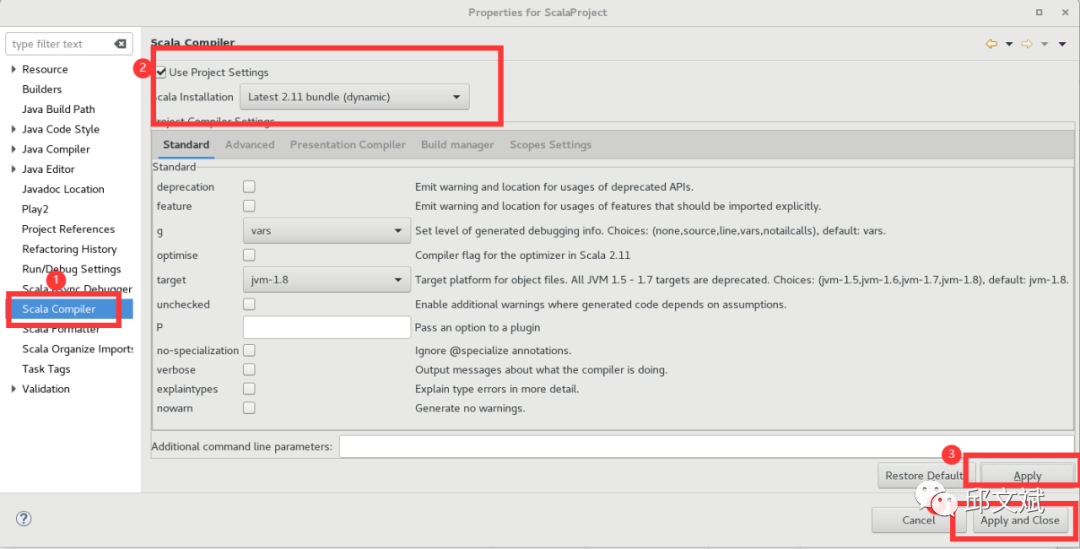
package cn.waqwbimport org.apache.spark.SparkContextimport org.apache.spark.SparkContext._import org.apache.spark.SparkConf/** * Spark入门示例Scala版 */object SimpleApp { def main(args: Array[String]) { //val logFile = "hdfs://hadoop0:9000/README.md"; val logFile = "file:///usr/local/spark/README.md"; val conf = new SparkConf().setAppName("Simple Application").setMaster("local") val sc = new SparkContext(conf) val logData = sc.textFile(logFile, 2).cache() val numAs = logData.filter(line => line.contains("a")).count() val numBs = logData.filter(line => line.contains("b")).count() println("含有字母a: %s行, 含有字母b: %s行".format(numAs, numBs)) }}需要导入
/usr/local/spark/jars目录下所有的jar包更改scala编译版本
Java版
package cn.waqwb;import org.apache.spark.api.java.*;import org.apache.spark.SparkConf;import org.apache.spark.api.java.function.Function;public class SimpleApp { public static void main(String[] args) { String logFile = "hdfs://hadoop0:9000/README.md"; // String logFile = "file:///usr/local/spark/README.md"; SparkConf conf = new SparkConf().setAppName("Simple Application").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> logData = sc.textFile(logFile).cache(); long numAs = logData.filter(new Function<String, Boolean>() { public Boolean call(String s) { return s.contains("a"); } }).count(); long numBs = logData.filter(new Function<String, Boolean>() { public Boolean call(String s) { return s.contains("b"); } }).count(); System.out.println("字母a共有 " + numAs + "行,字母b共有" + numBs+"行");}}
二、Spark Streaming
Spark Streaming是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统。
1. Spark Streaming概述
Spark的各个子框架都是基于核心Spark的,Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
SparkStream术语定义如下
(1)离散流(discretized stream)或DStream:这是Spark Streaming对内部持续的实时数据流的抽象描述。
(2)批数据(batch data):将实时流数据以时间片为单位进行分批,将流处理转化为时间片数据的批处理。
(3)时间片或批处理时间间隔(batch interval):以时间片作为拆分流数据的依据。一个时间片的数据对应一个RDD实例。
(4)窗口长度(window length):一个窗口覆盖的流数据的时间长度。必须是批处理时间间隔的倍数。
(5)滑动时间间隔:前一个窗口到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数。
(6)Input DStream:一个Input DStream是一个特殊的DStream,将SparkStreaming连接到一个外部数据源来读取数据。
2. Spark Streaming示例
作为构建于Spark之上的应用框架,Spark Streaming承袭了Spark的编程风格,对于已经了解Spark的用户来说能够快速地上手。接下来以Spark Streaming官方提供的WordCount代码为例,介绍Spark Streaming的使用方式。
新建一个网络模拟器类
NetSimulation.scala,其作用是读取/usr/local/spark/README.md文件,接受客户端连接,每秒从文件中随机选取一行内容,发往客户端。再由客户端对接收到的内容作单词计数的统计。package cn.waqwb/** * 网络模拟器类 * 读取/usr/local/spark/README.md文件,接受客户端连接, * 每秒从文件中随机选取一行内容,发往客户端。 * 再由客户端对接收到的内容作单词计数的统计 */import java.io.{ PrintWriter }import java.net.ServerSocketimport scala.io.Sourceobject NetSimulation { //产生随机数 def randomIndex(length: Int) = { import java.util.Random val rdm = new Random rdm.nextInt(length) } def main(args: Array[String]): Unit = { //读取文件 val filename = "/usr/local/spark/README.md" val lines = Source.fromFile(filename).getLines.toList val filerow = lines.length //监听端口9999 val serverSocket = new ServerSocket(9999) while (true) { //对每个客户端产生一个新的线程 val socket = serverSocket.accept() new Thread() { override def run = { println("获取到的客户段的连接:" + socket.getInetAddress) val out = new PrintWriter(socket.getOutputStream(), true) while (true) { //每隔1s,发送文件中的随机一行内容 Thread.sleep(1000) val content = lines(randomIndex(filerow)) println(content) out.write(content + "\n") out.flush() } socket.close() } }.start() } }}
新建客户端程序
NetworkWordCount.scala,其作用是建立StreamingContext,每秒钟从主机hadoop0的9999端口读取一次网络数据,然后对接收到的数据,统计每个单词的出现次数。package cn.waqwbimport org.apache.spark.SparkConfimport org.apache.spark.streaming.{ Seconds, StreamingContext }import org.apache.spark.storage.StorageLevelobject NetworkWordCount { def main(args: Array[String]) { //创建一个具有两个工作线程和1秒批处理间隔的本地StreamingContext // 主机需要2个内核 val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, Seconds(1)) // 创建将连接到的数据流主机名:端口, localhost:9999 val lines = ssc.socketTextStream("hadoop0", 9999) // 切割每一行分成几个字 val words = lines.flatMap(_.split(" ")) import org.apache.spark.streaming.StreamingContext._ // 统计每批中的每一个单词 val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_ + _) // 将此数据流中生成的每个RDD的前10个元素打印到控制台 wordCounts.print() //开始计算 ssc.start() //等待计算终止 ssc.awaitTermination() }}程序的执行流程解析如下
创建StreamingContext对象
使用Spark Streaming就需要创建StreamingContext对象。创建StreamingContext对象所需的参数与SparkContext基本一致,包括指明Master、设定名称。需要注意的是参数Seconds(1),Spark Streaming需要指定处理数据的时间间隔,如上例所示的1秒,那么Spark Streaming会以1秒为时间窗口进行数据处理。此参数需要根据用户的需求和集群的处理能力进行适当的设置。
创建InputDStream
Spark Streaming需要指明数据源。如上例所示的SocketTextStream,SparkStreaming以Socket连接作为数据源读取数据。当然,Spark Streaming支持多种不同的数据源,包括Kafka、Flume、HDFS/S3、Kinesis和Twitter等。
操作DStream
对于从数据源得到的DStream,用户可以在其基础上进行各种操作,如上例所示的操作就是一个典型的WordCount执行流程:对于当前时间窗口内从数据源得到的数据首先进行分割,然后利用Map和ReduceByKey方法进行计算,最后使用print()方法输出结果。
启动Spark Streaming
之前进行的所有步骤只是创建了执行流程,程序没有真正连接上数据源,也没有对数据进行任何操作,只是设定好了所有的执行计划,当ssc.start()启动后程序才真正进行所有预期的操作。运行程序,首先要将
/usr/local/spark/jars目录下的全部jar包添加进来,然后运行SaleSimulation.scala发送数据,再运行NetworkWordCount .scala接收并统计数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









