





 博客介绍了概率图模型相关知识,包括贝叶斯网络、马尔可夫网络、置信传播等,还阐述了因子图和因子图神经网络(FGNN)。论文提出FGNN模型,将生物知识编码到模型中,使模型透明可解释,设计参数共享机制减少参数,应用注意机制捕获相互作用,实验证明了模型有效性。
博客介绍了概率图模型相关知识,包括贝叶斯网络、马尔可夫网络、置信传播等,还阐述了因子图和因子图神经网络(FGNN)。论文提出FGNN模型,将生物知识编码到模型中,使模型透明可解释,设计参数共享机制减少参数,应用注意机制捕获相互作用,实验证明了模型有效性。
Incorporating Biological Knowledge with Factor Graph Neural Network for Interpretable Deep Learning
一、基本知识
1、图模型:图模型是由图结构构成的,其中节点表示随机变量,边表示变量之间的依赖关系。
2、贝叶斯网络:是有向图模型,每个节点都有一个相关的条件概率分布。
3、马尔可夫网络:是无向图模型,每个团都有一个相关的势函数。
4、条件独立:根据图中节点的连接方式,可以写出这种形式的条件独立陈述:「给定 Z,则 X 与 Y 相互独立」。
5、参数估计:根据给定的一些数据和图结构来填充 CPD 表或计算势函数。
6、推理:给定一个图模型,希望解答有关未被观察的变量的问题,这些问题通常属于以下问题范围:边际推理、后验推理和 MAP 推理。在一般图模型上的推理的计算非常困难,可以将推理算法分成两大类——精准推理和近似推理。无环图中的变量消除和置信度传播是精准推理算法的例子。近似推理算法对大规模图而言是必需的,而且通常属于基于采样的方法或变分法。
1.1 概率图模型
概率图模型(PGM),通过构建一个图,用观测结点表示观测到的数据,用隐含结点表示潜在的知识,用边来描述知识与数据的相互关系,最后获得一个概率分布,挖掘出隐含在数据中的知识。给定概率分布之后,通过进行两个任务:inference (给定观测结点,推断隐含结点的后验分布)和learning(学习这个概率分布的参数),来获取知识。概率图模型(或简称图模型),在形式上是由图结构组成的。图的每个节点(node)都关联了一个随机变量,而图的边(edge)则被用于编码这些随机变量之间的关系。根据图是有向的还是无向的,可以将图的模式分为两大类——贝叶斯网络( Bayesian network)和马尔可夫网络(Markov networks)。
概率图模型在实际中(包括工业界)的应用非常广泛与成功:隐马尔可夫模型(HMM)是语音识别的支柱模型,高斯混合模型(GMM)及其变种K-means是数据聚类的最基本模型,条件随机场(CRF)广泛应用于自然语言处理(如词性标注,命名实体识别),Ising模型获得过诺贝尔奖,话题模型在工业界大量使用(如腾讯的推荐系统)等等。
机器学习的一个核心任务是从观测到的数据中挖掘隐含的知识,而概率图模型是实现这一任务的一种很重要的手段。PGM巧妙地结合了图论和概率论:
从图论的角度,PGM是一个图,包含结点与边。结点可以分为两类:隐含结点和观测结点;边可以是有向的或者是无向的。
从概率论的角度,PGM是一个概率分布,图中的结点对应于随机变量,边对应于随机变量的依赖(dependency)或者相关(correlation)关系。
1.1.1 贝叶斯网络(BN)
经典的数学物理问题,大部分都是适定问题:①解存在;②解唯一;③解的连续性依赖于定解条件。而贝叶斯定理完美地把问题的不确定性和已知的先验知识结合起来,把实际问题转化为概率论中的推理问题,寻找可能性最大的全局最优解。而且利用贝叶斯定理建立的模型,具有完整的数学推导,可以很灵活地把各种先验知识包含在模型中。求解贝叶斯网络的最终目标是:求出每个节点的边缘概率分布。使一个边缘概率分布取得最大值的变量xi,就是这个节点的最大后验概率解。联合概率分布如下:

贝叶斯网络的一个基本要求是图必须是有向无环图(DAG/directed acyclic graph),其相连接的节点之间具有因果关系,也称为父子关系,要用条件概率表示它们之间的相互作用。与每个节点关联的表格,它们的正式名称是条件概率分布(CPD/conditional probability distribution),每个表格中的值的总和都必须为 1。
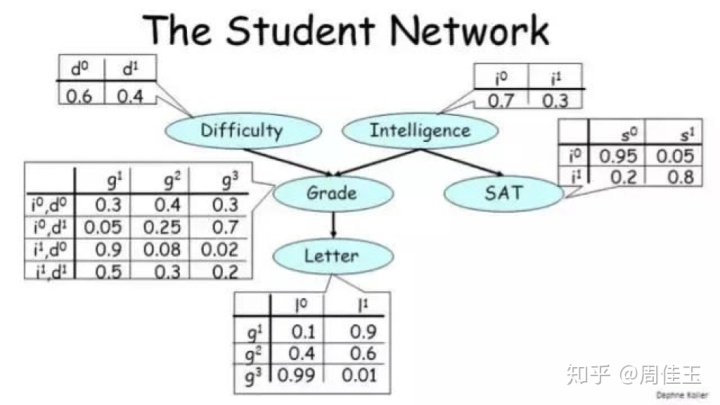
1.1.2 马尔可夫网络(MN)
马尔科夫随机场是一种特殊的贝叶斯网络,网络中的节点满足马尔科夫性质:某个节点的概率分布特性只与其领域内的点有关,与领域外的点无关。在这种领域模型中,随机场中的每一个节点只与它直接相邻的节点有相互作用。正如贝叶斯网络有 CPD 一样,马尔可夫网络也有用来整合节点之间的关系的表格。但是这些表格和 CPD 之间有两个关键差异:首先,这些值不需要总和为 1,也就是说这个表格并没有定义一个概率分布,只是值更高的配置有更大的可能性;也没有条件关系,与所涉及到的所有变量的联合分布成正比。联合概率密度如下:
对于图像问题,可能需要将每个像素都表示成一个节点。相邻像素互有影响,但像素之间并不存在因果关系;它们之间的相互作用是对称的。所以在这样的案例中使用无向图模型。
1.1.3 置信传播(Belief Propagation)
对于大多数较小的马尔科夫随机场,只要简单地对全概率公式采用求和或积分的方法,就可以求得每个隐藏点的边缘概率分布。但对于节点数很大的马尔科夫随机场,计算量以指数级增长,必须引入适当的计算方法,如置信传播算法。其主要思想是:对于马尔科夫随机场中的每一个节点,通过消息传播,把该节点的概率分布状态传递给相邻的节点,从而影响相邻节点的概率分布状态,经过一定次数的迭代,每个节点的概率分布将收敛于一个稳态。用置信传播算法求出的某点的置信度,就是该点的边缘概率分布。
消息的计算往往有先后关系,但在实际的网状马尔科夫随机场中,常常采用迭代式计算,即先为每一个消息赋初值,计算时不从起始节点沿所有的边一层层下去寻找边缘节点进行递归运算。而是随机找到某个点和它的邻居节点,计算它发送给邻居节点的消息,并计算邻居节点的置信度;然后再随机找到某个点,重复上面过程。每一次的迭代都使用上一次迭代后的值进行计算。
根据信息更新规则分类,置信传播算法分为:Max-product和Sum-product。
对于Sum-product,算法流程如下:
① 初始化所有隐藏节点的似然函数Φi(xi,yi)、每对邻居节点的势能量ψij(xi,xj)和消息mij(xj),其中,似然函数和势函数的初始化依赖于对问题的理解。
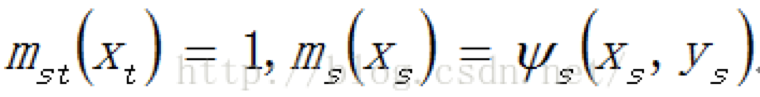
②随机找到某个点和它的邻居节点,用消息更新规则计算该节点发送给其邻居节点的所有消息,然后再随机找到某个节点,重复这个过程,当所有消息都更新一遍之后即完成一次迭代。
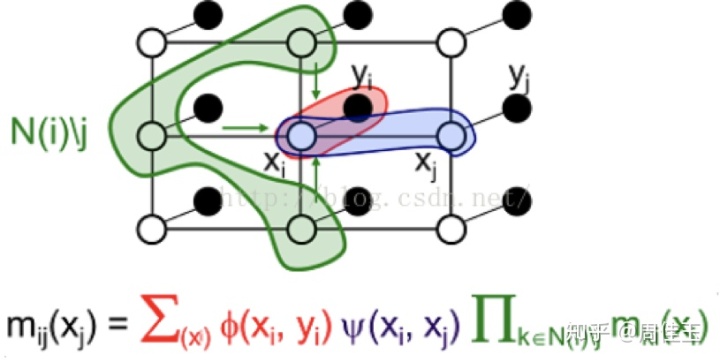
即,
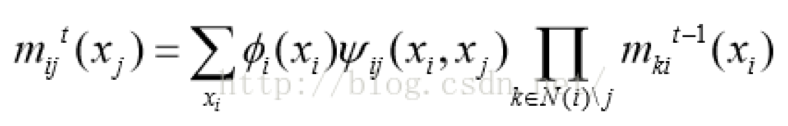
③ 按照指定次数进行第②步的算法迭代,或判断消息是否收敛,若算法已经收敛,则开始计算每个节点的置信度。
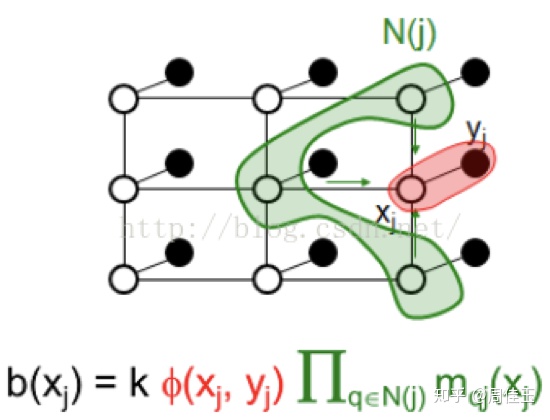
即,
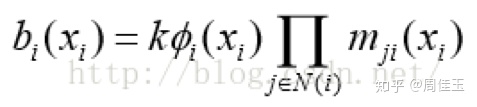
④ 由置信度求出使得每个节点的边缘概率分布取得最大的变量。
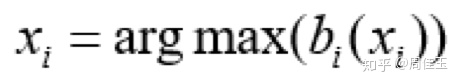
参考网页:从零学习Belief Propagation算法(一)、(二)、(三)
https://blog.youkuaiyun.com/qq_23947237/article/details/78385110
https://blog.youkuaiyun.com/qq_23947237/article/details/78387894
https://blog.youkuaiyun.com/qq_23947237/article/details/78389188
1.2 因子图(factor graph)
有向图和无向图都可以使若干个变量的联合概率函数(或全局函数)表示成这些变量的⼦集上因⼦的乘积。因⼦图比有向图和无向图更显式地表示了这个分解,在表示变量结点的基础上,又引⼊额外结点来表示因⼦本⾝。
将一个具有多变量的全局函数因子分解,得到几个局部函数的乘积,以此为基础得到的一个双向图叫做因子图。所谓factor graph(因子图),就是对函数因子分解的表示图,一般内含两种节点——变量节点和函数节点。因子图是一个二分图,其中一组变量节点连接到一组因子节点;图中的每个因子节点表示它所连接的变量之间存在依赖关系。在因子图中,顶点包括变量节点和函数节点,边线表示他们之间的函数关系。Factor Graph是概率图的一种,求某个变量的边缘分布有很多求解方法,其中之一就是可以将BN和MN转换成Factor Graph,基于Factor Graph可以用sum-product算法可以高效的求各个变量的边缘分布。
因子图已被广泛用于指定概率图模型(PGM),其可用于模拟随机变量之间的依赖性。一旦指定或学习了PGM,就可以使用近似推理算法,例如: Sum-Product或Max-Product Belief Propagation用于推断目标变量的值。与通常指定被建模变量的语义以及用于推理的近似算法的PGM不同,图神经网络通常从数据中同时学习一组潜在变量以及推理过程,图结构仅提供有关信息传播的依赖关系的信息。对于领域知识薄弱或者近似推理算法效果不佳的问题,能够与潜在变量共同学习推理算法,特别是针对目标数据分布,产生优异的结果。
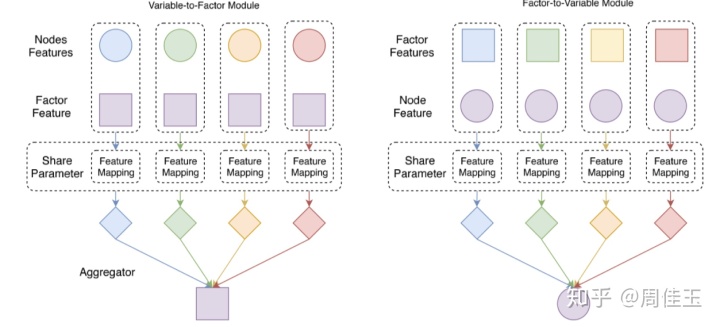
FGNN使用两种类型的模块定义,如上图所示。左侧为可变因子(Variable-to-Factor,VF)模块,右侧为因子-可变(Factor-to-Variable,FV)模块。VF模块将让因子从变量节点收集信息,并且FV模块将让节点从其父因子接收信息。VF模块和FV模块是具有相似结构但参数不同的MPNN层。FGNN层通常由VF层组成,该VF层由一组VF模块组成,后跟由一组FV模块组成的FV层。这些模块组合成一个层,层可以被堆叠成一个算法。
1.2.1 FGNN伪代码

给定图G=(V,N),其中V是一组节点,N是邻接列表,假设每个节点与特征向量fi和每个边(i,j)相关联 i∈V且j∈N(i)与边缘特征向量eij相关联。其中M将特征向量映射到长度为n的特征向量,并且Q(eij)将eij映射到m×n权重向量。然后通过矩阵乘法和聚合,可以生成长度为m的新特征。
MPNN编码一元和成对边缘特征,但是更高阶特征不是直接编码的,通过引入额外的因子节点来扩展MPNN。给定因子图G =(V,C,E),一组一元特征[fi]i∈V和一组因子特征[gc]c∈C,假设对于每个边(c,i)∈E在c∈C,i∈V的情况下,存在相关的边缘特征向量[tci]。
1.2.2 sum-product算法
sum-product算法,也叫belief propagation(信念传播),是一个计算边缘概率的低复杂度算法。求边缘分布需要大量的累加运算,而sum product算法将大量的累加运算分配到乘积项里去,从而降低复杂度。最简单的理解就是加法分配律 ab+ac=a(b+c)。原来要一次加法,两次乘法,用了sum product只要一次加法,一次乘法。
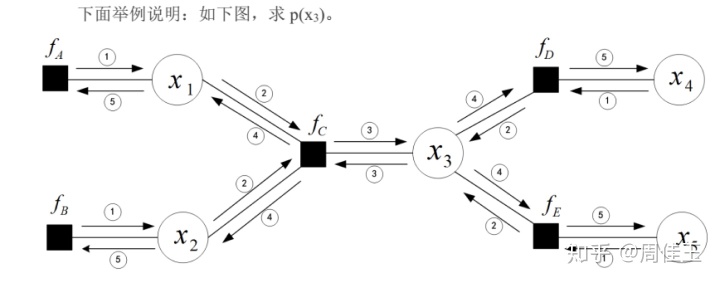

假设希望寻找图中每个变量结点的边缘概率分布,可以通过简单地对每个结点独立运⾏上述算法完成。通过“叠加”多个信息传递算法,可以得到⼀个更加高效的步骤,从而得到⼀般的加和-乘积算法。
1.3 因子图神经网络(FGNN)
图神经网络可以通过使用因子图结构以自然的方式扩展以捕获更高阶的依赖性,因子图形成的神经网络称为因子图神经网络(FGNN)。
二、论文介绍
2.1 背景介绍
以前关于图神经网络的工作主要集中在学习成对信息交换上,消息传递神经网络(MPNN)提供了一种框架,用于通过修改消息传递操作来导出不同的图神经网络算法。本文通过在因子图上执行消息传递,使网络能够有效地编码更高阶的特征,并在更高阶因子和节点之间传播信息。
2.2 主要工作
由于图形在许多应用中常用,已经开发了新的图形深度学习模型,包括图神经网络,图卷积神经网络等。图注意模型(GAM)也应用注意机制来学习图嵌入。这些方法主要关注单个图上的预测任务,例如预测图中的节点类别。相比之下,因子图神经网络使用来自领域知识的图作为模型架构并预测临床目标变量。
本文提出了因子图神经网络(FGNN)模型,它直接将生物知识如基因本体(Gene Ontology)编码到模型体系结构中。与不具物理意义的传统深度学习模型中隐藏节点不同,因子图神经网络模型中每个节点(即“神经元”)对应于某些生物实体(例如基因或基因本体术语),从而使得模型透明、可解释。实验还设计了一种参数共享机制,以显着减少模型参数的数量,同时保持深度学习模型的高表现力,可以用随机深度训练,进一步提高模型的普遍性。此外,还应用注意机制捕获基因本体术语和基因之间的分层多尺度相互作用。模型也可用于基因集富集分析,对两个癌症基因组数据集的广泛实验证明了所提出的模型的有效性。
2.3 因子图神经网络模型
为了使因子图神经网络模型可预测和推广,将诸如Gene Ontology注释之类的先验知识作为归纳偏差纳入模型体系结构,由基因和基因本体论(GO)术语形成二分图,构成两种类型的节点(即基因节点和GO节点)。每个GO术语与许多基因和基因产物相关。GO术语被视为因子图神经网络模型中的因子,基于基因本体论注释,可以构建一个因子图,其中GO术语作为因子,基因作为可观察变量。输入层中的节点是基因,隐藏层中的节点是GO术语。输出层是目标临床结果。当且仅当基因包含在GO术语中时,基因和GO术语之间存在边缘。因此,网络未完全连接在输入层和隐藏层之间。
因子图神经网络模型中的每个节点对应于一些生物实体,例如基因或基因本体术语,使模型透明且可解释。为了使模型表达足以捕获任何复杂的非线性关系,可以展开因子图神经网络模型以具有无限多层。通过参数共享,用随机深度训练模型,有助于模型更好地推广。我通过注意机制来捕捉生物实体之间的多尺度相互作用,例如基因和基因本体论术语。
相关文献:
1-Factor Graph Neural Network
2-Towards Bayesian Deep Learning: A Survey


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









