





 本文详细介绍了Flume,一个由Cloudera提供的高可用的分布式日志处理系统。Flume通过源、通道和sink组件,实现实时数据收集,支持多种数据源格式,并能持久化存储或发送至HDFS、Kafka等目标。重点讲解了内存Channel与文件Channel的区别以及自定义Sink选项。
本文详细介绍了Flume,一个由Cloudera提供的高可用的分布式日志处理系统。Flume通过源、通道和sink组件,实现实时数据收集,支持多种数据源格式,并能持久化存储或发送至HDFS、Kafka等目标。重点讲解了内存Channel与文件Channel的区别以及自定义Sink选项。
Flume 概述
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单,Flume主要功能是,实时读取服务器本地磁盘的数据,将数据写入到HDFS或传送给Kafka。
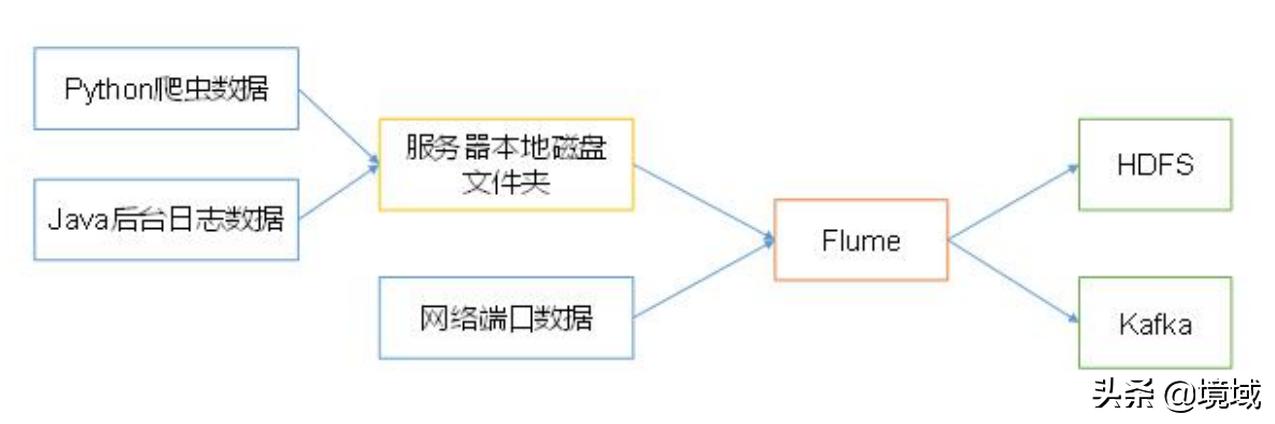
Flume 基础架构
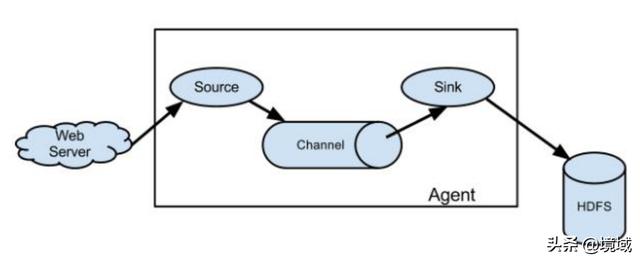
Flume 组成架构
Flume 架构中的组件
Agent
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的。
Agent 主要有 3 个部分组成,分别是 Source、Channel、Sink。
1、Source
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括syslog、http、legacy、 avro、thrift、exec、jms、spooling directory、netcat、sequence、generator。
2、Channel
Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运
作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个
Sink 的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel。
Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下使用。
如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
3、Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件目的地包括file、HBase、hdfs、logger、avro、thrift、ipc、solr、kafka自定义。
Event
传输单元,Flume 数据传输的基本单元,以 Event 的形式将数据从源头送至目的地。
Event由 Header 和 Body 两部分组成,Header 用来存放该 event 的一些属性,为 K-V 结构,Body
用来存放该条数据,形式为字节数组。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









