






[新一代实时神器 Fluss实战] - Flink SQL 读写Fluss
通过 Flink 读取Kafka数据写入Fluss
环境信息
-
Flink 1.20
-
Fluss 0.6.0 git master 个人build的 (使用下载的0.5.0版本有些问题,在后续会写道)
-
Kafka 2.7.2
-
hadoop 3.0.0
步骤
Flink SQL Client 启动
进入Flink安装目录,执行 ./bin/sql-client.sh启动SQL客户端命令行;
配置运行参数
- checkpoint 时间:
SET 'execution.checkpointing.interval' = '30s';作为 Flink 写入 Fluss 的 ck 时间 - 设置执行模式:
SET execution.type = streaming ; - 设置SQLClient 任务提交方式:
SET 'execution.target' = 'yarn-per-job'; - 设置SQLClient 任务提交队列:
SET 'yarn.application.queue' = 'flink'; - 设置SQLClient任务提交名称:
SET 'yarn.application.name' = 'kafka-flink-fluss';
数据写入SQL
-
创建 Fluss catalog
CREATE CATALOG fluss_catalog WITH ('type'='fluss','bootstrap.servers' = '10.255.10.1:9123');bootstrap.servers 为Fluss CoordinatorServer 的部署 Host 及 Port -
创建Kafka流表,默认创建在
default_catalog.default_database目录下,create table kafka_data_tb ( id string comment 'id', create_time string comment '创建时间', stat_date string comment '分区时间', PRIMARY KEY (id,stat_date) NOT ENFORCED -- 定义主键 ) with ( 'connector' = 'kafka', 'properties.bootstrap.servers' = 'xxxx:9092,xxxx:9092,xxxx:9092', 'scan.startup.mode'='timestamp', 'scan.startup.timestamp-millis' = '1735833600000', -- 指定时间戳消费 'topic' = 'tp_fluss_kafka_test', 'properties.group.id' = 'tp_fluss_kafka_test-id', 'format' = 'debezium-json' ); -
创建 Fluss 表 ;Fluss 表创建在
fluss_catalog下,后续使用只需要创建fluss_catalog, 建表信息依旧会存在,不需要重复创建-- 创建数据库 create database fluss_catalog.fluss; -- 创建主键表,并设置分区 create table fluss_catalog.fluss.fluss_data_tb ( id string comment 'id', create_time string comment '创建时间', stat_date string comment '分区时间', PRIMARY KEY (id,stat_date) NOT ENFORCED -- 定义主键 ) PARTITIONED by (stat_date) WITH ( 'bootstrap.servers' = '10.255.10.1:9123', -- fluss CoordinatorServer 地址 'bucket.key' = 'id', -- 分桶字段 'bucket.num' = '4', -- 分桶数量 'table.datalake.enabled' = 'true', -- 是否开启写入数据湖功能 'table.auto-partition.enabled' = 'true', -- 开启自动分区 'table.auto-partition.time-unit' = 'day' -- 分区字段的单位 ) -
写入 SQL
insert into fluss_catalog.fluss.fluss_data_tb select id,create_time,stat_date from kafka_data_tb; -
以上及完成了 kafka 数据 写入 Fluss ,Flink 运行状态
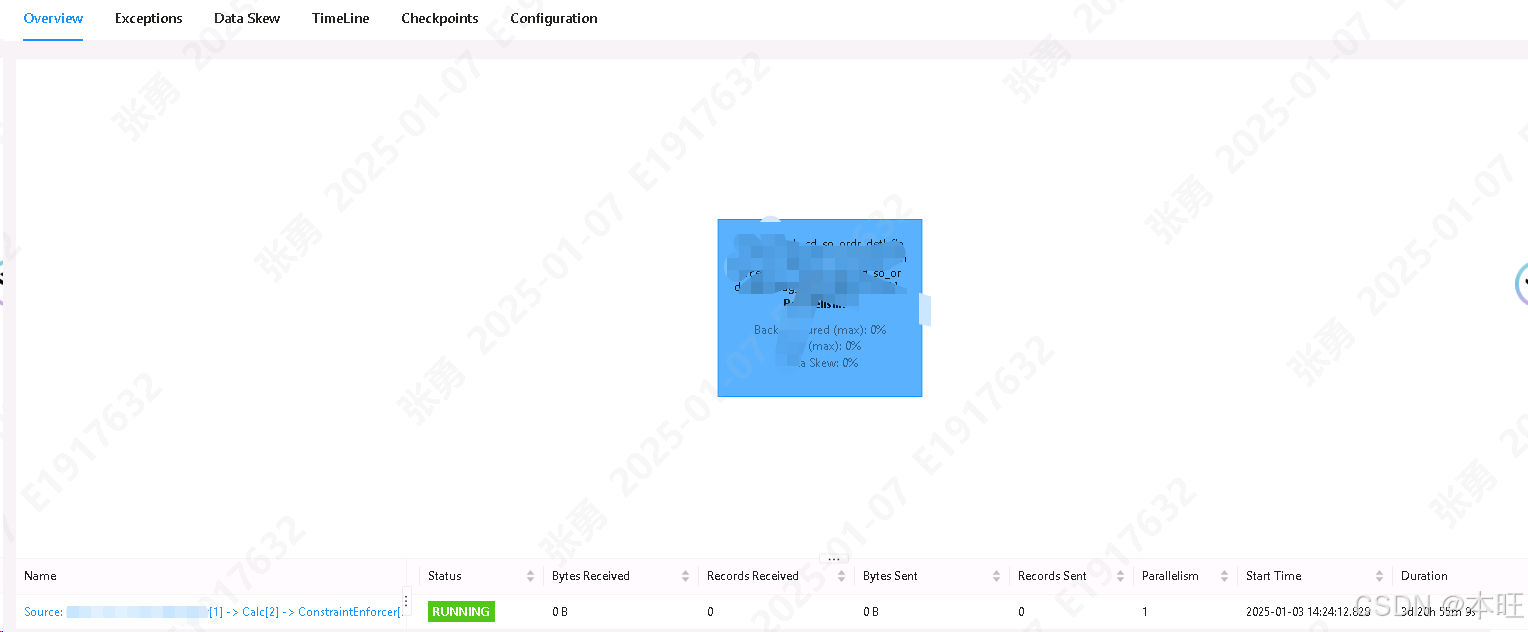
-
数据查询
-- 查询实时数据 select id , create_time, stat_date from fluss_catalog.fluss.fluss_data_tb /*+ OPTIONS('scan.startup.mode' = 'latest') */; -- 查询离线数据 select id , create_time, stat_date from fluss_catalog.fluss.fluss_data_tb;
遇到的问题及注意点
[分区不存在] Error - cam.alibaba.flus .exception.PartitiomlotexistException: Table partition 'fluss.xxx(p-28241230)" does not exist.

该错误为历史分区Fluss无法创建,只能创建今天及今天以后的分区;且目前Fluss不支持手动创建分区;社区正在规划中;
解决方案:将数据进行过滤,只写入今天及今天以后的数据
[写入 OP 为 d 的数据 NULLPointerException] - com.alibaba.fluss .exception.FlussRuntimeException: java.lang.NullPointerException
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传

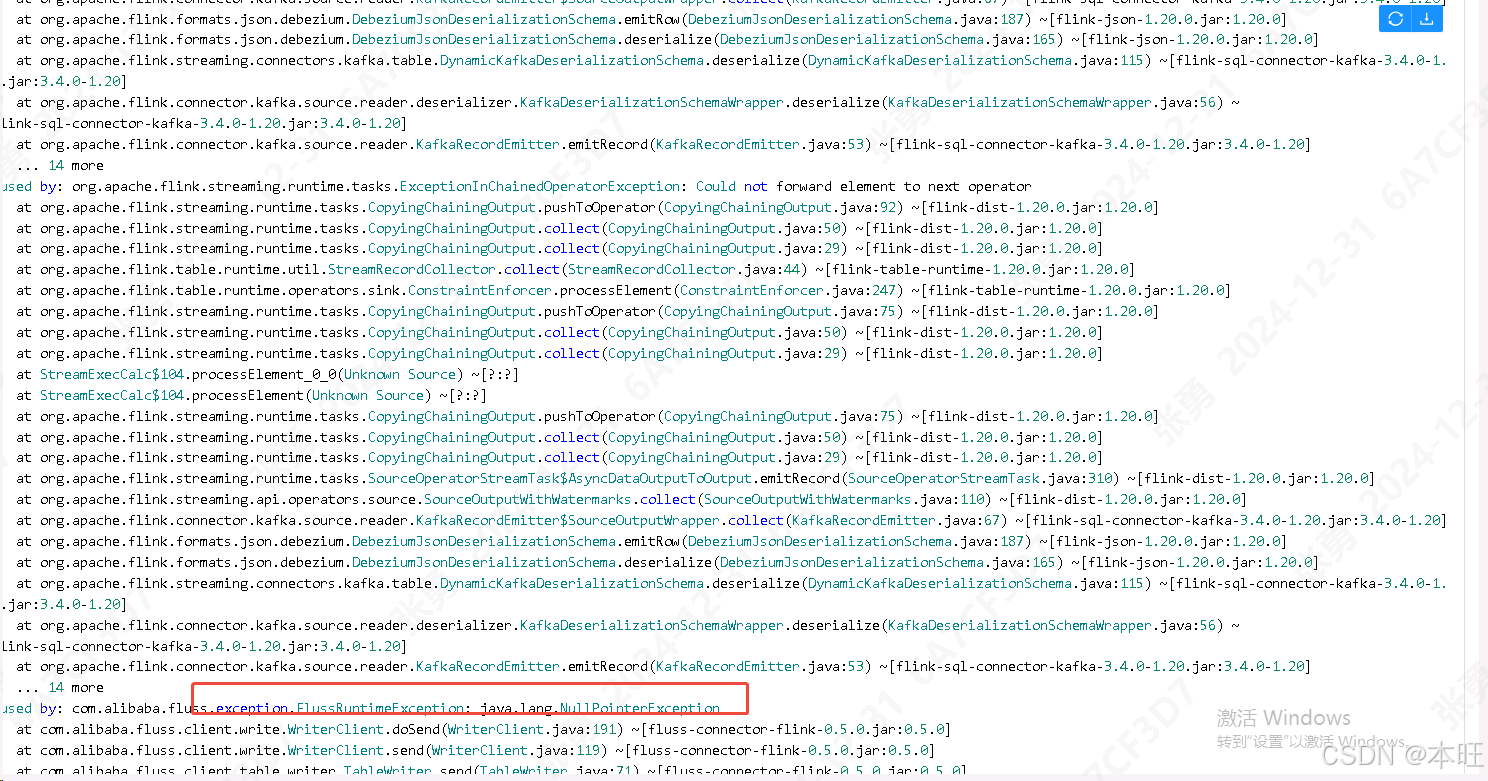
该错误为,在写入 upsert 数据时,当数据类型为 d 即 delete 数据时,传入数据 row 为 null, 导致获取 分桶键 bucketKey 时出现空指针异常, 大致源码图下
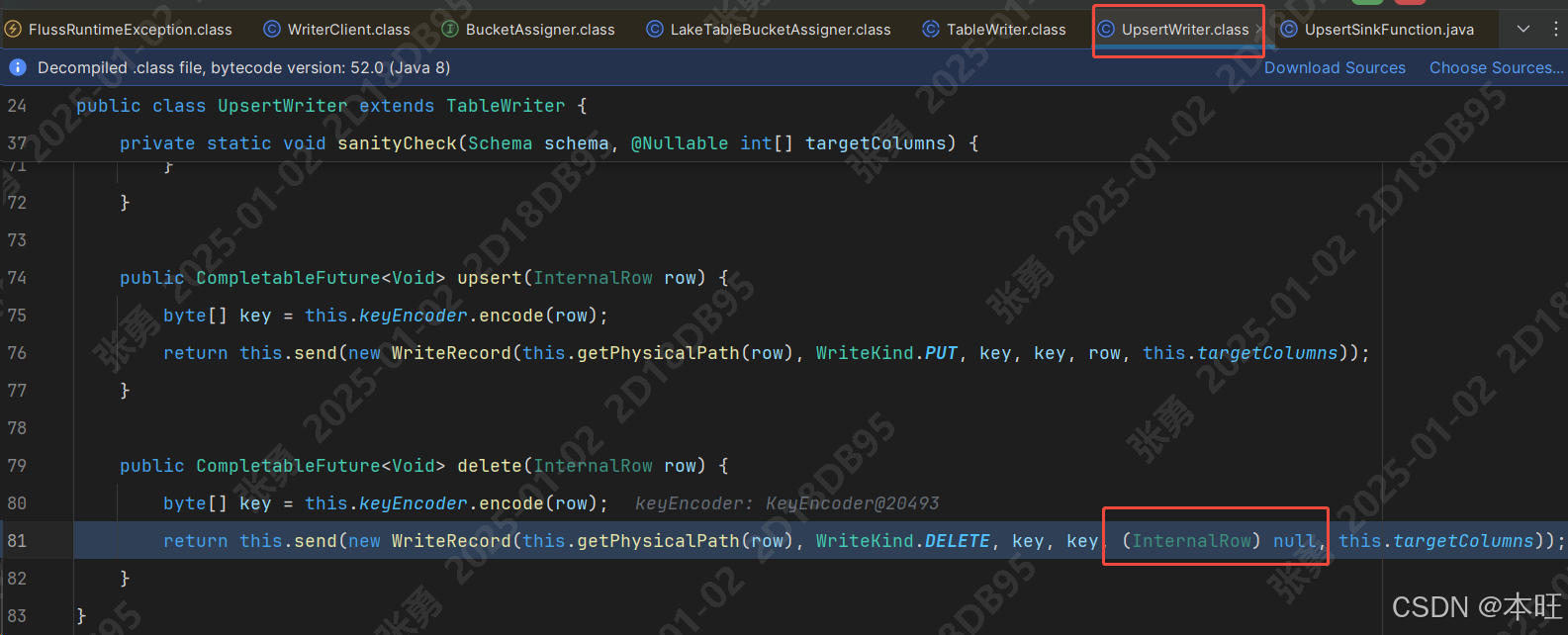
解决方案: 修改对应的源码进行重新打包部署。
[无法识别 Hdfs 文件系统 ]- com.alibaba.fluss.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme ‘hdfs’. File system schemes are supported by Fluss through the following plugin(s): fluss-fs-hadoop.
该错误为0.5.0版本出现,社区已解决,可下载master自行编译部署解决
总结
以上为笔者在使用 Flink SQL 读写 Fluss 的大致流程和遇到的一些问题, Fluss 也是刚开源,但他的架构和功能确实是推动了实时计算的一大进程,其功能有待我们进一步挖掘;也欢迎大家一起交流

















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









