





Scrapy是一种快速的高级Web爬虫和Web抓取框架,用于抓取网站并从其页面中提取结构化数据。它可用于各种用途,从数据挖掘到监控和自动化测试。

老规矩,使用前先用pip install scrapy进行安装,如果安装过程中遇到错误一般为error:Microsoft Visual C++ 14.0 is required. 只需要访问https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted网站下载Twisted-19.2.1-cp37-cp37m-win_amd64安装即可,注意cp37代表的是我本机python的版本3.7 amd64代表我的操作系统位数。
安装使用 pip install Twisted-19.2.1-cp37-cp37m-win_amd64.whl即可,然后在重新安装scrapy就会成功安装了;安装成功后我们就可以使用scrapy命令进行创建爬虫项目了。
接下来在我的桌面运行cmd命令,使用 scrapy startproject webtutorial创建项目:
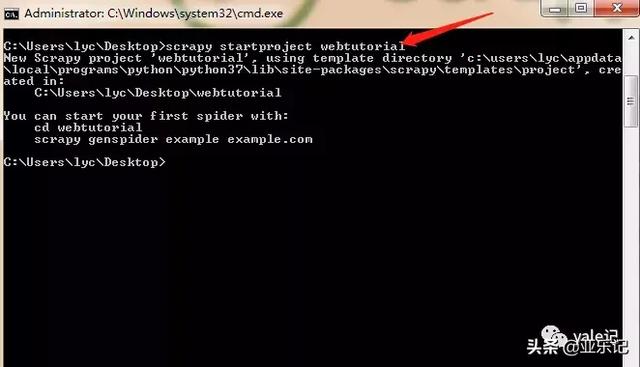
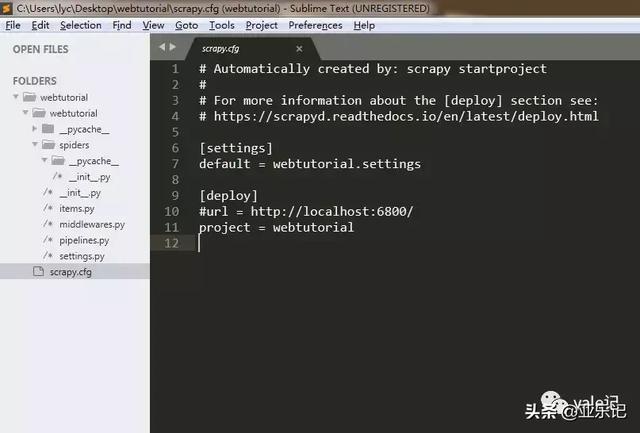
会在桌面生成一个webtutorial文件夹,我们看下目录结构:
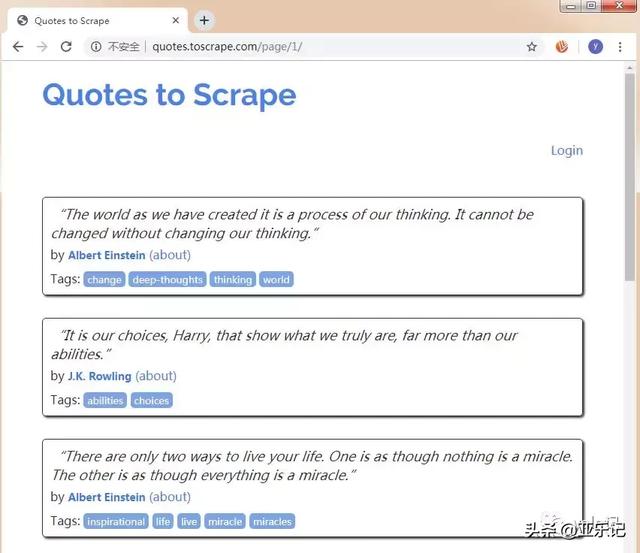
然后我们在spiders文件夹下新建一个quotes_spider.py,编写一个爬虫用来爬取http://quotes.toscrape.com网站保存为一个html文件,网站截图如下:
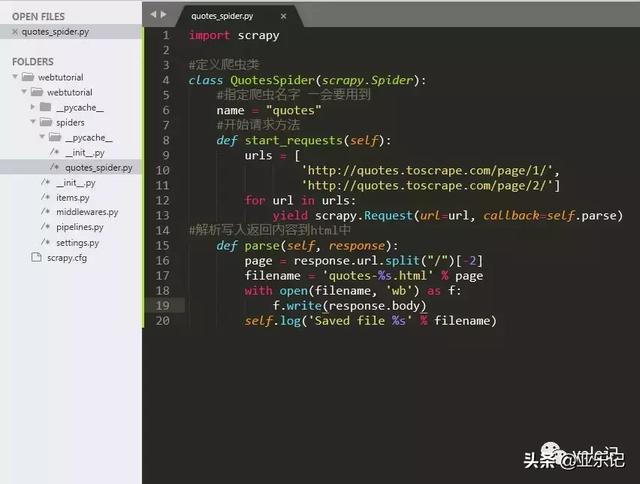
代码如下:
import scrapy#定义爬虫类class QuotesSpider(scrapy.Spider): #指定爬虫名字 一会要用到 name = "quotes" #开始请求方法 def start_requests(self): urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/'] for url in urls: yield scrapy.Request(url=url, callback=self.parse)#解析写入返回内容到html中 def parse(self, response): page = response.url.split("/")[-2] filename = 'quotes-%s.html' % page with open(filename, 'wb') as f: f.write(response.body) self.log('Saved file %s' % filename)之后的目录结构为:
然后我们在命令行中切换到webtutorial文件夹下,执行命令scrapy crawl quotes进行抓取(quotes为刚才指定的爬虫名):
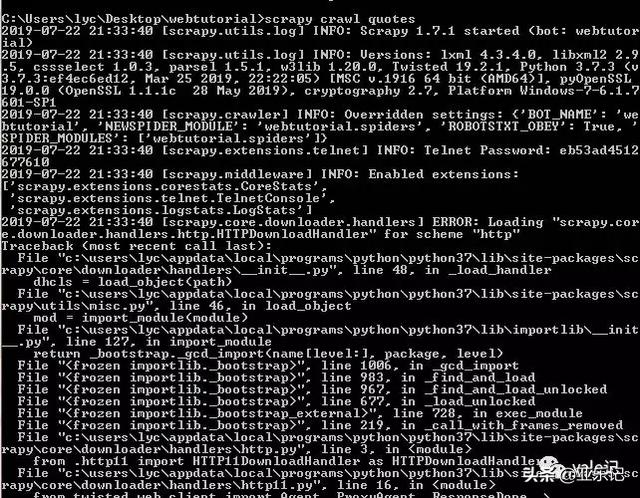
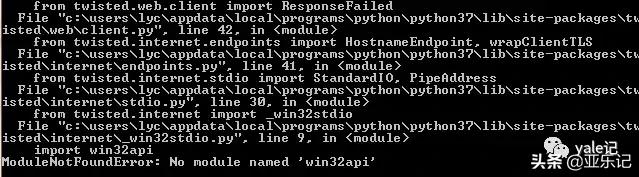
发现出错了,No module named 'win32api',这里我们安装一下win32api
使用命令 pip install pypiwin32,然后继续执行scrapy crawl quotes:
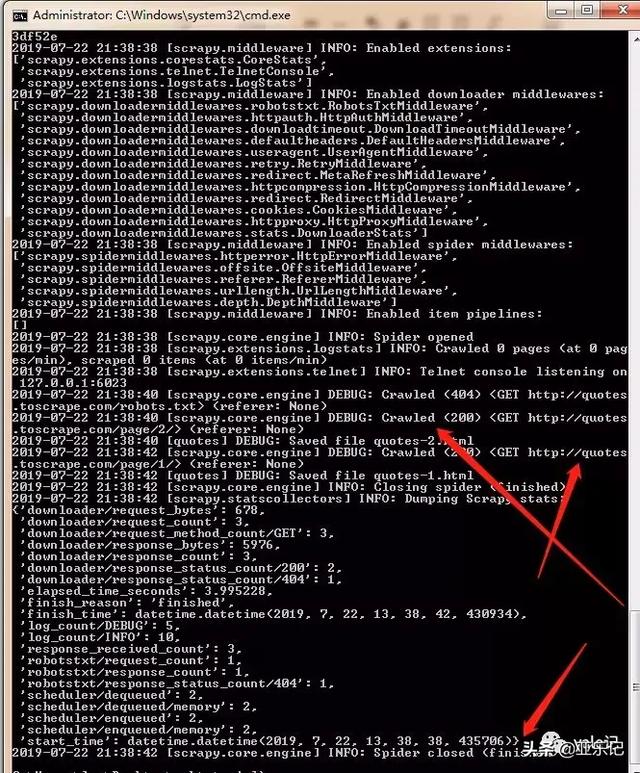
可知爬虫任务成功执行,这时会在webtutorial文件夹下生成两个html:
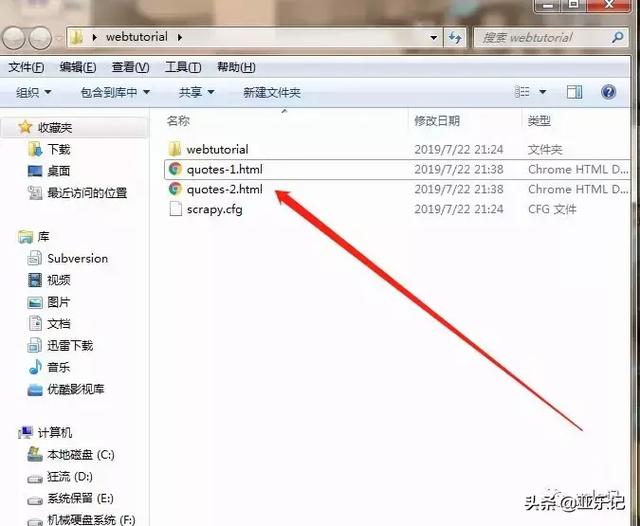
至此使用scrapy的抓取网页初学结束了,下节见。
关注公号yale记
下面的是我的公众号二维码图片,欢迎关注。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









