






THE START
小编今天更新Python的下载安装及简单使用教程,但是近期被微软的Pylance(用于改善VS Code 中的Python体验)刷屏了, 这个名字是对 Monty Python 的 Lancelot 的致敬,Lancelot 是亚瑟王和圆桌骑士中的第一位勇士。小编先学习一下这个“勇士”可能会在近期更新vs相关!进入主题!
python是一种解释型,高层次,可读性很强的通用编程语言。Python 由Guido van Rossum创建并于1991年首次发布,Python的设计理念是通过显着使用大量空白来强调代码的可读性。它的语言构造和面向对象的方法旨在帮助程序员为大型和大型项目编写清晰的逻辑代码。
Python具有简单易学的语法,该语法强调可读性。用Python编写的应用程序几乎可以在任何计算机上运行,包括那些运行Windows,macOS和流行的Linux发行版的计算机。应用领域比较广泛,主要涵盖网络和互联网发展、数据库访问、桌面GUl、科学与数值、教育、网络编程、软件与游戏开发等等。
Python 2.7的终止日期最初定为2015年,由于担心大量现有代码无法轻易地移植到Python 3而推迟到2020年,Python3.X在库的名称上也有所改变,所以建议安装Python3.X版本。
Python的核心理念
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Readability counts.
Python Features
易于学习
易于阅读
易于维护
广泛的标准库
交互模式
可移植
可扩展
数据库
GUI编程
可扩展性强
支持功能性和结构化编程方法以及OOP。
可以用作脚本语言,也可以编译为字节码以构建大型应用程序。
提供了非常高级的动态数据类型,并支持动态类型检查。
支持自动垃圾收集。
可以轻松地与C,C ++,COM,ActiveX,CORBA和Java集成。
下载安装
1.公众号后台获取安装包
1.官网下载
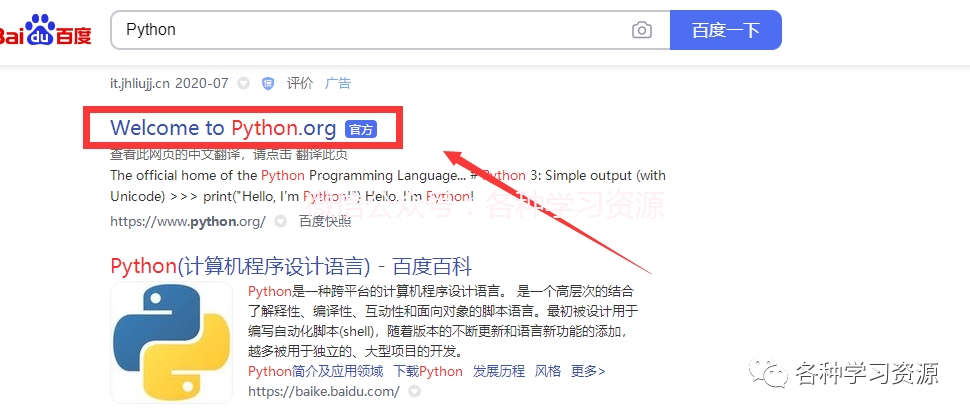
百度搜索Python,找到带有官网标记打开。
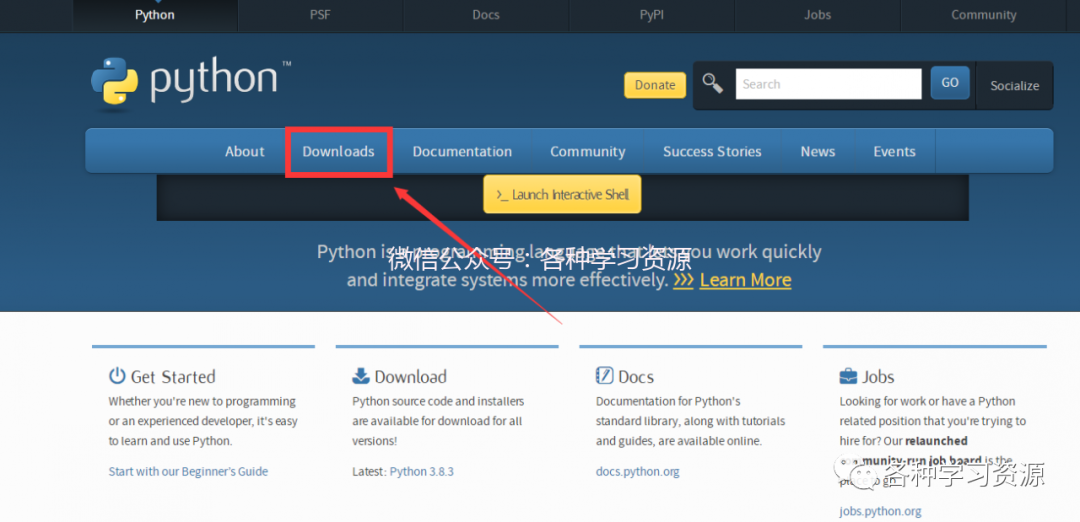
2.点击download
3.选择系统,小编选择Windows
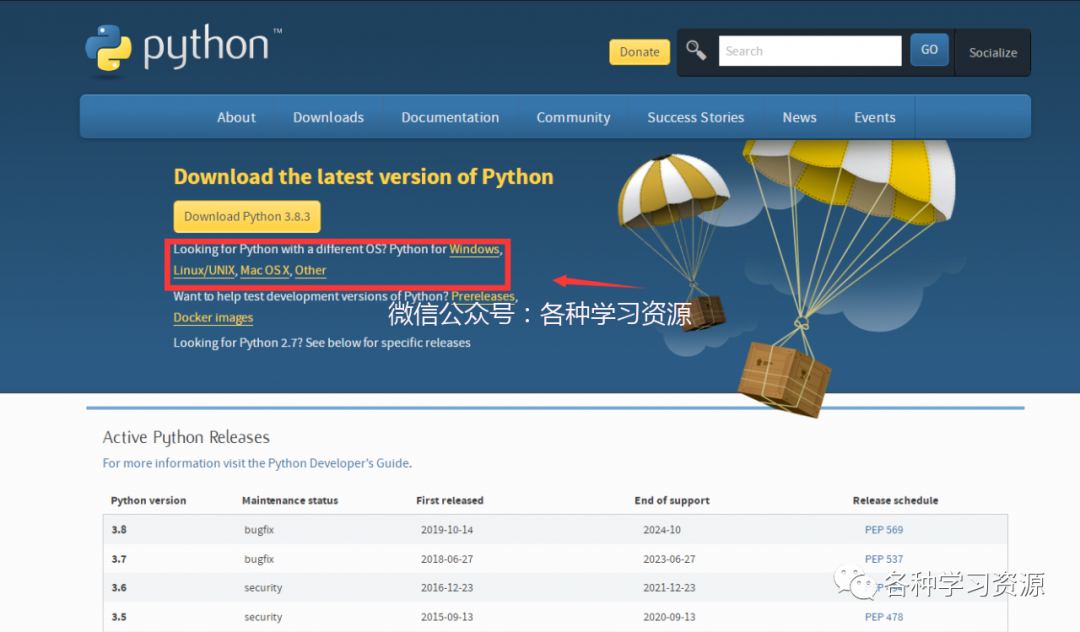
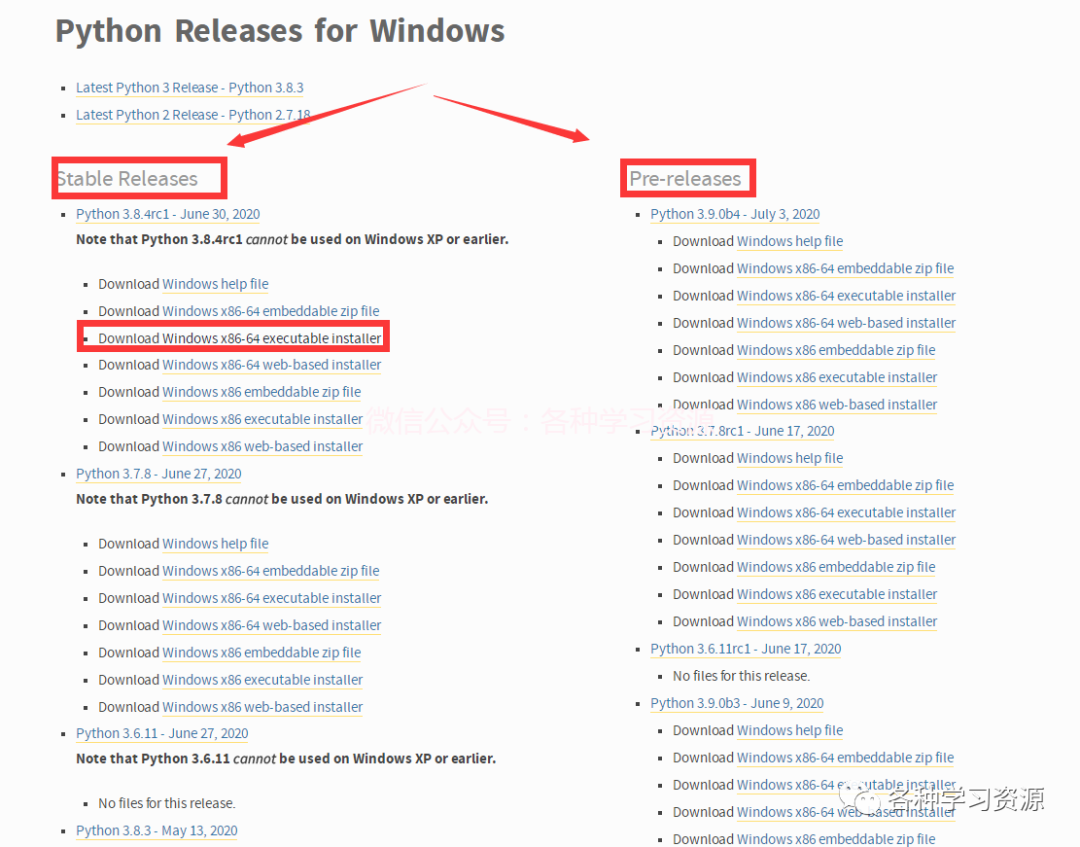
4.左边稳定版,右边为最新版
点击选择版本及系统并且后缀带有executable installer,弹出下载页面。提示:小编建议安装3.7以上版本!
下载到磁盘根目录下,不要存放到含有中文字符的文件下。
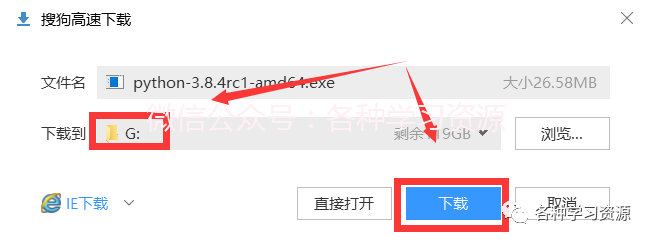
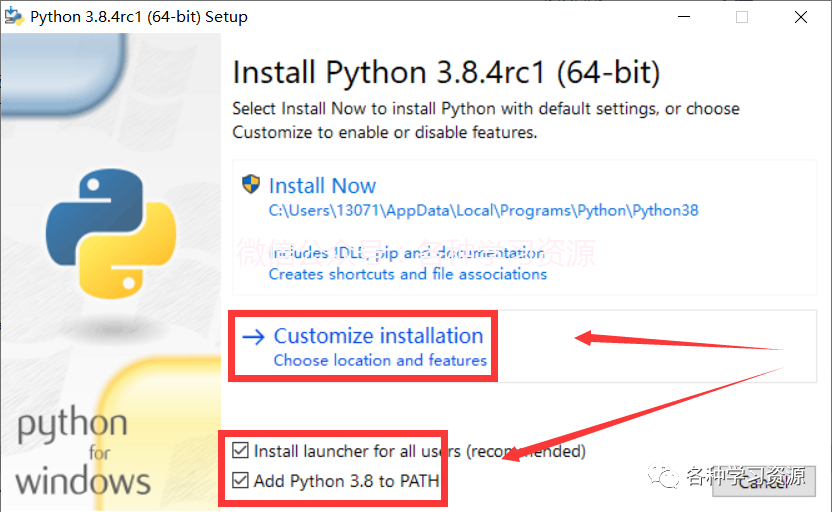
5.下载完成后右键以管理员身份运行
勾选后点击customize installation
6.点击next
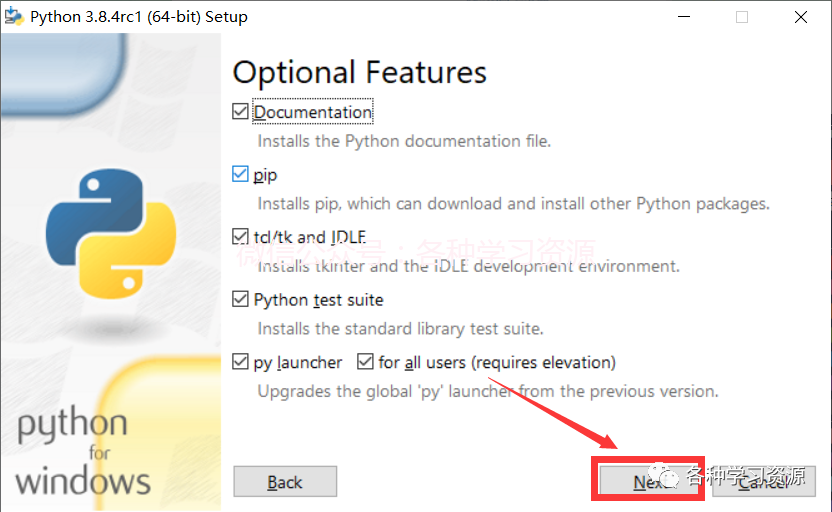
7.第一个勾选,选择安装目录,安装文件夹不要带有中文字符,点击install
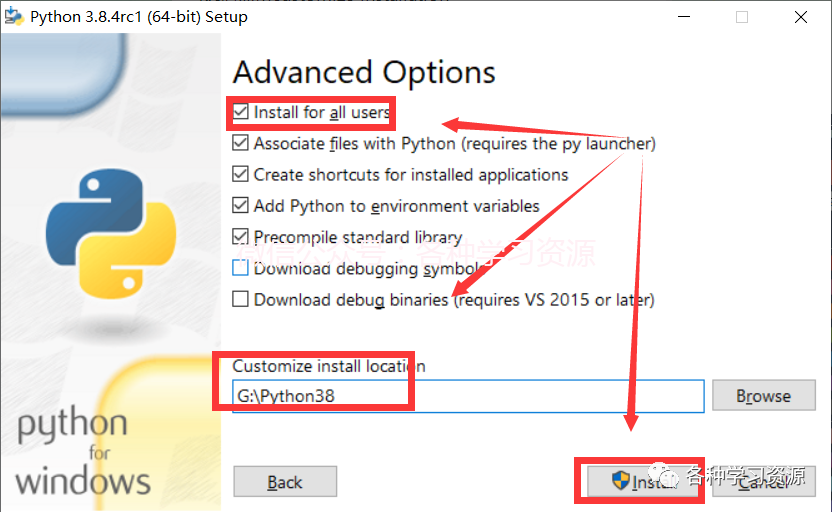
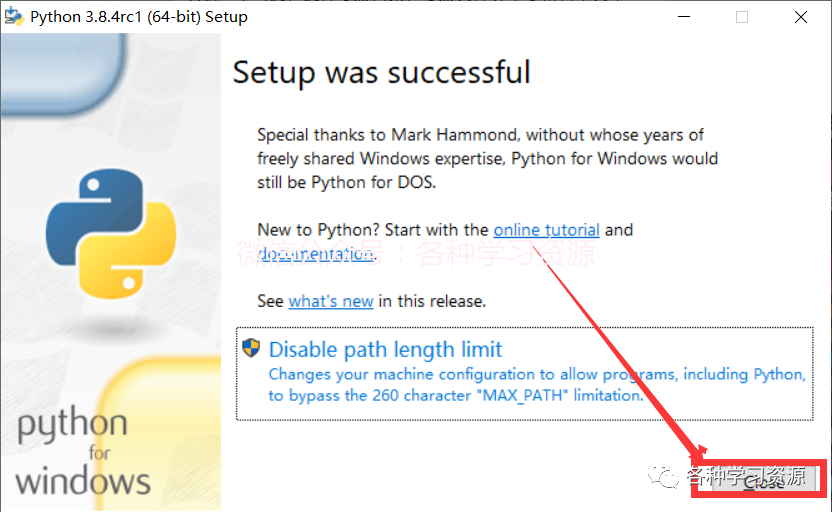
8.安装完成点击close
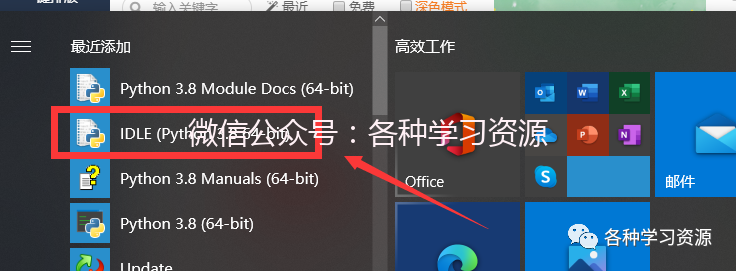
9.菜单栏打开IDLE测试
左键拖动图标 至桌面快速创建快捷方式。
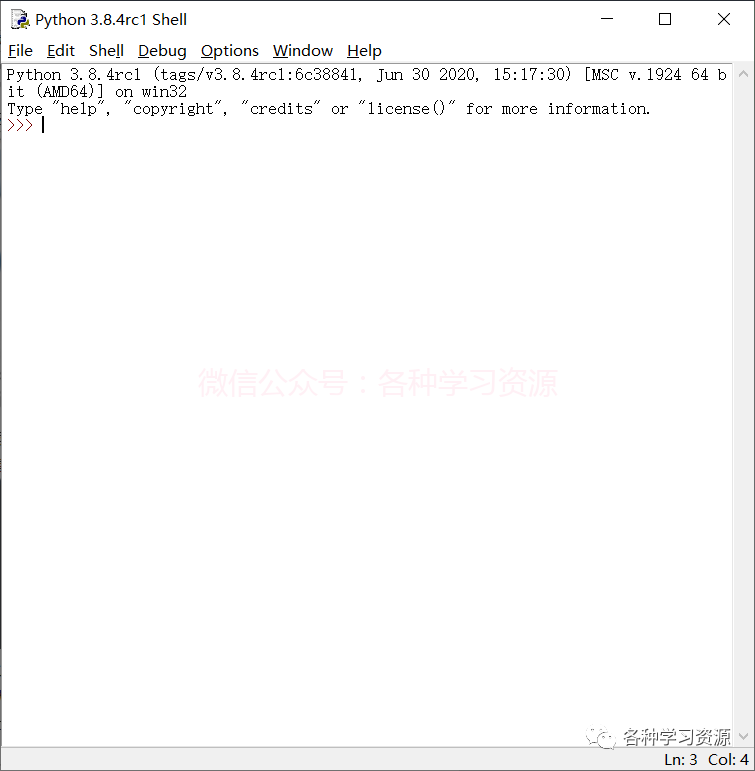
可以开始表演了,自带编辑器功能比较少,没有智能辅助输入及代码高亮,此外一些库的下载也不太方便,建议使用pycharm。
快速上手
简单绘图,代码如下方2所示,从这个代码中小伙伴们应该可以了解到为什么说Python可读性比较强。一般绘图步骤:导入库,输入函数或导入数据,修饰图表。首先导入matplotlib库,如果使用pycharm的话可以直接导入,Pylance会自动导入需要的库。此外Python绘图可以实现高度定制,所以熟练使用后个人学习版originlab可以放一边了。
1.小编手动导入,打开cmd,输入pip install matplotlib.
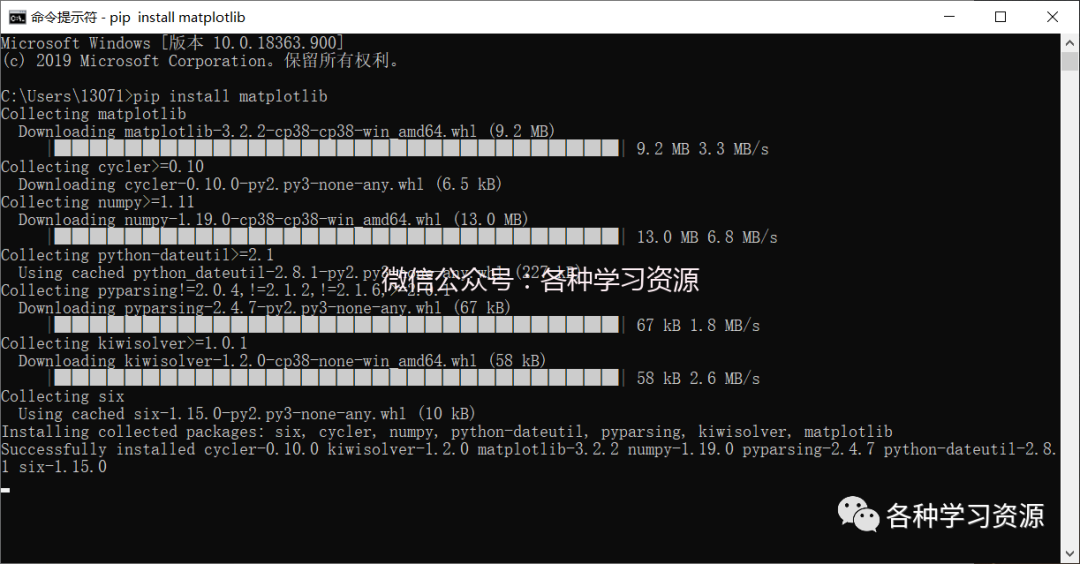
2.打开Python编辑器,输入以下代码保存点击run,保存后双击打开文件也会直接运行,结果如下图;
import matplotlib.pyplot as pltimport numpy as npt = np.arange(0.0, 2.0, 0.01)s = 1 + np.sin(2*np.pi*t)plt.plot(t, s)plt.xlabel('time (s)')plt.ylabel('voltage (mV)')plt.title('About as simple as it gets, folks')plt.grid(True)plt.savefig("test.png")plt.show()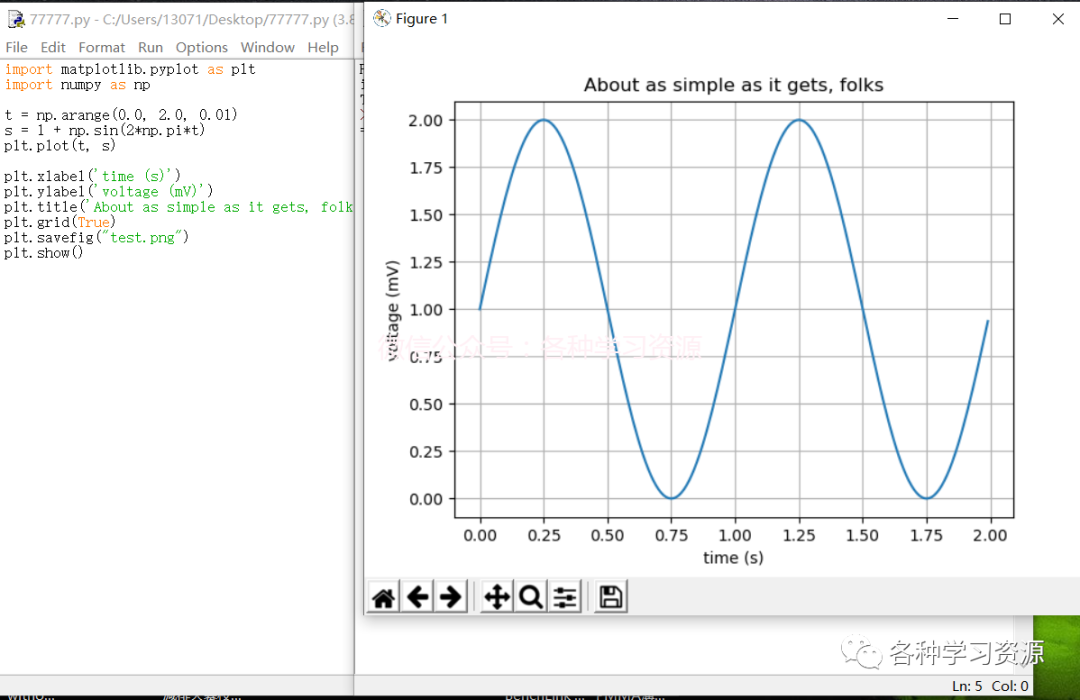
爬虫测试
爬虫其实就是让程序根据自己的代码指令抓取并下载指定的文件或内容,最重要的是对目标网页的内容结构分析,通过网页源码找到文件的代码并解析目标内容的代码形式。
首先导入库,否则程序是无法运行的,小编分享的这段程序需要导入lxml和requests。
1.打开cmd,然后分别输入pip install requests完成后再输入pip install lxml。
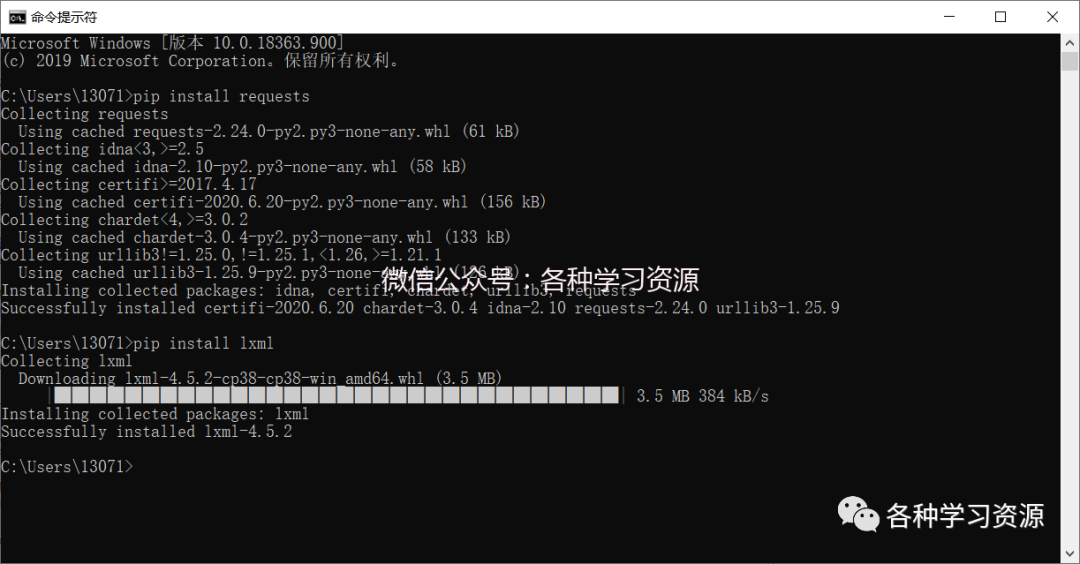
打开PythonIDLE,点击file-new file
输入代码
# -*- coding: utf-8 -*-import osimport sysimport urllib.requestimport requestsimport refrom lxml import etreedef StringListSave(save_path, filename, slist): if not os.path.exists(save_path): os.makedirs(save_path) path = save_path+"/"+filename+".txt" with open(path, "w+") as fp: for s in slist: fp.write("%s\t\t%s\n" % (s[0].encode("utf8"), s[1].encode("utf8")))def Page_Info(myPage): '''Regex''' mypage_Info = re.findall(r'', myPage, re.S) return mypage_Infodef New_Page_Info(new_page): '''Regex(slowly) or Xpath(fast)''' # new_page_Info = re.findall(r' # # new_page_Info = re.findall(r' # results = [] # for url, item in new_page_Info: # results.append((item, url+".html")) # return results dom = etree.HTML(new_page) new_items = dom.xpath('//tr/td/a/text()') new_urls = dom.xpath('//tr/td/a/@href') assert(len(new_items) == len(new_urls)) return zip(new_items, new_urls)def Spider(url): i = 0 print ("downloading ", url) myPage = requests.get(url).content.decode("gbk") # myPage = urllib2.urlopen(url).read().decode("gbk") myPageResults = Page_Info(myPage) save_path = u"网易新闻抓取" filename = str(i)+"_"+u"新闻排行榜" StringListSave(save_path, filename, myPageResults) i += 1 for item, url in myPageResults: print ("downloading ", url) new_page = requests.get(url).content.decode("gbk") # new_page = urllib2.urlopen(url).read().decode("gbk") newPageResults = New_Page_Info(new_page) filename = str(i)+"_"+item StringListSave(save_path, filename, newPageResults) i += 1if __name__ == '__main__': print ("start") start_url = "https://news.163.com/rank/" Spider(start_url) print ("end")
点击run会提示保存文件,保存后程序会自动运行并将结果呈现在IDLE中,如下图:
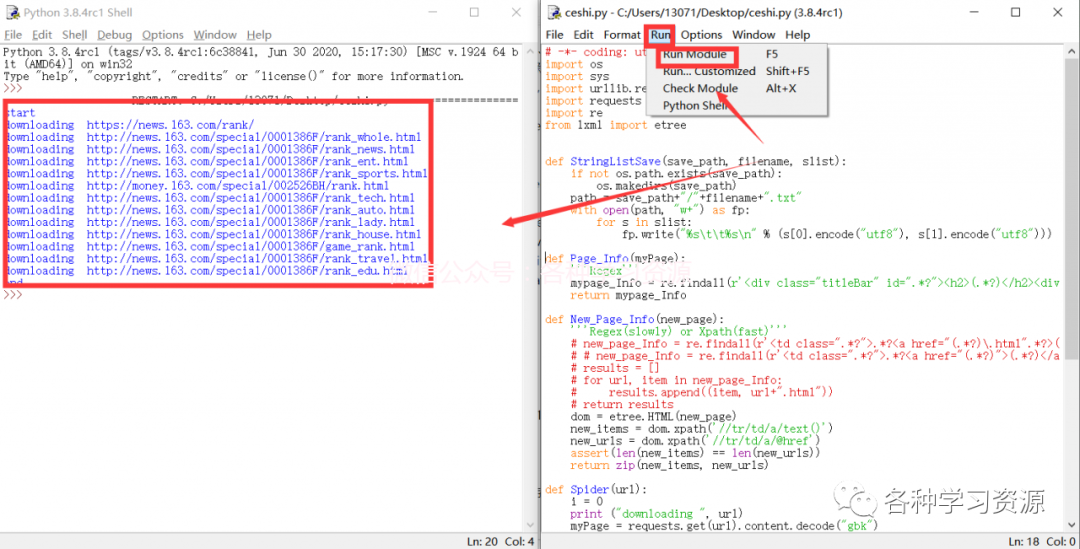
爬虫后自动下载的文件和程序保存的路径一致,小编直接保存在桌面,所以可以在桌面找到一个网易新闻抓取文件夹。

打开查看
此段代码还可以进行改进,因为抓取的内容比较以text格式存放且有点凌乱,目标内容无法直接点击访问,还需要复制进浏览器,小编后期会写一些好玩的程序分享给小伙伴们。

参考信息
1.https://www.python.org/getit/
2.Kuhlman, Dave. "A Python Book: Beginning Python, Advanced Python, and Python Exercises". Section 1.1. Archived from the original (PDF) on 23 June 2012.
3.Peterson, Benjamin (20 April 2020). "Python Insider: Python 2.7.18, the last release of Python 2". Python Insider. Retrieved 27 April 2020.
4.Python Developer's Guide — Python Developer's Guide". devguide.python.org. Retrieved 17 December 2019.
5.https://www.geeksforgeeks.org/graph-plotting-in-python-set-1/Python源代码学习网站
6Python获取
微信关注“各种学习资源”,后台发送“202007133”

















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









