



MySQL是目前最常用的关系型数据库,也是最常用的RDBMS应用软件之一。本节将对MySQL原理进行一个小结,方便交流与学习。本文不涉及sql的具体用法,只是探究总结MySQL使用过程中涉及到的一些原理知识,方便交流和学习。
1. MySQL架构简介
MySQL基本的逻辑架构包含三个部分:存储引擎、核心服务、客户端层。存储引擎负责MySQL中的数据存储和提取。核心服务包括查询解析、分析、优化、缓存、内置函数等。客户端层包含连接处理、授权认证、安全等功能,但并非MySQL所独有。
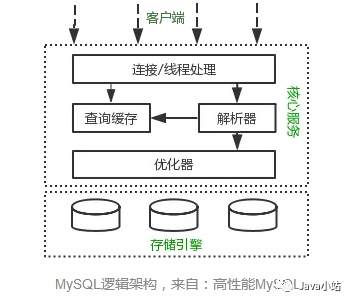
MySQL查询过程是遵循一些原则让MySQL的优化器能够按照预想的合理方式运行的过程。MySQL客户端/服务端通信协议是“半双工”的:在任一时刻,要么是服务器向客户端发送数据,要么是客户端向服务器发送数据,这两个动作不能同时发生,一旦一端开始发送消息,另一端要接收完整个消息才能响应它。
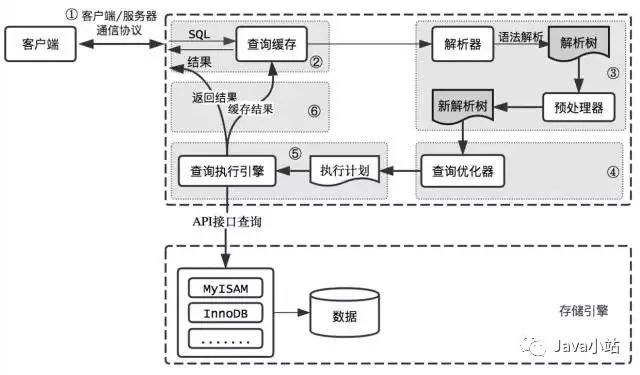
客户端/服务端。协议是半双工的。任意时刻,要么服务器向客户端发送数据,要么客户端向服务器发送数据,两个动作不能同时发生。一旦一方开始发送消息,另一方需要接受全部消息之后才能进行响应。此外,客户端发送的是一个单独的数据包,因此要避免查询语句过长。而服务端响应的数据往往由多个数据包组成。服务器返回数据时,客户端必须完整的接受所有返回结果,而不是取其中的一部分,随即让服务器停止发送。因此,为了减少通信开销,要尽量保证查询简单且只返回有用的数据,同时加上limit进行限制且尽量避免select * 。
查询缓存。若当前查询在查询缓存中,则将直接返回缓存中的结果而无需继续执行 。缓存索引通过查询,数据库信息,协议版本号等信息计算得到,因此,改变任意字符将可能导致缓存未命中。若查询中有函数等临时数据,则不会被缓存。当表的数据或结构发生变化时,与该表相关的所有查询缓存将会失效,将带来一定的系统消耗。缓存新建和失效都会带来额外的开销,因此只有当缓存节约的资源大于其消耗,才会带来性能的提升。一般写密集场景不建议打开查询缓存。
语法解析与预处理。基于SQL语句的关键字通过语法规则进行语法解析生成解析树,判断是否为合法SQL以及有效SQL。
查询优化器。一条查询通常有多种执行计划,不同执行计划的效率差别很大,因此,对于复杂查询选择一个最优的执行计划尤为重要。MySQL采用基于成本的优化器,选择预期成本最小的一个计划。计算成本时基于采样进行计算,并综合考虑索引信息等,但是实际执行过程中会可能选择错误的执行计划,原因主要有统计信息不准确,成本考虑不全,选择的并非执行时间最短的计划(最优!=时间最短)等。
查询执行引擎。查询执行引擎基于查询优化器生成的执行计划调用存储引擎的接口(hanler api)进行查询。在查询优化阶段就为每一张表创建了一个handler实例,优化器可以根据这些实例的接口来获取表的相关信息,例如表的列名、索引信息等。
返回结果。即使查询结果为null,返回的信息也会包括影响的行数,执行时间等信息。当查询缓存打开时,结果也将会存放到对应的缓存中。结果集的返回是增量返回的过程,服务端无需存放所有结果集即可开始传输,因此无需消耗太多内存,且客户端能获得及时的响应。返回结果要经过通信协议处理,通过TCP进行传输。
总结查询过程主要分为6步,客户端发送一条SQL——>若查询缓存打开,检查查询缓存,如果命中缓存,则立刻返回缓存结果。否则进入下一阶段——>SQL解析、预处理、生成执行计划——>根据执行计划,调用存储引擎的API来执行查询——>结果返回给客户端,同时缓存查询结果。
2. 存储引擎
存储引擎是一种如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。不同的存储引擎往往具备不同的存储机制,索引技巧,锁定水平等功能。主要的存储引擎有MyIsam 、InnoDB、 Memory、Archive、Federated等。在此主要介绍一下MyIsam 以及InnoDB两种存储引擎。
2.1 MyIsam
MyIASM是MySQL 5.5之前版本默认的存储引擎,它保存了表的行数count,在select count(*)时不必读表而可直接给出结果,读取时效率较高(但是加了where条件之后也需要遍历表)。但是它不支持事务,同时只支持表级锁,而不支持行级锁,因此当INSERT或UPDATE数据时需要锁定整个表,写入效率便会低一些。同时MyIsam不支持外键约束,因此当INSERT(插入)或UPDATE(更新)数据时即写操作需要锁定整个表,效率便会低一些。
MyIsam一般分为三种:静态MyIsam,动态MyIsam以及压缩MyIsam。静态MyIsam是最常用的,它存储的数据各列长度固定,读取效率高,容易恢复,但是存储空间占比较大,如下图所示,由于行是定长的,因此根据行号以及表头跳过前面的数据直接定位到对应的数据行。动态MyIsam存储的数据是varchar类型,不定长的,因此需要的存储空间较少,但是容易产生碎片,效率比较低。压缩MyIsam存储的是压缩表,占用空间最小,但是一旦压缩之后就不能被修改。
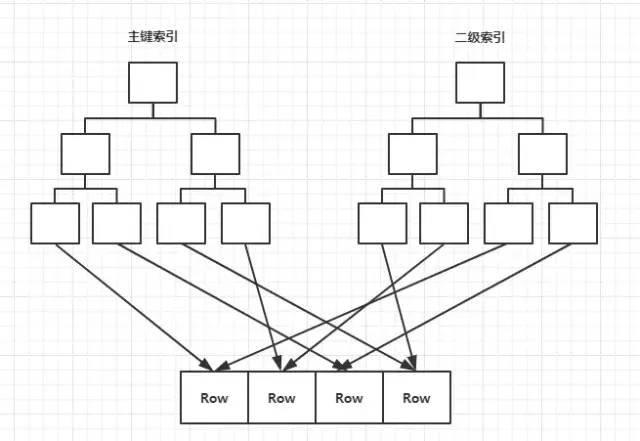
MyIsam索引是非聚簇索引结构,即索引和数据分离。MyIsam采用B+树来构建索引,B+树只有叶节点存储信息,叶节点data域存储的是真实数据的地址。
MyIsam可以在多个列上建立索引,主键上的索引称为主键索引,其他列的索引称为辅助索引。两者之间并无太多区别,只是主键索引要求key唯一。
2.2 InnoDB
InnoDB是事务型数据库的首选引擎,支持事务(ACID),支持行锁定和外键,是默认的MySQL引擎。InnoDB不保留数据库的行数,而且同一时刻对于不同的事务其可见的行数也是不一样的。count()只会统计计算对于当前事务而言可见的行数,而不是像MyIsam一样将总行数储存起来方便下一步查询。因此当数据量大的时候,采用count()计算行数时间会特别慢,而且得到的结果往往不是准确的数值。在InnoDB中,使用count查数据量实际上是通过辅助索引进行统计的,因为索引量较小,磁盘I/O较少。
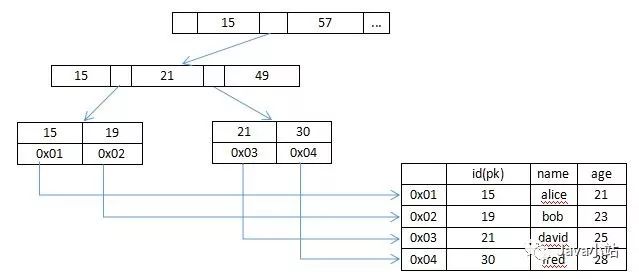
InnoDB本身也采用B+树作为索引结构,但是与MyIsam不同,InnoDB支持聚簇索引,也即是索引文件本身就是数据文件,叶节点data域存储的是数据本身。其基本结构如下图。每个页的大小等同于操作系统的页大小,一般为16k,因为操作系统以页为单位进行数据交换,这样每个页节点只需一次磁盘IO就可以完全载入内存,这个思想充分利用了磁盘预读原理和局部性原理。
InnoDB包含主键索引(聚簇索引)和非主键索引(非聚簇索引),主键索引叶节点存储的是真实的数据值,非主键索引存储的是主键的值。因此,一般通过非主键索引查数据往往需要首先获得主键值,在据此查找主键索引回表获取实际的数据信息,共两次I/O操作。因此也可知为什么不建议使用过长字段作为主键?因为所有的辅助索引都会引用主索引,过长的主键会使得辅助索引变的过大。
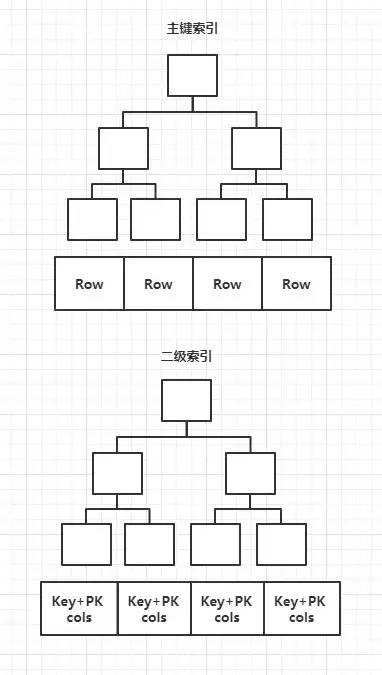
覆盖索引:索引的叶子节点已经包含了要查询的列,因此不用回表即可直接返回结果。例如有一个索引为(key1,key2),查询 select key2 from db where key1 ="...",则只需一次索引找到就可以查询到需要的数据。
非聚簇索引叶节点存储的不是行号(地址),而是主键列。该策略一般需要两次查找才能获取数据,效率比较低,但是优点是InnoDB移动数据行时无需更新主键,但是却会改变行指针,因此对于写密集型或者有较大更改删除需求,叶节点存储行号显然不太合适。
InnoDB严重依赖主键,若定义了主键,则InnoDB会选择主键来构建聚簇索引。但是若未显式定义,InnoDB会默认选择第一个不含null值的唯一索引作为主键索引。若没有这样的索引,则InnoDB会选择内置的rowID作为隐含的聚簇索引,随行写入而递增。
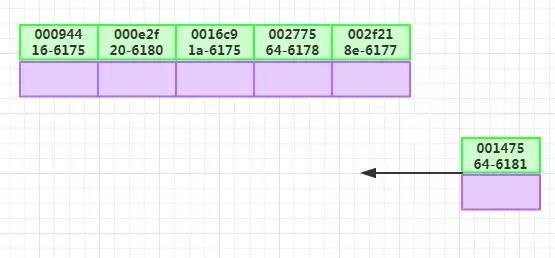
如下图所示,向聚簇索引中插入索引值时,或者主键被更新时,可能会导致页分裂,例如,一个页已经满了,但是需要插入一个新行,则需把该页分裂为两个页面,也分裂很占用存储空间,效率很低。为了避免这种情况,我们应选择与数据无关的主键和非随机值,减少更新数据带来的额外的分裂移动损失。一般情况下,默认采用自增主键,这样数据按照顺序写入,减少了B+树叶子结点的分裂情况,存取效率能够达到最高。
InnoDB支持行级锁和表级锁。行锁:用索引检索数据时,只锁住索引对应的行。表锁:未用到索引导致数据操作时将整个表锁起来进行检索。行锁是对索引加的锁,而非是对数据行加的锁。对于普通索引,当重复率较低时,依然采用行锁,但是重复率较高时,引擎会形成表锁加以保护。
InnoDB默认支持的数据隔离级别是可重复读,可重读级别下加以next-key lock,从而避免幻读。但是在一些分布式事务下,InnoDB一般会用到最高级的可串行化隔离级别。一般的锁算法包含三种。
record-lock:单行记录上的锁(记录上的索引)
gap lock :间隙锁,锁定一个范围,不包含记录(索引间隙)
next-key lock :相当于record+gap,锁定一个范围,不仅包含记录上的索引,还锁定索引之间的间隙,包含记录本身。
InnoDB正是对行查询采用了next-key lock,才可以在可重复度的隔离级别下防止幻读的产生。
此外,InnoDB还支持外键约束,目前只有它支持,保证了数据的完整性。外键约束共有若干种,其中父表指子表外键对应的主键表,子表表示外键所在的表。
cascade:父表更新时也删除对应的子表
setnull:删除更新后对应的外键列设为null
restrict:拒绝父表的删除和更新
InnoDB能够处理多重并发的更新需求,因此适合经常更新的表。
3. 索引
索引类似于字典的目录,是快速搜索的关键,可以在查找数据的时候将磁盘I/O次数控制在一个常数级。
3.1 索引类型
MySQL索引主要包含四种。
B-Tree 索引:最常见的索引类型,大部分引擎都支持B树索引。
HASH 索引:只有Memory引擎支持,使用场景简单。
R-Tree 索引(空间索引):空间索引是MyISAM的一种特殊索引类型,主要用于地理空间数据类型。
Full-text (全文索引):全文索引也是MyISAM的一种特殊索引类型,主要用于全文索引,InnoDB从MYSQL5.6版本提供对全文索引的支持。
其中,B-树索引又包括以下的索引类型。
普通索引 这是最基本的索引类型,而且它没有唯一性之类的限制。普通索引可以通过以下几种方式创建:
创建索引: CREATE INDEX 索引名 ON 表名(列名1,列名2,...);
修改表: ALTER TABLE 表名ADD INDEX 索引名 (列名1,列名2,...);
创建表时指定索引:CREATE TABLE 表名 ( [...], INDEX 索引名 (列名1,列名 2,...) );
UNIQUE索引 表示唯一的,不允许重复的索引,如果该字段信息保证不会重复例如身份证号用作索引时,可设置为unique:
创建索引:CREATE UNIQUE INDEX 索引名 ON 表名(列的列表);
修改表:ALTER TABLE 表名ADD UNIQUE 索引名 (列的列表);
创建表时指定索引:CREATE TABLE 表名( [...], UNIQUE 索引名 (列的列表) );
主键:PRIMARY KEY索引 主键是一种唯一性索引,但它必须指定为“PRIMARY KEY”。
主键一般在创建表的时候指定:“CREATE TABLE 表名( [...], PRIMARY KEY (列的列表) ); ”。
我们也可以通过修改表的方式加入主键:“ALTER TABLE 表名ADD PRIMARY KEY (列的列表); ”。每个表只能有一个主键。(主键相当于聚合索引,是查找最快的索引)
注:不能用CREATE INDEX语句创建PRIMARY KEY索引
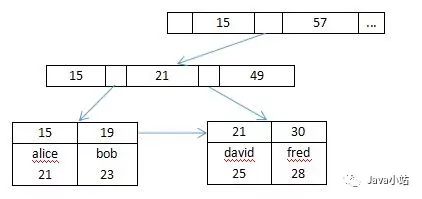
在InnoDB中,默认采用B+树索引。B+树索引的数据都在叶子节点上,在叶节点上增加了单向顺序访问指针,每个指针指向相邻的数据节点的地址。这样做range查询时,只需要找到两个端点即可进行遍历,而不需要获取所有的节点。B树相比B+树不同之处在于非叶节点也可存储信息,在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。相比其他索引,选择B+树做索引的主要原因有:
hash索引无序,IO复杂度高。哈希索引适合做等值查询,但是不宜range查询,无法利用索引进行排序。且哈希索引不支持多列联合索引的最左匹配规则。此外,随着数据量的增大,若有大量重复key值,则哈希索引存在碰撞问题,效率会大大降低。
二叉树索引高度不均匀,不能自平衡。此外I/O代价高,且二叉树必须放入内存,但数据量过大时索引只能放入磁盘。
红黑树高度会随着数据量的增大而增大,造成磁盘的I/O读写过于频繁,进而导致效率低下。而B+树可以有多个子女,因此可以有效降低树的高度。
3.2 索引建立原则
在讲解索引建立原则之前,首先介绍一些sql语句的一些原理从而更好的理解索引。
join是写sql时常用的关键字之一,能够连接两个数据库,常用的有left join ,right join,inner join,在此主要对join内部的原理进行一下解释,并不过分关注代码的表现形式。举例来讲,left join的左表称为驱动表(N行),右表称为匹配表(被驱动表)(M行)。在MySQL中,join采用的是嵌套循环的实现方式(Nested-Loop Join)。该方式有3种变种。
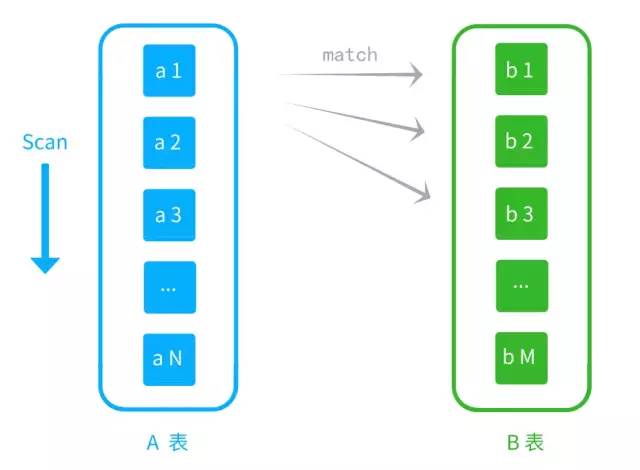
Simple Nested-Loop Join,简单嵌套循环。双层循环,通过外层表与内层表进行数据匹配。共需N*M次比较,性能比较一般。
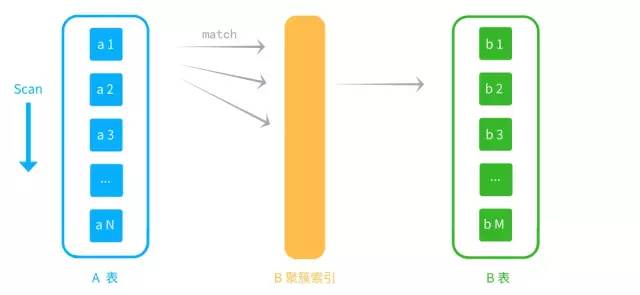
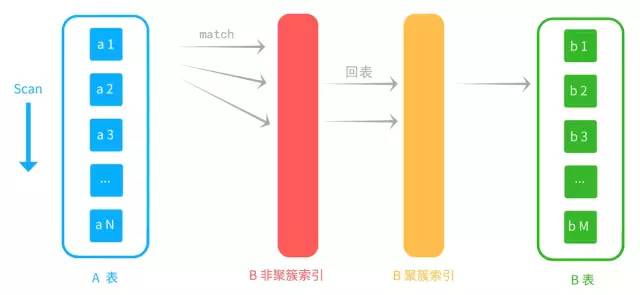
Index Nested-Loop Join,索引嵌套循环。外层表匹配条件直接与内层表索引进行匹配,比较次数为N*h(索引高度)。若比较的值为主键,则可直接利用聚簇索引拿到数据进行比较,若不是主键,则需先使用非聚簇索引,在进行一次回表操作查主键的聚簇索引,性能会大大下降,因此最好使用主键作为比较条件。
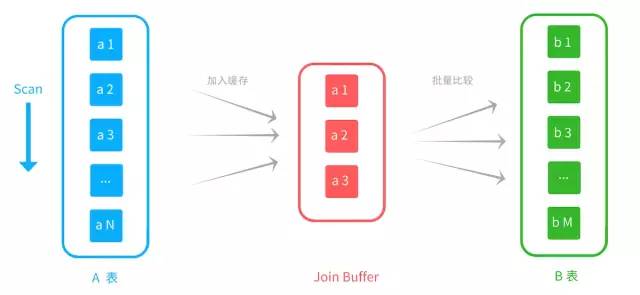
Block Nested-Loop Join,块嵌套循环。对驱动表缓存多条数据,批量比较,也减少了匹配表的扫描次数。但是比较次数仍然为N*M。
索引访问数据其实是乱序访问数据,而全表扫描是顺序访问磁盘。因此,对于区分度不高的列建立索引,乱序访问磁盘反而使得磁盘移动消耗更大,因为对于性别等区分度不高的列建立索引实际上MySQL走的也是全表扫描。
索引在sql语句中的常见使用场景有以下几点:
where 查询条件
order by key。若key字段未建立索引,则需要将所有查询出的数据进行外部排序、若建立了索引,索引本身即为有序的。
join on 的连接条件。原因如上所述。
select字段进行索引覆盖。优先使用索引的优势在于体积小,但是索引维护开销比较大,因此不要为每个字段都建立索引。
因此,索引字段设计要满足以下准则。
尽量使用整形表示字符串(理论上,因为实际生产中类型转化隐含很多bug)。较小的数据类型通常效率会更高,因为占用了更少的磁盘、内存、以及CPU缓存,处理时消耗的时间也更少。
尽可能字段not null,若为null需要做特殊处理。
单表字段不宜太多。
建立索引原则总结下来包含但不限于以下若干种。
选择唯一性索引。
为经常需要排序分组和join的字段建立索引。
为常作为查询条件的字段建立索引。
尽量使用数据量少的索引。
限制索引的数目。索引并非越多越好,更新表会变的愈发浪费时间。
尽量使用前缀来索引。若索引字段过长,最好使用值的前缀来建立索引。例如密码等字段,前缀的标示性比较高,通过部分前缀就能有良好的区分度,从而节省空间。
尽量使用区分度比较高的列作为索引。区分度为count(distinct col)/count(*),表示字段不重复的比例。
最左前缀匹配原则。MySQL会一直向右匹配直到遇到范围查询(>、 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
索引列不能参与计算。带函数的查询不参与索引。
尽量的拓展索引而非新建索引。
删除不再使用或很少使用的索引。
实际过程中,加快sql执行时间最常用的解决策略就是建索引,但是索引也有自己的不足之处。
空间:索引需要占用空间;
时间:查询索引需要时间;
维护:索引须要维护(数据变更时)。
4 SQL优化
在讲解优化之前,首先介绍一下sql的执行顺序,从而更好的理解索引并且方便后续的优化。
from db1 join db2 on (连接条件)
where 查询条件
group by id
with 语句
having 条件
select 字段
distinct (select)
order by 排序条件
limit 限制条件
讲MySQL服务器传递给客户端查询数据的时候可以使用limit实际上只是限制了传输了数据量,减轻带宽的压力,但是并不会缓解服务器查询运算的压力。因此为了优化sql,需要尽量在数据库连接以及查询时就过滤掉大部分数据。
随着数据量的增长以及业务逻辑的复杂,难免会遇到慢sql,对sql问题进行排查通常可以采取下面的三种方式。
show process list命令查看当前所有的连接信息。
explain命令查看sql语句的执行计划。
开启慢查询日志,查看慢查询的sql。
对于慢sql,有两种情况,偶尔很慢和一直很慢。偶尔很慢潜在的原因可能有数据库在刷新脏页或者迟迟拿不到锁。这种情况可以稍微等待一下。
若sql一直都很慢,则很大原因即是sql本身的问题。通常有如下的原因。
字段未设置索引
字段有索引,但是没有用上
函数操作导致没有用上索引
数据库选错了索引,或者开始全表扫描,原因可能是统计的失误导致系统没有走索引,而是全表扫描(可以force index)。
慢sql的一个原因就是索引失效,因此写sql语句的时候就要注意合法的书写,避免不必要的错误。索引失效的常见情形有:
条件中有or(or两端都有索引才可行)。
多列索引不符合最左前缀规则。
like查询以%开头。
查询的数据量太大。
采用了not in,not exists,!=,<>等。
字符串类型没有加括号(实际中可能忽略的情况)。
做了函数运算 。
要弄懂慢查询的原因,需要有一定的条理性进行优化,按照步骤进行检查。
先运行看看是否真的很慢,注意设置SQLNOCACHE。
where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高。
explain查看执行计划,是否与上述预期一致(从锁定记录较少的表开始查询)。
order by limit 形式的sql语句让排序的表优先查。
了解业务方使用场景。
加索引时参照建索引的几大原则。
观察结果,不符合预期继续从头分析。
检查出问题,再针对性的进行解决。目前主要的调优方案有以下几种:
列尽量是数值类型,且长度尽可能的短
建立单列索引
根据需要建立联合索引
只查询业务需要的字段,若能被索引覆盖,将极大的提升查询效率
多表连接字段上建立索引
排序字段建立索引
where条件不要使用运算函数
避免嵌套子循环,将其优化为连接查询。
查询优化器。我们可以使用explain语句来查看sql的执行计划,内部原理主要基于查询优化器。一条sql语句,可以有不同的执行方案,优化器会选择一种成本最低的方案,选择过程分为4步。1. 根据搜索条件,找到所有可能使用的索引。2. 计算全表扫描的代价。3. 计算不同索引执行查询的代价。4. 对比各种方案,选择成本最低的一个。但是实际过程中,sql有可能走全表扫描而不是索引,主要原因是选择方案通过索引的区分度进行判断,区分度越高,走索引的概率越大,但是区分度通过采样来获取,所以会出现判断失误的情况,这也可能导致慢sql,对此可强制使用对应的索引。
由于篇幅原因,将MySQL知识拆分为几个部分进行总结。下一篇文章中,将会对MySQL的事务,分库分表,存储过程等进行总结。
参考文献
《高性能MySQL》
MySQL——索引实现原理:(https://juejin.im/post/5bd7a97de51d45400d5d7b18)
MySQL索引原理:(https://zhuanlan.zhihu.com/p/34840329)
MyISAM和InnoDB的索引实现:(https://www.cnblogs.com/zlcxbb/p/5757245.html)
MYSQL-索引:(https://segmentfault.com/a/1190000003072424)
MySQL 深入浅出:join 的使用和原理:(https://www.jianshu.com/p/6086365a73bd?utm_source=tuicool&utm_medium=referral)
MySQL 索引及查询优化总结:(https://juejin.im/post/5c2c8dace51d455d382ee046)
MySQL索引原理及慢查询优化:(https://tech.meituan.com/2014/06/30/mysql-index.html)

















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









