



 本文介绍了在Django项目中提升代码性能的方法,包括使用line_profiler分析瓶颈,开启SQL记录,避免循环查询,利用select_related和prefetch_related减少查询,以及使用values()和values_list()优化序列化。通过实例演示了这些技术如何显著提高查询效率。
本文介绍了在Django项目中提升代码性能的方法,包括使用line_profiler分析瓶颈,开启SQL记录,避免循环查询,利用select_related和prefetch_related减少查询,以及使用values()和values_list()优化序列化。通过实例演示了这些技术如何显著提高查询效率。
编者注:原文发表于Medium, 作者Ryley Sill, 大江狗翻译整理,原文链接在本文结尾。本文值得收藏天天刷,可以帮你避免写出糟糕的代码。
我最近通过Django建立了Carta的场景建模平台。通过一些研究,我意识到我并不知道如何编写高性能的代码。我现在仍然不是很懂,但是我希望自己能早点了解这些知识。
免责声明
以下旨在向您介绍可用于优化Django代码的不同技术。结果将根据您的数据库,模型和数据的性质而有所不同。
入门-示例数据模型
我创建了一个由书籍,页面,作者和图书馆组成的简单数据模型,因此我们可以使用下面模型概述本文的技术。该数据库拥有10,000本书,1,000,000页,1,000位作者和1,000个图书馆。这些页面随机分配给书籍,而这些图书则随机分配给作者和图书馆。
class Library(models.Model): name = models.CharField(max_length=200, default='') address = models.CharField(max_length=200, default='')class Author(models.Model): name = models.CharField(max_length=200, default='')class Book(models.Model): library = models.ForeignKey( Library, on_delete=models.CASCADE, related_name='books', ) author = models.ForeignKey( Author, on_delete=models.CASCADE, related_name='books' ) title = models.CharField(max_length=200, default='') address = models.CharField(max_length=200, default='') def get_page_count(self): return self.pages.count()class Page(models.Model): book = models.ForeignKey( Book, on_delete=models.CASCADE, related_name='pages', ) text = models.TextField(null=True, blank=True) page_number = models.IntegerField()使用line_profiler
如果我们不知道为什么我们的代码很慢,就很难弄清楚如何对其进行优化。line_profiler是一个很酷的python模块,它告诉我们执行一个函数中的每一行需要多少时间。在开始之前,请使用安装软件包pip install line_profiler。
这是我通常使用的方式。想象一下,我们需要一个函数来返回数据库中与每个图书馆(library)相对应的所有书籍列表。假设我们最终接到了这样的任务,我们可能按如下写代码,返回结果是一个字典,key是每个图书馆的id,value是书籍列表……
def get_books_by_library_id(): libraries = Library.objects.all() result = {} for library in libraries: books_in_library = library.books.all() result[library.id] = list(books_in_library) return result当数据库中数据很少时,上述查询会运行得很快,然而在我们的例子中,它将运行的非常,因为数据众多。要找出函数执行过程中计算机在哪里花费了最多的时间,可以IPython在调用可疑函数的位置之前在视图函数中添加调试器。
from django.http import HttpResponsefrom test_app.helpers import get_books_by_library_iddef books_by_library_id_view(request): from IPython import embed; embed() books_by_library_id = get_books_by_library_id() ... return HttpResponse(response)…执行任何触发视图的操作,等待服务器停止运行并IPython启动shell程序,line_profiler将其作为扩展加载到IPython外壳程序中,然后使用来配置功能lprun -f your_function_name your_function_name()。如果需要将任何参数传递到函数中,请将其传递到该命令最后一部分的括号内。这时你将看到每行程序的运行时间。
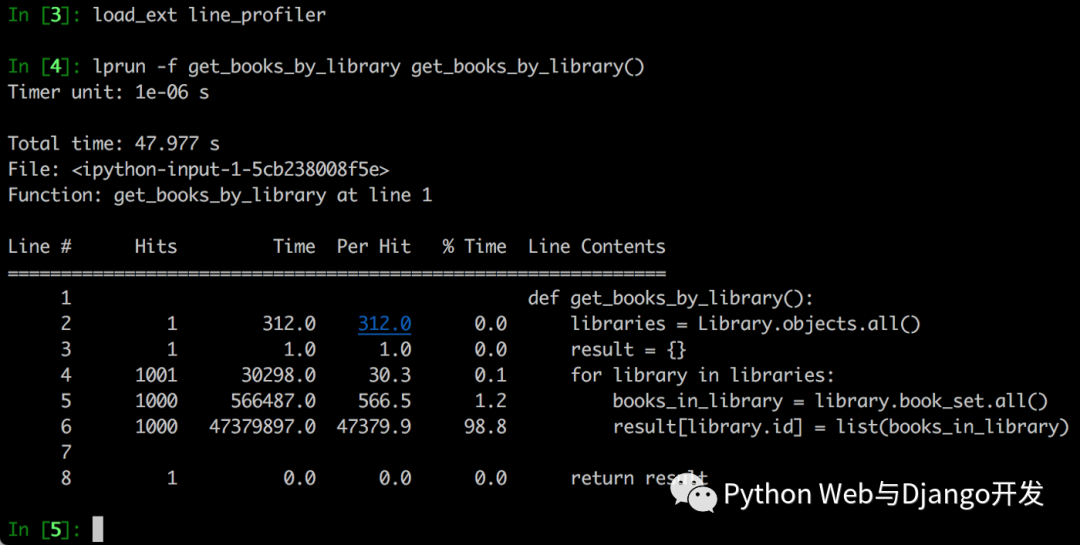
该表% Time列会告诉拟执行该代码行花了多少时间。因此,在47.977秒的执行时间中,执行整个函数最耗时的是第6行,占总时间的98.8%,在这里我们library.books.all()通过将强制获取每个library里的数据。
该表Hits列告诉您该行代码执行了多少次数据库查询。看起来第6行执行了1000次Library数据库的查询。这意味着我们要进行1000个SQL查询,这可能就是为什么此功能如此缓慢的原因。在后面的部分中,我们将介绍如何使其更快。
开启SQL记录
当我们真正地研究一个函数来查看瓶颈在哪里时,打开SQL日志记录可能会很有用。
# settings.pyLOGGING = { 'version': 1, 'filters': { 'require_debug_true': { '()': 'django.utils.log.RequireDebugTrue', } }, 'handlers': { 'console': { 'level': 'DEBUG', 'filters': ['require_debug_true'], 'class': 'logging.StreamHandler', } }, 'loggers': { 'django.db.backends': { 'level': 'DEBUG', 'handlers': ['console'], } }}我们可以添加此代码段以settings.py获取代码中执行的每个SQL查询的完整打印输出。通常在任何时候都保持太多时间,但是在给定的代码块中查看正在执行多少个查询以及执行每个查询需要花费多长时间可能会很有启发。
我通常使用SQL日志记录的方式是将调试器放在可疑的代码块之前和之后。然后,我执行代码,单击第一个调试器后清除终端,继续执行第一个调试器,并调查在两次调试之间执行的查询,同时注意重复,意外或缓慢的查询。
这篇文章不会涉及SQL查询优化,但是我们将讨论如何减少或消除函数中重复查询的数量。
大江狗注:使用django debug toolbar查看SQL查询次数与耗时比Ipython和SQL日志更方便。避免循环查询
def get_books_by_library_id(): libraries = Library.objects.all() result = {} for library in libraries: books_in_library = library.books.all() result[library.id] = list(books_in_library) return result回到我们那个身患绝症的功能get_books_by_library,问题在于我们需要频繁地访问查询每个图书馆,以获取每个图书馆的书籍列表。如果您只有几个图书馆,每个图书馆有数百万本书,这代码可能就是您想要的。但是如果您有成千上万的图书馆,每个图书馆都有成千上万的书,那么您的代码现在将执行成千上万次的查询,才能完成这个简单的函数。
为了解决这个问题,我们可以预先获取所有书籍,如下所示:
def get_books_by_library_id_one_query(): books = Book.objects.all() result = defaultdict(list) for book in books: result[book.library_id].append(book) return resultBOOM. 现在无论数据库中存在多少个图书馆,您都只执行一次SQL查询, 即可获取每个图书馆的id,及每个图书馆id对应的书籍列表了,返回结果和前面是一样的。
那么我们如何知道这是否更快呢?Python有一个很酷的小模块,称为timeit,告诉您执行一个函数需要多长时间。
In [12]: timeit(get_books_by_library_id, number=10)Out[12]: 6.598360636999132In [13]: timeit(get_books_by_library_id_one_query, number=10)Out[13]: 0.677092163998168尽管我们的第二个函数必须循环处理10,000本书,但是通过消除频繁访问数据库的次数,它的运行速度仍比原始功能快近10倍。请记住,这一切都取决于数据的稀疏性/密度和规模。以我的经验,如果SQL查询的数量随着其他一些输入的增加而增加,则代码运行通常会变慢。
select_related()
想象一下,如果你希望以Harry Potter and the Sorcerer's Stone by J.K. Rowling字符串的形式导出一个图书馆里所有的书籍数据。
Django有些方法使减少不必要的数据库查询变得容易。如果您不了解幕后发生的事情或者不了解这些方法,你可能会写出如下代码:
def get_books_by_author(): books = Book.objects.all() result = defaultdict(list) for book in books: author = book.author title_and_author = '{} by {}'.format( book.title, author.name ) result[book.library_id].append(title_and_author) return result问题出在这里:每次访问时,book.author您所做的查询都等同于Author.objects.get(id=book.author_id)。如果要遍历成千上万本书籍,那么您还要进行成千上万个完全不必要的查询。使用select_related可以避免这一点:
def get_books_by_author_select_related(): books = Book.objects.all().select_related('author') result = defaultdict(list) for book in books: author = book.author title_and_author = '{} by {}'.format( book.title, author.name ) result[book.library_id].append(title_and_author) return resultselect_related通过执行一个更复杂的SQL查询来工作,该查询还返回相关对象的字段。因此,您不仅要获取有关所有书籍的数据,而且还要获取每本书作者的数据。现在,当您访问时,您book.author实际上是在访问作者的缓存版本,而不是进行单独的数据库查询。
使用select_related后到底快多少?我使用该timeit模块运行了这两个函数,发现该函数使用select_related速度提高了32倍:
In [12]: timeit(get_books_by_author, number=10)Out[12]: 41.363460485998075In [13]: timeit(get_books_by_author_select_related, number=10)Out[13]: 1.2787263889913447注:为了避免跨“多对多”关系加入会产生更大的结果集,select_related仅限于单对多和一对一关系。为了遍历反向ForeignKey或ManyToMany关系,我们需要prefetch_related方法。
prefetch_related()
prefetch_related类似于select_related防止不必要的SQL查询。不像select_related一次性获取主要和相关对象,prefetch_related对每种关系进行单独的查询,然后将结果“结合”在一起。这种方法的缺点是它需要多次往返数据库。
Author.objects.filter(name__startswith ='R').prefetch('books')工作原理:首先触发一个请求,该请求运行主查询Author.objects.filter(name__startswith=letter),然后Book.objects.filter(author_id__in=PKS_OF_AUTHORS_FROM_FIRST_REQUEST)执行,最后将两个响应合并到一个查询集中,该查询集中将Author每个作者的书缓存在内存中。因此,您最终得到的结果与相似,select_related但您通过不同的方式到达那里。
尽管您可以prefetch_related在任何使用的地方使用select_related,但是通常,您的代码可以更快地运行,select_related因为它可以在一个SQL查询中获取所需的一切。但是,如果您的数据特别稀疏(几百万本书到几个图书馆),尽管有额外的数据库旅行,您可能会看到性能提高。因此,如果有疑问,请尝试两种方法,然后看看哪种方法最重要。
总结一下:如果你进行数据库查询时还需要获取关联对象的信息,使用select_related以及prefetch_related。
values()和values_list()
将SQL响应序列化为python数据所花费的时间与返回的行数和列数成正比。在下面的函数中,即使我们只需要作者名字,书的图书馆id和书籍名称 ,我们也将书和作者模型上所有字段进行序列化了。我们还无缘无故地初始化Django模型实例,尽管我们没有对其进行任何特殊处理(例如调用模型方法)。
def get_books_by_author_select_related(): books = Book.objects.all().select_related('author') result = defaultdict(list) for book in books: author = book.author title_and_author = '{} by {}'.format( book.title, author.name ) result[book.library_id].append(title_and_author) return result因此,我们产生了相当大的开销,可以通过调用或在queryset上仅询问我们需要的字段来消除这些开销:.values().values_list()
def get_books_by_author_select_related_values(): books = ( Book.objects .all() .select_related('author') .values('title', 'library_id', 'author__name') ) result = defaultdict(list) for book in books.iterator(): title_and_author = '{} by {}'.format( book['title'], book['author__name'] ) result[book['library_id']].append(title_and_author) return resultdef get_books_by_author_select_related_values_list(): books = ( Book.objects .all() .select_related('author') .values_list('title', 'library_id', 'author__name') ) result = defaultdict(list) for book in books.iterator(): title_and_author = '{} by {}'.format( book[0], book[2] ) result[book[1]].append(title_and_author) return result.values()返回模型实例的字典表示形式的列表:[{'title': 'Snow Crash', 'library_id': 9, 'author__name': 'Neil'}, ...]并.values_list()返回表示模型实例的元组的列表[('Snow Crash', 9, 'Neil'), ...]。
那么这些功能要快多少?通过仅抓住我们需要的字段,这些函数使用.values()和.values_list()运行的速度比原始函数快7倍。
In [13]: timeit(get_books_by_author_select_related, number=10)Out[13]: 1.2787263889913447In [14]: timeit(get_books_by_author_select_related_values, number=1)Out[14]: 0.19064296898432076In [15]: timeit(get_books_by_author_select_related_values_list, number=1)Out[15]: 0.17425400999491103这里要注意的是这些模型是超轻量级的-模型上只有4个字段Book。如果我们使用具有大量字段的模型,则结果将更加极端。即使您需要对象上的所有字段,.values()也.values_list()可以通过跳过模型初始化来显着提高性能。您可以通过不传递任何字段作为参数来获取所有字段。
# returns list of model instancesdef get_book_instances(): return list( Book.objects .all() .select_related('author') )# returns list of dictionaries representing model instancesdef get_book_dictionaries(): return list( Book.objects .all() .select_related('author') .values() )# returns a list of dictionaries with the name of each bookdef get_book_dictionaries_title_only(): return list( Book.objects .all() .select_related('author') .values('title') )获得书籍的字典表示速度比请求模型实例快6.5倍,并且要求书籍中的特定字段的速度快8.8倍。
In [64]: timeit(get_book_instances, number=100)Out[64]: 12.904168864974054In [65]: timeit(get_book_dictionaries, number=100)Out[65]: 2.049193776998436In [66]: timeit(get_book_dictionaries_title_only, number=100)Out[66]: 1.4734381759772077初始化Django模型实例非常昂贵。如果仅使用模型上的数据,则最好使用其字典或元组表示形式。
bulk_create()
这很简单。如果我们要一次创建多个对象,请使用bulk_create而不是在循环中创建对象。顾名思义,bulk_create无论我们要插入多少个对象,都将使用一个查询将对象列表插入数据库。
可能插入的对象如此之多,以至于生成的单个查询bulk_create比多个较小的查询要慢。在这种情况下,您可以batch_size=SIZE_OF_BATCH作为参数传入,这会将主查询分解为较小的查询。
我不知道有关在合理使用之前需要插入的对象数量batch_size或如何确定批处理大小的经验法则。通常,我会忽略它,直到明确存在瓶颈,然后batch_size从那里确定一个合适的瓶颈。
SQL(通常)比Python快
假设您想要一个返回每个图书馆所有书籍的页面数之和。使用上面学到的知识,您可能会得到如下代码:
def get_page_count_by_library_id(): result = defaultdict(int) books = Book.objects.all().prefetch_related('pages') for book in books: result[book.library_id] += book.get_page_count() return result即使这只会触发2次查询,我们仍然必须将所有书籍拉入内存并遍历其中的每一本书。这种事情很容易通过annotation解决。
from django.db.models import Sumdef get_page_count_by_library_id_using_annotation(): result = {} libraries = ( Library.objects .all() .annotate(page_count=Sum('books__pages')) .values_list('id', 'page_count') ) for library_id, page_count in libraries: result[library_id] = page_count return result现在,您无需拉出一堆Django实例到内存中并在每个实例上调用模型方法,而只是拉出您实际上关心的两个值Library:id和和page_count。我们的新功能运行速度比原始功能快115倍。
In [66]: timeit(get_page_count_by_library_id, number=10)Out[66]: 158.0743614450039In [67]: timeit(get_page_count_by_library_id_using_annotation, number=10)Out[67]: 1.3725216790044215这个例子很简单,但是annotation可以做很多事情。如果在大型查询集上进行数学运算时遇到性能问题,请考虑编写annotation以将其工作交给数据库。
总结
如果您正在从事Django的项目开发,而对性能几乎没有考虑或没有考虑过,那么本文低调的成果可以帮助您入门。在大多数情况下,上述技术将大大提高性能,而不会在代码的可读性上打折。
原文:
https://medium.com/@ryleysill93/basic-performance-optimization-in-django-ebd19089a33f
相关阅读
Django QuerySet查询基础与技巧。有了她,再也不用担心SQL注入了。
Django基础(29): select_related和prefetch_related的用法与区别

















 64
64

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









