





 本文详细介绍了Oracle SQL中的三种常见表连接方式:Nested Loop Join(适合大表与小表关联)、Hash Join(适合大表之间关联)和Sort-Merge Join(无驱动表,可能产生大量随机读)。文中通过实例分析了各种连接方式的适用场景和性能特点,并展示了如何使用Hint来指导查询优化。
本文详细介绍了Oracle SQL中的三种常见表连接方式:Nested Loop Join(适合大表与小表关联)、Hash Join(适合大表之间关联)和Sort-Merge Join(无驱动表,可能产生大量随机读)。文中通过实例分析了各种连接方式的适用场景和性能特点,并展示了如何使用Hint来指导查询优化。

在Oracle SQL语句中,如果from后面有多个表时,表的连接方式是一个很重要的考量。

从Oracle 6开始,优化器就支持下面4种表连接方式:
— 嵌套循环连接(Nested Loop Join)
— 群集连接(Cluster Join)
— 排序合并连接(Sort-Merge Join)
— 笛卡尔连接(Cartesian Join)
在Oracle 7.3中,新增加了哈希连接(Hash Join)。
在Oracle 8中,新增加了索引连接(Index Join)。
在这些表连接的方法中,Nested Loop Join和Hash Join及Sort-Merge Join是比较常见的。
(1)Nested Loop Join
这种场景一般适用于大表和小表的关联,准确来说应该是大的行集与小的行集,一般小表适用为驱动表,对于小表中的匹配记录和大表做关联,此时小表是在外部循环,大表在内部循环,小表中的记录都和大表做一个关联。
SQL> create table t as select *from dba_objects where object_id is not null;
SQL> create table t1 as select *from user_objects where object_id is not null;
SQL> exec dbms_stats.gather_table_stats(user,'T',cascade=>TRUE);
SQL> exec dbms_stats.gather_table_stats(user,'T1',cascade=>TRUE);
SQL> create unique index ind_t on t(object_id);
SQL> create unique index int_t1 on t1(object_id) ;
SQL> select count(*)from t;
COUNT(*)
----------
74552
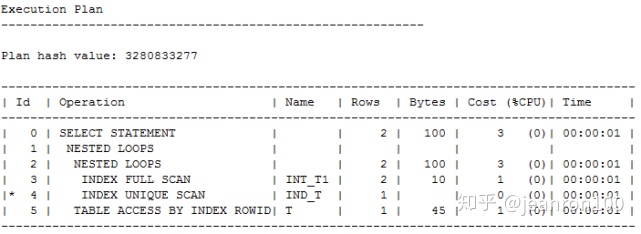
下面的例子,表t1中的数据较少,表t中的数据多,就以表t1为驱动表,走了全索引扫描查取到t1的数据,然后对于t1中的数据和t做匹配,匹配时走了唯一性扫描。
.select t.object_id,t.object_name,t.object_type,t.status from t,t1 where t.object_id=t1.object_id;
(2)Hash Join
这种场景适用于大表和大表之间的关联。通过Hash算法来做两个表之间的匹配映射。
SQL> create table t as select *from dba_objects where object_id is not null;
SQL> create table t1 as select *from dba_objects where object_id is not null;
SQL> exec dbms_stats.gather_table_stats(user,'T',cascade=>TRUE);
SQL> exec dbms_stats.gather_table_stats(user,'T1',cascade=>TRUE);
SQL> create unique index ind_t on t(object_id);
SQL> create unique index int_t1 on t1(object_id) ;
SQL> select count(*)from t;
COUNT(*)
----------
74552
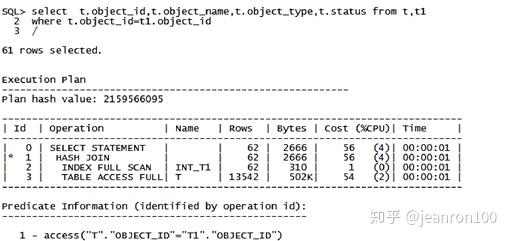
对于表t1中的记录,都是通过Hash映射来匹配表t中的记录。对于CPU的资源消耗还是相对较多的,因为内部做了大量的计算。从生产环境中的实践来说,Hash Join还是不错的,特别是在和并行结合之后。
select t.object_id,t.object_name,t.object_type,t.status from t,t1 where t.object_id=t1.object_id;
(3)Sort-Merge Join
对于Sort-Merge Join来说,可能略微有些陌生。
在数据库中有一个隐含参数对应,默认是开启的,见下表。

Sort-Merge Join相关参数
因为这种连结方式使用不当会消耗大量的系统资源,在一些生产系统中都选择手动禁用这种连结。
这种连结的运行原理相比Nested Loop Join和Hash Join而言没有驱动表,所以Sort-Merge Join可能会产生大量的随机读。
比如我们有表emp、dept。
查询语句为:
select empno,ename,dname,loc from emp,dept where emp.deptno =dept.deptno
如果采用Sort-Merge Join,就会对emp、dept表进行order by 的操作。
类似下面两个操作:
select empno,ename ,deptno from emp order by deptno;
select deptno,dname,loc from dept order by deptno;
因为排序后的数据都是有序的,然后对两个子结果集根据deptno进行匹配。
选择两端的数据列,根据列的要求筛选数据。
我们先来看一个使用Sort-Merge Join的执行计划,实际中需要用到Sort-Merge Join的场景就是在类似下面形式的查询中
where tab1.column1 between tab2.column2 and tab2.column3
我们可以使用Hint ordered来指定连接方式驱动,或者使用hint use_merge来引导查询走Sort-Merge Join,下面简单模拟一下。
(1)使用Hint ordered,语句如下。
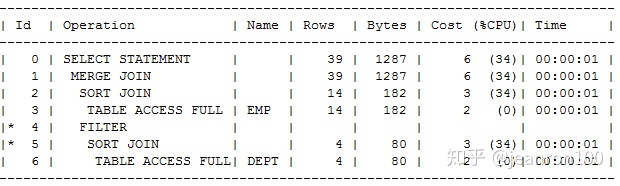
SQL> select /*+ordered*/ empno,ename,dname,loc from emp,dept where emp.deptno between dept.deptno-10 and dept.deptno+10;
语句的执行计划如下:
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("EMP"."DEPTNO"<="DEPT"."DEPTNO"+10)
5 - access(INTERNAL_FUNCTION("EMP"."DEPTNO")>="DEPT"."DEPTNO"-10)
filter(INTERNAL_FUNCTION("EMP"."DEPTNO")>="DEPT"."DEPTNO"-10)
可以看到对emp和dept都做了全表扫描,对数据进行了排序,然后根据deptno对结果集进行了匹配和关联,最后把结果集输出。
(2)使用Hint use_merge来实现相同的效果。
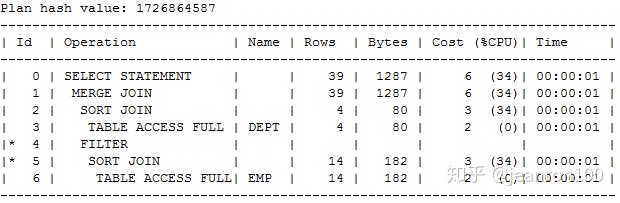
SQL> select /*+use_merge(dept,emp)*/ empno,ename,dname,loc from emp,dept where emp.deptno between dept.deptno-10 and dept.deptno+10;
语句的执行计划如下:
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("EMP"."DEPTNO"<="DEPT"."DEPTNO"+10)
5 - access("EMP"."DEPTNO">="DEPT"."DEPTNO"-10)
filter("EMP"."DEPTNO">="DEPT"."DEPTNO"-10)
合并排序的思路和数据结构中的合并排序算法相似,适合在数据筛选条件有限或者返回结果已经排序的场景中使用。如果本身表中的数据量很大,做Sort-Merge Join就会耗费大量的CPU资源,临时表空间相比来说不是很划算,完全可以通过其他的连接来实现。

















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









