





正则表达式是一个特殊的字符序列,能帮助用户检查一个字符串是否与某种模式匹配,从而达成快速检索或替换符合某个模式、规则的文本。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。re 模块使 Python 语言拥有全部的正则表达式功能。
本章就来学习一下re模块常见的几个方法:
- 目录
- re.compile()
- re.match()
- re.search()
- .group(num)、.groups()
- pattern.findall()
- re.sub()
- re.split()
re.compile()
- 基本格式:re.compile(pattern [, flags])-->pattern
-
- pattern :正则表达式字符串;
- flags:可选参数,匹配模式标志位:
- 功能:根据包含正则表达式的字符串创建模式对象;
- pattern:
- 字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
- 部分符号有特殊的含义,前置反斜杠来进行标识,反斜杠本身需要使用反斜杠转义,下表列出了正则表达式模式语法中的特殊元素。
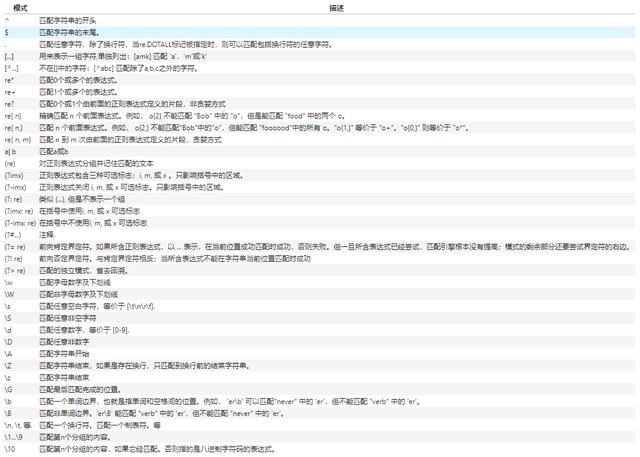
- flags:
主要的匹配模式标志位见下表,当需要多个标志时可以通过按位 OR(|) 它们来指定。

re.match()
- 基本格式:re.match(pattern, string [, flags])-->object/none
- pattern :正则表达式字符串,或经re.compile生成的模式对象;
- string:要匹配的字符串;
- flags:同re.compile;
- 功能:从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none;
import rea = '你'print(re.match(a, '你好帅')) # 在起始位置,返回一个object,print(re.match(a, '曾经的你好帅')) # 不在起始位置# 其中span=(0, 1)表示匹配字符串所在区间
None
re.search()
基本格式: re.search(pattern, string [, flags])-->object/none-
- pattern :同re.match;
- string:同re.match;
- flags:同re.match;
import reprint(re.search('www', 'www.runoob.com')) # 在起始位置匹配print(re.search('com', 'www.runoob.com')) # 不在起始位置匹配print(re.search('xxx', 'www.runoob.com')) # 无匹配None
.group(num)、.groups()
在使用.search()和.match()时,我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式:
- .group: 根据要求返回特定子组要求的字符串;
import rere_telephone=re.compile(r'^(d{3})-(d{3,8}$)')print(re_telephone.match('010-12345').group())print(re_telephone.match('010-12345').group(1))print(re_telephone.match('010-12345').group(2))010-12345
010
12345
- .groups(): 返回一个包含所有小组字符串的元组;
print(re_telephone.match('010-12345').groups())('010', '12345')
pattern.findall()
- 基本格式:pattern.findall(string[, pos[, endpos]])-->List
- string:待匹配的字符串;
- pos:可选参数,指定字符串的起始位置,默认为 0;
- endpos:可选参数,指定字符串的结束位置,默认为字符串的长度;
import repattern = re.compile(r'd+') # 查找数字print(pattern.findall('run88oob123google456'))print(pattern.findall('run88oob123google456', 0, 10))print(pattern.findall('runoobgoogle')) # 无匹配项发明会空字符串['88', '123', '456']
['88', '12']
[]
re.sub()
基本格式: re.sub(pattern, repl, string[, count, flags])-->str-
- pattern :同re.match;
- repl:替换的字符串,也可为一个函数;
- string:同re.match;
- count:可选参数,模式匹配后替换的最大次数,默认 0 表示替换所有的匹配项;
- flags:同re.match;
import rephone = "2004-959-559 # 这是一个国外电话号码"print(phone)# 删除字符串中的 Python注释num = re.sub(r'#.*$', "", phone)print(num)# 删除非数字(-)的字符串num = re.sub(r'D', "", phone)print( num)2004-959-559 # 这是一个国外电话号码
2004-959-559
2004959559
re.split()
- 基本格式:re.split(pattern, string[, maxsplit=0, flags=0])-->List
- maxsplit:最大分隔次数,默认为 0,不限制次数;
- 其他参数:同re.match;
import rea=re.split('.', 'leon1.leon2.leon3.')print(a)['leon1', 'leon2', 'leon3', '']



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









