



 本文介绍了解决Python爬虫获取HTML时出现乱码的方法。通过查看网页源代码确定字符集,并使用正确的字符集进行转码,使爬取的内容正常显示。
本文介绍了解决Python爬虫获取HTML时出现乱码的方法。通过查看网页源代码确定字符集,并使用正确的字符集进行转码,使爬取的内容正常显示。
很多同学会遇到Python爬虫得到的HTML乱码的问题。其实这个问题搞清楚逻辑,就能够解决。
- 一般爬虫
import 点开html中的链接,看到乱码了。

2. 问题处理
①首先,在google中输入电影“无名之辈”的链接(https://www.ygdy8.com//html/gndy/dyzz/20190104/58016.html),然后Ctrl+U,查看源代码页。
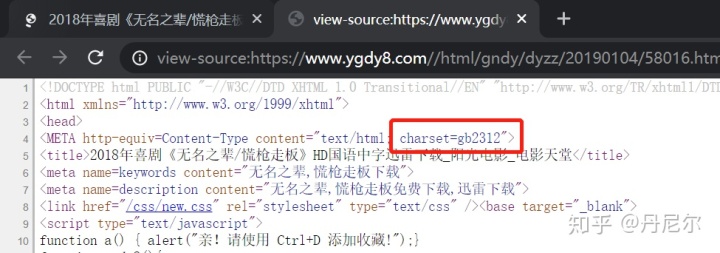
②在源代码第4行,找到charset=gb2312,说明这个网页的字体是gb2312的格式。python默认字体是utf-8。转码!
③转码
import 加上转码一行,那么html就正常了。

3.结语
以上就是乱码问题的处理。希望对大家有益~

















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









