




 本文介绍了一种处理TXT文件数据的方法,通过解析文件内容,提取并处理特定格式的数据条目,实现对时间变化的量化分析。文章详细描述了如何读取TXT文件,解析数据,处理时间进位问题,并计算数据变化的时间间隔。
本文介绍了一种处理TXT文件数据的方法,通过解析文件内容,提取并处理特定格式的数据条目,实现对时间变化的量化分析。文章详细描述了如何读取TXT文件,解析数据,处理时间进位问题,并计算数据变化的时间间隔。
接着上一篇excel文件数据处理。本篇文章是处理txt文件
import os
def read_txt(name):
start = 0
end = 0
an_niu = 0
with open(name) as file:
content = file.read()
c_list = content.split('\n')
for x in c_list:
if not x:
continue
split_one = x.split(",")
t,h,q = handle_data(split_one)
if start == 0:
if t:
if h<1:
h = 60+h
start = h
print("start:",start)
if end == 0:
if int(split_one[-1])==0:
an_niu = 1
pass
if int(split_one[-1])==1 and start!=0 and an_niu == 1 and q<-100:
if h<1:
h = 60+h
end = h
print("end",end)
an_niu = 0
print("jieguo:",(end-start)*1000+0.5)
print("*"*10)
return (end-start)*1000+0.5
def handle_data(split_one):
qian0 ,qian1 = split_one[0].split(" ")
i = 0
if int(qian1)>=5 or int(qian1)<=-5:
q = qian0.split(":")[-1]
i = float(q.split("]")[0])
return 1,i,int(qian1)
else:
return 0,i,int(qian1)
def url_together(name):
list_names = os.listdir(name)
i = 0
for list_n in list_names:
if not "." in list_n:
url_together(name+"/"+list_n)
else:
i += 1
# 处理txt文件
# print(i)
if i>3:
handle_txt(name)
def handle_txt(url_name):
name_list = []
names = os.listdir(url_name)
for txt_name in names:
if ".txt" in txt_name :
name_list.append(txt_name)
handle_vlues = []
for name in name_list:
v = read_txt(url_name+"/"+name)
handle_vlues.append(int(v))
print("="*30)
print(url_name)
handle_vlues.sort()
# print("handle_vlues:",handle_vlues)
print(max(handle_vlues))
print(min(handle_vlues))
handle_vlues = handle_vlues[1:-1]
print(sum(handle_vlues)/len(handle_vlues))
print("="*30)
if __name__ == '__main__':
url_together("1次")
处理结果:算出变化时间。
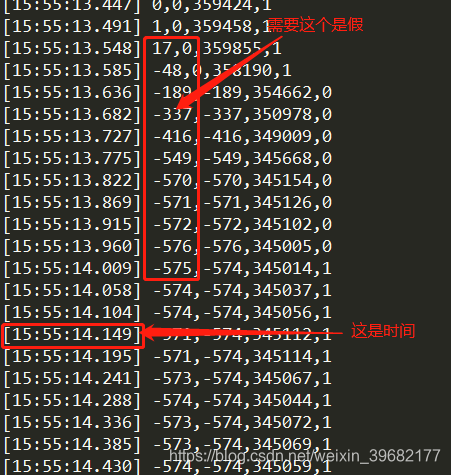
遇到问题。时间是60进位。在读取是0了。所以我认为0是60所以解决一个问题。但是如果时间比较久。一个是0。另外一个进位到2。处理数据变很大。所以后期再更改。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









