






基于深度学习的图像识别的软件解决方案
软件架构:MPI+Caffe
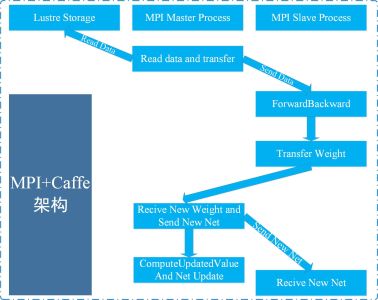
深度卷积神经网络(CNN)算法是深度学习领域普遍采用的神经网络构建模型,Caffe是目前最快的CNN架构。浪潮的集群版Caffe计算框架正是切中当下深度学习的迫切需求,它采用MPI技术对Caffe版本进行数据并行优化,该框架基于伯克利caffe架构进行开发,完全保留原始caffe架构的特性。即:纯粹的C++/CUDA架构,支持命令行、Python和MATLAB接口等多种编程方式,具备上手快、速度快、模块化、开放性等众多特性,为用户提供了最佳的应用体验。另外,鉴于众多用户基于CPU进行深度学习应用研究的现实,浪潮还可提供C-G算法迁移增值服务,针对用户目前的深度学习算法,做硬件适配性算法迁移和升级优化,帮助用户做到算法的更快,更好。硬件架构:IB网络+GPU集群+Lustre并行存储
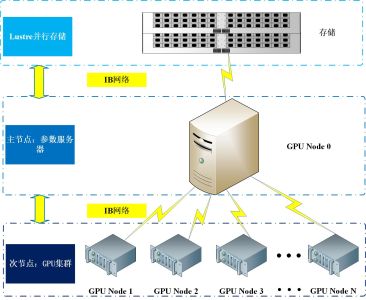
以浪潮NF5568M4为代表的GPU服务器的产品,在同CPU计算力下, GPU配置数量比业内平均水平高出50%,且最高支持的单卡计算能力比业内主流水准高50%浪潮根据深度学习多并行,高I/O需求,设计出Lustre分布式并行存储系统和56Gb/s InfiniBand网络架构的横向扩展的GPU主从硬件集群架构,配合浪潮inspur-caffe架构实现了跨多节点的数据并行计算,该架构兼顾计算密集型,IO密集型等计算模型硬件需求特点,同时支持Pascal GPU,最大可实现超100个GPU卡并行计算。
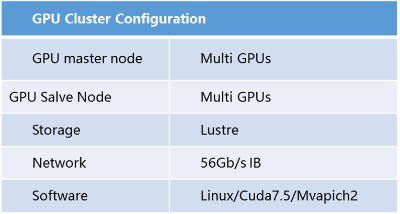
该方案利用超级计算机设计思路,突破多机多卡并行计算I/O速率不足的技术瓶颈,在保证系统稳定性前提下,使高性能GPU计算能力得到充分发挥,帮助用户大幅提升线下模型训练速度,降低每个计算核心的TCO。配合浪潮MPI-Caffe架构的深度学习算法,用户在图像识别类应用上,实现高精度图像识别模型的快速训练,加速后期业务产品化进程。
实测显示,对1.3M张图片进行9层模型训练时,4颗E5-2699V3处理器的2台服务器需3天(72小时)方完成训练,使用浪潮4卡最新GPU软硬一体化解决方案只需不到9.5个小时就可以完成全部工作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









