





 本文介绍了grep、awk和sed这三个强大的文本处理工具的基本用法和高级技巧,包括正则表达式、模式匹配、数学运算及字符串操作等功能。
本文介绍了grep、awk和sed这三个强大的文本处理工具的基本用法和高级技巧,包括正则表达式、模式匹配、数学运算及字符串操作等功能。
grep
grep(global regular expression print)
简而言之, grep 会用一个搜索字符串在输入的文件中搜索,并打印出匹配的行. 从文件中的第一行开始, grep 将该行复制到缓存中, 并将其与搜索字符串匹配, 如果匹配通过, 就把该行打印到屏幕上. grep 会重复这个过程直到最后一行. 注意在这个过程中, grep 不会存储以及修改任何数据, 也不会仅搜索某行的一部分.
示例文本
将以下文本保存为 a_file
boot
book
booze
machine
boots
bungie
bark
aardvark
broken$tuff
robots简单的例子
在 grep 中最简单的例子:
grep "boo" a_file在这个例子中,grep会遍历 a_file 文件的每一行,并输出包含单词 boo 的行
boot
book
booze
boots常用选项
-n
如果想要定位该行在文件中的位置,可以使用 -n 参数来显示行数
grep -n "boo" a_file返回结果
1:boot
2:book
3:booze
5:boots-v
另一个有用的选项是 -v ,它会输出所有不匹配的结果
grep -vn "boo" a_file返回结果
4:machine
6:bungie
7:bark
8:aaradvark
9:robots-c
-c 参数会输出匹配的行数
grep -c "boo" a_file输出
4-l
-l 参数会输出匹配到搜索字符串的文件名,在多个文件中搜索同一个字符串时有用
grep -l "boo" *输出
a_file-i
-i 参数会搜索大小写不敏感(insensitive)的字符串
grep -i "BOO" a_file-x
-x 参数会查找字符串 exact 的匹配,即全字匹配
grep -x "boo" a_file-A
-A 参数会输出额外(Additional)的几行,如:
grep -A2 "mach" a_file输出
machine
boots
bungie正则表达式
在使用正则表达式的场景下,推荐使用egrep(grep -E)
egrep, fgrep 和 grep 不同之处
首先:
egrep 等价 grep -E
fgrep 等价 grep -F
现有文本:
grep searches for any string in list of strings or flie.
It is very fast.
(f|g)ile要搜索其中的第三行 (f|g)ile
grep '(f|g)ile' check_file
grep '(f|g)ile' check_file输出
(f|g)ile
grep searches for any string in list of strings or file.在 grep 中,()|+?等字符会失去它们在正则表达式中的意义,被当成普通字符串来看待。若想它们表现为正则中的效果,则需要使用 进行转义。
而在 egrep 中,与 grep 相反,搜索字符串则与其它语言场景下的正则表达式表现一致
egrep '(f|g)ile' check_file
egrep '(f|g)ile' check_file输出
grep searches for any string in list of strings or file
(f|g)ile在 fgrep 中不会识别任何正则表达式字符或用法,比 grep 更快。
fgrep '(f|g)ile' check_file
fgrep '(f|g)ile' check_file # 未能找到匹配,无输出输出
(f|g)ileawk
由 aho, weinberger & kernighan 编写,一个文本模式扫描(text pattern scanning)与处理语言。查看完整使用方法,你总是可以使用 man awk
使用基础
与 grep 类似,awk 会对输入文件的每一行进行操作。首先是一个可选的 begin{} 代码块(section),会在操作文件内容前执行,随后主体(main) {} 代码块对文件的每一行操作,最后可选的 end{} 代码块执行操作。
begin { ….初始化的 awk 命令 …}
{ …. 对于每一行的 awk 命令…}
end { …. 结束后的 awk 命令 …}对于输入文件的每一行,它会先查看是否有任何模式匹配的指令。如果存在模式匹配的指令,它就会仅处理匹配的行,否则会处理所有行。这些模式匹配指令可以包括正则表达式。awk 命令可以执行一些非常复杂的数学运算和字符串操作,并且 awk 还支持关联数组。
awk 将每一行看做由多个字段(field)组成的整体,每一个字段之间被字段分隔符(field sepatator)分隔开。默认情况下,分隔符就是一个或多个空格。
this is a line of text上面的文字包含 6 个字段。在 awk 中,第一个字段(或者说单词)被成为 $1,第二个 $2,以此类推。整行则被称为 $0。字段分隔符由 awk 的内置变量 FS (field sepatator)设置,所以如果你设置 FS=":",那么它就会把整行使用 : 分隔,这在一些场景中很有用,比如 /etc/passwd 文件中。另内部变量还有 NR (number of recorded)也就是文件的行数,和 NF (number of fields) 字段在该行的数字。
awk 可以在任何文件上操作,包括标准输入,在这种情况下它通常和管道符 | 一起使用,比如在和 grep 命令联合使用时。举例来说,如果我在一个目录中列出所有文件:
[mijp1@monty RandomNumbers]$ ls -l
total 2648
-rw------- 1 mijp1 mijp1 12817 Oct 22 00:13 normal_rand.agr
-rw------- 1 mijp1 mijp1 6948 Oct 22 00:17 random_numbers.f90
-rw------- 1 mijp1 mijp1 470428 Oct 21 11:56 uniform_rand_231.agr
-rw------- 1 mijp1 mijp1 385482 Oct 21 11:54 uniform_rand_232.agr
-rw------- 1 mijp1 mijp1 289936 Oct 21 11:59 uniform_rand_period_1.agr
-rw------- 1 mijp1 mijp1 255510 Oct 21 12:07 uniform_rand_period_2.agr
-rw------- 1 mijp1 mijp1 376196 Oct 21 12:07 uniform_rand_period_3.agr
-rw------- 1 mijp1 mijp1 494666 Oct 21 12:09 uniform_rand_period_4.agr
-rw------- 1 mijp1 mijp1 376286 Oct 21 12:05 uniform_rand_period.agr我们能看到文件大小在每行的第五列。所以如果我想知道该目录下所有文件的大小,可以这样做:
[mijp1@monty RandomNumbers]$ ls -l | awk 'BEGIN {sum=0} {sum=sum+$5} END
{print sum}'
2668269注意 print sum 会打印变量 sum 的值,所以如果 sum=2 那么 print sum 就会输出 2 ,然而 print $sum 就会输出 1 ,因为第二列的字段的值为 1。
所以在 awk 命令中,要计算一组数的平均值和标准差时,在主体(main) {} 中累加 sum_x sum_x2,然后在 END {} 中使用标准公式计算出最终的平均值和标准差。
awk 提供 loop 循环( while 和 for )和分支判断(if)。所以如果你想调整为每三行操作一次,你可以这样做:
[mijp1@monty RandomNumbers]$ ls -l | awk '{for (i=1;i<3;i++) {getline};print NR,$0}'
3 -rw------- 1 mijp1 mijp1 6948 Oct 22 00:17 random_numbers.f90
6 -rw------- 1 mijp1 mijp1 289936 Oct 21 11:59 uniform_rand_period_1.agr
9 -rw------- 1 mijp1 mijp1 494666 Oct 21 12:09 uniform_rand_period_4.agr
10 -rw------- 1 mijp1 mijp1 376286 Oct 21 12:05 uniform_rand_period.agr其中, for 循环里使用了 getline 来在文件的行里移动(每执行一次getline,当前行往下一行)。其中,因为文件行数是10,不能被3整除,所以最后的 print $0 打印出的是第10行的内容。同时我们使用了内部变量 NR 来打印出行号。
模式匹配
awk 是一门面向行操作的语言。先是模式(pattern)再是行为(action),模式和行为可以缺失任意一个,如果缺失模式,则行为会作用于每一行。如果缺失行为,则会打印出每一行。
流程控制语句
if (condition) statement [ else statement ]
while (condition) statement
do statement while (condition)
for (expr1; expr2; expr3) statement
for (var in array) statement
break
continue
exit [ expression ]输入输出语句

注意:其中 printf 使用类似C语言(C-like)的语法
数学计算函数
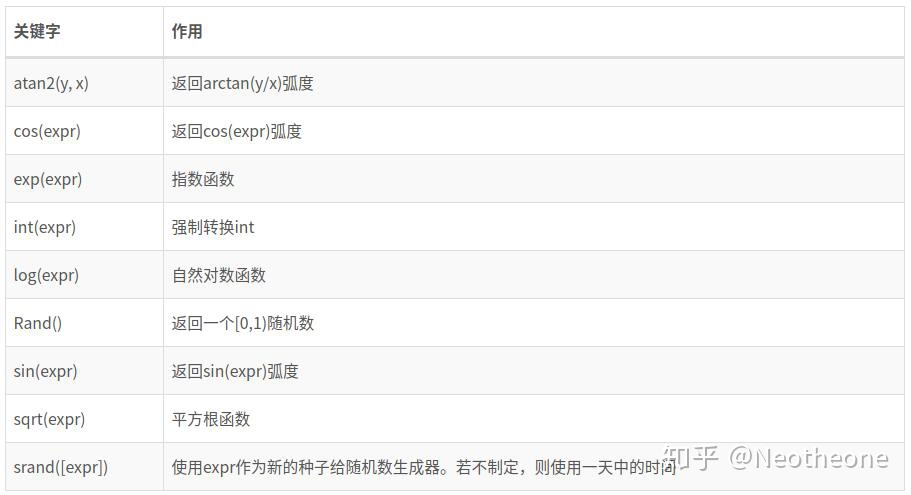
字符串函数

命令行使用
你可以在命令行中通过-v参数向 awk 程序传递变量:
awk -v skip=3 '{for (i=1;i<skip;i++) {getline}; print $0}' a_file你也可以将 awk 程序保存成一个特殊脚本文件:
#!/usr/bin/awk -f
# 只每三行打印一次
BEGIN {skip=3}
{for (i=1;i<skip;i++)
{getline};
print $0}sed
sed(stream editor)对输入流(文件或来自管道的输入)执行基本的文本转换,非常高效。但是,使它与其他类型的编辑器区别开来的是sed在管道中过滤文本的能力。
基础
sed 可以在命令行或shell脚本中非交互式(non-interactively)的使用。也许它最有用的一个特性就是对字符串做 '搜索并替换' 。
你可以将你的 sed 命令使用 -e 选项嵌入到命令行中,或者使用一个单独的文件(比如sed.in)和选项 -f sed.in。在 sed 指令内容非常复杂并且包含很多正则表达式的时候,通常使用后者。例如:
sed -e 's/input/output/' my_file这会将my_file里的每一行第一个'input'替换为'output',并打印到标准输出。注意,sed 是面向行的,所以如果你希望改变每一个'input',需要使用贪婪(greedy)模式,像这样:
sed -e 's/input/output/g' my_file在/.../中的内容可以是字符串文本或者正则表达式。
注意,在默认情况下,输出会打印到标准输出(stdout)。你也许需要重定向到一个新文件,此时,使用重定向符号>或者-i选项:
sed -e 's/input/output/' my_file > new_file
sed -i -e 's/input/output/' my_file正则表达式
如果说你想搜索的指令中包含一些特殊字符,比如/(在文件名中)或者*等。那么你需要对他们进行转义(escape)。例如:
sed -e 's//bin//usr/local/bin/' my_script > new_script如果你想获取搜索到的字符串并作为输出结果的一部分,可以使用&符号来代替搜索到的字符串。比如你想把每行的第一个数字用括号括起来:
sed -e 's/[0-9]*/(&)/' my_file你还可以在正则表达式中使用位置指令,甚至可以将部分匹配保存在模式缓冲区中,以便在其他地方重用。
其他 sed 命令
通常的形式:
sed -e '/pattern/ command' my_file其中pattern是正则表达式,command可以是
s搜索并替换(search & replace)p打印(print)d删除(delete)i插入(isert)a追加(append)- 等等
注意,默认操作是打印所有的行,无论是否匹配。如果你想禁止这种行为,你可以使用-n选项然后再用p命令打印出来。比如你想打印当前目录下的目录文件:
ls -l | sed -n -e '/^d/ p'因为每一个目录文件都是以'd'开头的,所以这只会打印出那些以'd'开头的行
同样的,如果你想删除那些以#开头的注释行,可以这样:
sed -e '/^#/ d' my_file当然你也可以通过不同的用法达到相同的效果
你也可以使用域(range)的形式
sed -e '1,100 command' my_file在第1行到第100行都执行command命令。你也可以使用特殊的$符号代表文件结尾(end of file)。所以如果你想删除一个文件里除了前10行以外的行,你可以:
sed -e '11,$ d' my_file你也可以使用一个模式-域的形式,这种情况下前一个正则表达式定义了域的开始,后一个定义结束。举例来说,你想打印a_file文件中的从boot到machine的行,你可以这样做:
sed -n -e '/boot$/,/mach/p' a_file参考
grep, awk and sed – Matt Probert, Uni of York
What’s Difference Between Grep, Egrep and Fgrep in Linux? – Gunjit Khera

















 5417
5417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









