






题目和文章内容有点不太符合,这里存储引擎是指单机存储引擎。对于分布式存储系统来说,存储引擎是必须的。存储引擎决定了数据在内存和磁盘中具体如何存储的,如何方便地拿出来的问题。可以说直接决定了存储系统的性能和可以干什么,不可以干什么的问题;本文参考《数据密集型应用系统的设计》 和《大规模分布式存储系统原理解析和架构实战》。
存储系统的功能做机制的简化就是存储和查询,如果从一般功能出发就是基础的增删改查。从最简单的开始想起,最简单的存储系统,无非就是把数据直接写入到文件中(可以按照 K,V 一行方式存储),需要的时候就顺序读取文件,找到可以需要查询的行。这在少量的数据的时候并没有问题,但是如果是大批量数据,几百 MB 或者几 GB,甚至 TB,PB 的时候,顺序读取大量文件那速度慢的吓人。
一 哈希存储引擎
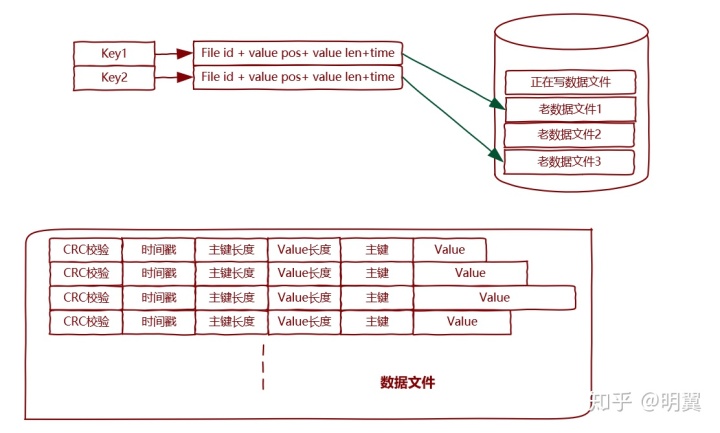
顺序读取文件做遍历查找,速度很慢,我们第一想到的思路是建索引,索引最常用的就是哈希表了,如果我们对文件中的数据建个索引,Key 保存着我们下次要查询的值,Value 对应这哪个文件的哪个位置。在内存中保存这个索引,下次查询的时候,我们通过哈希表快速定位到文件和位置,就可以迅速取到需要的值了。Bitcask 折中日志型小型文件系统就采用这种存储方法,它可以提供高性能的读写,只需要经过一次磁盘的寻址就可以获取到所需要的数据。
作为日志型的存储系统,Bitcask 的删除和修改是通过顺序记录到文件中,并不是对原来的文件进行修改,这减少了随机磁盘的读写操作。数据写入到文件中,如果一直写,显然文件越来越大,不便于操作,所以限制文件的大小,当大小达到一定规模后,重新写入一个文件。 对于更新和删除的数据,如果不处理,会产生大量的垃圾数据,占用了空间,所以后台会定时进行文件合并,合并的时候删除标记删除的具体数据。
1.1 崩溃恢复
哈希存储引擎的数据分为两份,一份是内存中的数据,一个是磁盘的文件,系统崩溃后,磁盘中的哈希表就没有了。如果恢复的时候通过读取文件的方式也是可以重建的,但是如果文件很多,很大,恢复的时间就会很长,Bitcask 对每个段的文件的哈希表快照存储在文件中,下次恢复的时候可以快速恢复。
1.2 并发控制
Bitcask 只有一个写入线程追加,可以采用多个读取的线程并发读取,性能上还是很不错。
1.3 哈希存储引擎的缺点
哈希存储引擎 因为采用哈希表,查找的性能不错,但是同样因为采用哈希存储引擎,会导致范围查询,只能通过遍历的方式去查询数据,范围查询慢。
刚才结构也说了,索引必须可以保存在内存中,才可以性能够好,但是如果数据量超大,内存中无法保存,保存到磁盘中,会产生大量的随机访问。另外哈希还存在着哈希冲突的问题。
二 LSM 树存储引擎
刚才的哈希存储引擎的两个缺点,一是范围查询性能很差,我们要做范围查询,最好数据是有序的,有序的就可以不用遍历全部数据去做范围查询了。所以我们内存的数据不就不适合哈希索引,我们可以考虑改造成一个支持排序的数据结构。 另外刚才的哈希存储引擎,数据是按照顺序写入到数据文件中的,如果同一个 key 的多次更新,只保留最后一个数据的时候,是不是挺麻烦。
我们可以将文件中和内存中的数据都排序,这种格式称为排序字符串,在 Level DB 中叫 SSTable。文件中的 K-V 结构排序后,好处是我们在做多文件合并的时候,可以按照多路归并的算法,快速排序,用多个指针依次比较和后移就可以办到。多个文件含有同一个值的时候,我们可以保留最新的字段值。
内存中的数据排序后,我们不一定对所有的数据的 key 都保存,可以只保存部分,根据 key 的排序特性,也可以很容易找到要找的值。 由于要对内存中的数据排队,而且数据要经常插入和删除,所以红黑树和 AVL 树是比较适合这种场合。对于存储在磁盘上的文件,也是有序的,用普通的 AVL 树或红黑树,保存到磁盘上后,数据多的话,树的层次会很高,这样通过多个指针需要多次随机读取,所以一般采用专门为大数据存储磁盘而设计的 B+树,B+树的每个节点的分叉很多,一个节点可能有上千个分支。这样很少的层次就可以支持大量的数据了。
2.2 LSM 存储引擎如何写入和查询
这种引擎如何写入数据:
- 写入数据的时候将数据写入到内存的红黑树或者其他的高校增删且支持排序的数据结构,比如调表等。
- 这种内存中树被称为内存表,当然内存表也不可能无限制增加,当达到一定的阀值后,就会将整体作为 SSTable 写入到磁盘文件中,直接采用顺序写入的方式写入到磁盘中。新来的数据写入新的内存表。
如何读取数据:
- 先在内存表中查找,如果没找到 就在磁盘的最新段文件查找,如果没找到就在次新的文件查找,直到找完所有的段文件或找到了返回。由于数据是按照时间顺序写的段文件,所以先找到的数据是最新的,也是我们需要找的数据。
- 如果磁盘文件越来越多,那么查找性能肯定很差,所以和哈希引擎一样,需要后台线程定期做段合并,减少文件个数,且合并相同的 key 和删除已经删除的 key。
- 需要注意一点的是,如果删除一条数据,在内存表里面虽然没有这个数据,也要记录下来,标记为删除,这样查询的时候,在内存表中查询到删除后就可以直接返回;如果不做删除标记,那么在 SSTable 文件中也许会查询到这个数据,返回就是错误的数据了。
2.3 Level DB 存储引擎举例
这个存储引擎就是 LSM 存储引擎的本质了,Level DB 就是采用这个存储引擎的。
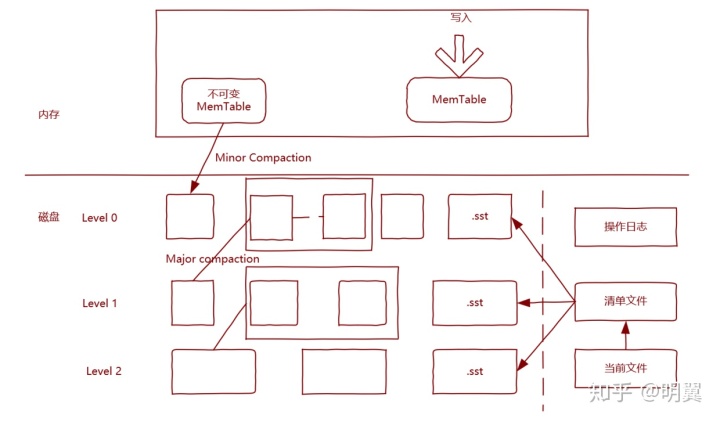
类似的存储引擎还用于 HBASE,以前还记得学习 HBase 的时候 minor compaction(少量的 HFile 合适小文件合并,为提升性能同时减少 IO 压力)和 major compaction(一个 Node 节点的所有文件合并),还比较迷茫。 从上图的 Level DB 存储引擎图可以看出,数据处理过程:
- 数据先写入 MemTable,当内存中的数据到达一定规模之后,就转成不可写的 MemTable,生成新的 Memtable 继续写入。
- 后台有线程将不可变的 Memtable 写入到磁盘中即生成一个个 SSTable 的段文件,这样的好处是在转存的时候也不影响继续的读取和写入,完全不用加锁,这个写入过程叫 Minor compaction。
- 后台线程在做多个 SSTable 段文件合并的时候,如果两个段文件大小相差很大,显然性能很差,所以最好是分层设计。 LevelDB 最新的是 Level 0 层,Level 0 层的文件达到一定规模后,会挑选几个 Level 0 的文件合并后形成 Level 1 层的文件,逐步类推。
- 由于 LSM 树写的是内存表,那么如果机器挂了,会有数据的丢失,为此设计了操作日志,再写完操作日志后再写内存表,这样通过一次顺序写磁盘和写内存来完成数据的写入操作。
说明清单文件保存的是元数据信息,记录了每个 SSTable 文件所属的 Level,文件中的 key 的最大值和最小值。同时由于 SSTable 文件经常变动的,所以增加个当前文件指向当前的清单文件这样操作起来就不用加锁了。
特点: 通过上述描述可以看出,LSM(Log-structured Merge Tree)存储引擎是基于日志特性(即数据只追加不修改) 的合并和压缩排序树的存储引擎;写入之后只需要写入内存和一次操作日志的顺序写,所以写入性能比较好;如果系统进程需要查询最近的数据,那么由于最新的数据在内存中,所以性能也比较好;但是一般情况下查询的需要查内存表和多个 SSTable,查询性能不太好,特别是数据不存在的情况,为此可以在 SSTable 中添加布隆过滤器,可以快速过滤掉不存在的情况。
三 B-Tree
相对于以上两种引擎,B 树存储引擎应用的最广泛,在关系型数据库中运用的很多。B 树存储引擎不光支持随机查询,还很好地支持范围查询。像 SSTable 一样,B 树引擎同样保持了对 key 的排序。在文件存储上,还是有很大的差异。LSM 存储引擎的段文件大小不一,是顺序写入到磁盘的。B-Tree 不像 LSM 树那样有内存表和 SSTable,而只有一个 B 树,当然一些顶层块常在内存中。
B 树是按照块存储数据库的数据的,它一般是一个多叉树,比如 InnoDB 引擎采用 B+树存储,每个节点大概有 1200 个子分支。B 树分为叶子节点和非叶子节点,叶子节点存储的是 key 和具体的数据,而非叶子节点存的是 key 和磁盘地址。
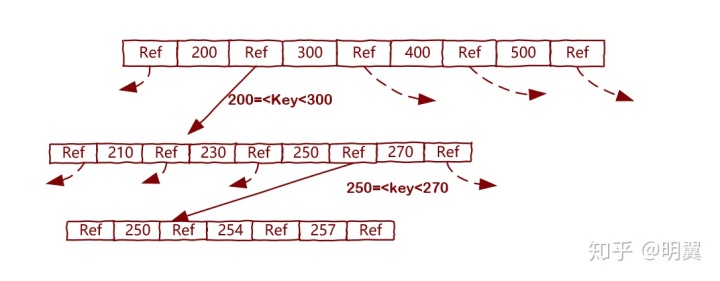
以 B+树为例说明查询和插入的基本流程
3.1 查询
读取一个节点,如果对应的节点所在的数据页不在内存中,需要按照下面的过程从磁盘中读取,然后缓存在内存中。
- 查询的时候,我们从根页开始,通过 key 的范围找到下层子页,继续查找,直到找到叶子节点所在的页。
- 叶子节点保存 key 和对应的值,在数据库中叶子节点保存完整的数据行。
- 在叶子节点所在的块之后,可以通过二分查找的方式快速查询到记录值或查询结果不存在。
3.2 插入
插入和更新按照 InnoDB 引擎为例的话,还是比较复杂。
- 查询插入的主键的 key 所属的页是不是在内存中,是的话直接在内存中修改,记录 redo log 防止挂了。
- 如果所属的页没有在内存中,由于使用了主键,所以必须加载数据页(change buffer 失效,写其他非唯一索引的可用)到内存,再进行插入;如果修改数据,没有使用唯一索引,可以在 change buffer 中直接记录这次更新。
- 下次读取数据页面的数据的时候,在内存中直接返回,不在内存中则加载在内存中,如果 change buffer 里面有修改的记录,则需要应用 change buffer 里面的动作到这个加载的数据页中。
- 插入的时候,如数据页已经满了,则需要分裂数据页,小于中间值的位于左边,大于的位于右边,中间值作为索引节点放入到上层。
实际中还涉及到 bin log 日志。可以看到实际工程中,B-树引擎还是通过 redo log 这种 WAL 日志,用顺序磁盘读写替换了随机读写;change buffer 减少了随机读数据的过程,可以合并多条修改记录,一次性写,增加了性能。
四 总结
B 树和 LSM 树相比有以下特点:B-树引擎特点:
- 写入 WAL 日志;
- 写入树本身的页,即使只是修改了几个字节,也要将整个数据页要重写;
LMS 树引擎特点:
- LSM 树由于需要合并,SSTable 也需要写入多次,但是由于是顺序写而且写入的 SSTable 更紧凑,因此写入性能更好。
- LSM 树的数据结构更紧凑,而 B 树为降低分页的概率,所以预留部分空闲节点,从而造成一些碎片,无法充分利用磁盘空间。
- LSM 树压缩合并过程中会影响到读取性能;B 树响应性更加确定,每个 key 有唯一的位置;而 LSM 树不同的段中可能有一个 key 的不同副本。 想支持事务的话,B 树是更好的选择。

















 1230
1230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









