





 本文围绕后端数据重复插入问题展开。起因是微信小程序重复请求致数据库出现重复数据,这会造成数据冗余和服务问题。提出单库单表用唯一索引和幂等处理,分库分表用分布式锁 Redis 解决的方案,以防止数据重复插入。
本文围绕后端数据重复插入问题展开。起因是微信小程序重复请求致数据库出现重复数据,这会造成数据冗余和服务问题。提出单库单表用唯一索引和幂等处理,分库分表用分布式锁 Redis 解决的方案,以防止数据重复插入。
本文主要从三个方面讲解如何防止数据重复插入:
- 为啥要解决数据重复插入?
- 解决方案实战
- 可落地小总结
一、为啥要解决数据重复插入?
问题起源,微信小程序抽风 wx.request() 重复请求服务器提交数据。后端服务也很简单,伪代码如下:
class SignLogService { public void saveSignLog(SignLogDO log) { // 简单插入做记录 SignLogDAO.insert(log); }}发现数据库会存在重复数据行,提交时间一模一样。但业务需求是不能有多余的 log 出现,这明显是个问题。
问题是,重复请求导致的数据重复插入。这问题造成的后果很明显:
- 数据冗余,可能不单单多一条
- 有些业务需求不能有多余数据,造成服务问题
问题如图所示:
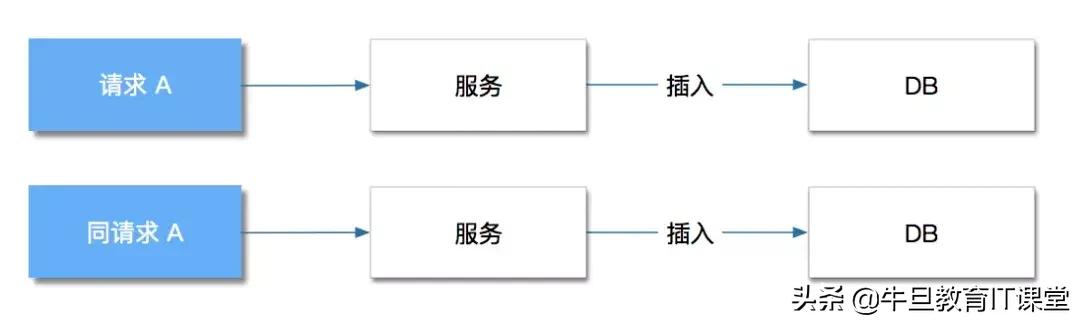
解决方式:如何将 同请求 A,不执行插入,而是读取前一个请求插入的数据并返回。解决后流程应该如下:
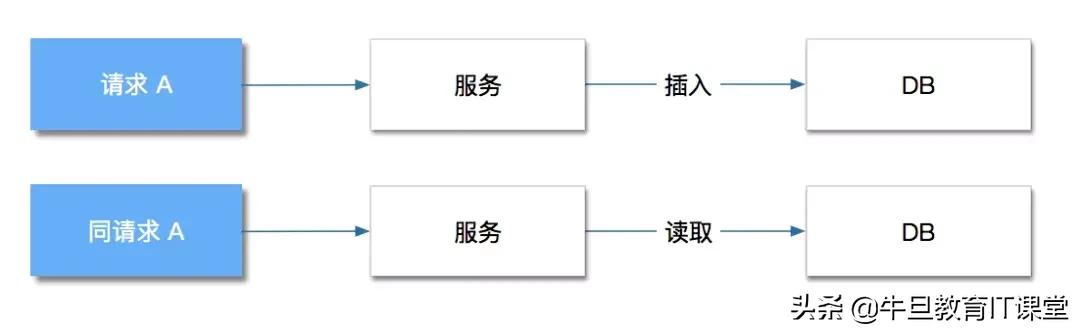
二、解决方案实战
1.单库单表解决方案
- 唯一索引 + 唯一字段
- 幂等
上面说的那种业务场景:signlog 表会有 userid、signid、signtime 等。那么每次签到,每个人每天只有一条签到记录。
数据库层采取唯一索引的形式,保证数据记录唯一性。即 UNIQUE 约束,UNIQUE 约束唯一标识数据库表中的每条记录。另外,userid,signid,sign_time 三个组合适唯一字段。创表的伪代码如下:
CREATE TABLE sign_log(id int NOT NULL,user_id int NOT NULL,sign_id int,sign_time int,CONSTRAINT unique_sign_log UNIQUE (user_id,sign_id,sign_time))重点是 CONSTRAINT unique_sign_log UNIQUE(user_id,sign_id,sign_time)。有个小问题,数据量大的时候,每条记录都会有对应的唯一索引,比较耗资源。那么这样就行了吗?
答案是不行,服务不够健壮。第一个请求插入成功,第二个请求直接报错,Java 服务会抛出 DuplicateKeyException 。
简单的幂等写法操作即可,伪代码如下:
class SignLogService { public SingLogDO saveSignLog(SignLogDO log) { // 幂等处理 SignLogDO insertLog = null; try { insertLog = signLogDAO.insert(log); } catch (DuplicateKeyException e) { insertLog = selectByUniqueKeys(userId,signId,signTime); } return insertLog; }}的确,流量不是很大,也不算很高并发。重复写问题,这样处理即可。那大流量、高并发场景咋搞
2.分库分表解决方案
流量大了后,单库单表会演变成分库分表。那么基于单表的唯一索引形式,在碰到分表就无法保证呢,插入的地方可能是两个分表 A1 和 A2。
解决思路:将数据的唯一性条件放到其他存储,并进行锁控制
还是上面的例子,每天,每次签到,每个人只有一条签到记录。那么使用分布式锁 Redis 的解决方案。大致伪代码如下:
a.加锁
// 加锁jedis.set(lockKey, requestId, "NX
















 171万+
171万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









