



 本文深入探讨了Java开源任务调度库Quartz的特性,包括其强大的调度功能、灵活的应用方式和分布式能力。文章介绍了如何在项目中引入Quartz,详细讲解了XML配置、自定义JobFactory、以及一个具体Job类`TestJob`的实现。重点讨论了并发控制、持久化存储和数据库表的创建。最后,文章提供了Quartz作业的添加、暂停、恢复和删除等操作的方法,帮助读者掌握Quartz的实战应用。
本文深入探讨了Java开源任务调度库Quartz的特性,包括其强大的调度功能、灵活的应用方式和分布式能力。文章介绍了如何在项目中引入Quartz,详细讲解了XML配置、自定义JobFactory、以及一个具体Job类`TestJob`的实现。重点讨论了并发控制、持久化存储和数据库表的创建。最后,文章提供了Quartz作业的添加、暂停、恢复和删除等操作的方法,帮助读者掌握Quartz的实战应用。
Quartz是OpenSymphony开源组织在任务调度领域的一个开源项目,完全基于Java实现。Quartz具备以下特点:
1.强大的调度功能,例如支持丰富多样的调度方法,可以满足各种常规及特殊需求;
2.灵活的应用方式,例如支持任务和调度的多种组合方式,支持调度数据的多种存储方式;
3.分布式和集群能力
Quartz由于功能强大,又能够很轻易的就与spring集成在一起,所以实际开发中经常会用到。
一、引入Quartz包
org.quartz-scheduler
quartz
2.2.3
org.quartz-scheduler
quartz-jobs
2.2.3
二、详细配置
2.1 xml配置
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
使用quartz需要配置job、trigger、scheduler,其中:
job:任务的执行类,需要在xml中指明名称、组别和类
trigger:任务的触发器,需要指明名称、组别以及关联的job。一个触发器只能对应一个job;触发器有两种,分别为CronTriggerFactoryBean和SimpleTriggerFactoryBean,前者支持cron表达式,后者只支持一些简单的配置。
scheduler:调度器,需要将trigger配置在scheduler的triggers中,可以配置多个。这里自定义实现了jobFactory,可以在job中自动注入spring bean;applicationContextSchedulerContextKey属性用于在job中获取spring 的上下文。
2.2 代码清单
2.2.1 AutowiringSpringBeanJobFactory
packagecom.sawyer.job;importorg.quartz.spi.TriggerFiredBundle;importorg.springframework.beans.factory.config.AutowireCapableBeanFactory;importorg.springframework.context.ApplicationContext;importorg.springframework.context.ApplicationContextAware;importorg.springframework.scheduling.quartz.SpringBeanJobFactory;public class AutowiringSpringBeanJobFactory extends SpringBeanJobFactory implementsApplicationContextAware {private transientAutowireCapableBeanFactory beanFactory;public void setApplicationContext(finalApplicationContext context) {
beanFactory=context.getAutowireCapableBeanFactory();
}
@Overridepublic Object createJobInstance(final TriggerFiredBundle bundle) throwsException {final Object job = super.createJobInstance(bundle);
beanFactory.autowireBean(job);returnjob;
}
}
自定义实现了JobFactory,就可以在job中自动注入bean
2.2.2 AbstractJob
packagecom.sawyer.job;importorg.quartz.Job;importorg.quartz.JobExecutionContext;importorg.quartz.JobExecutionException;/*** 抽象类,job需要继承该类,通过这种方式可以做一些自定义处理*/
public abstract class AbstractJob implementsJob {
@Overridepublic final void execute(JobExecutionContext jobExecutionContext) throwsJobExecutionException {try{
safeExecute(jobExecutionContext);
}catch(Exception e) {
JobExecutionException e2= newJobExecutionException(e);if (!ignoreException()) {if(isRefireImmediatelyWhenException()) {//立即重新运行当前job
e2.setRefireImmediately(true);
}else{//立即停止与当前Job有关的所有触发器,当前job不会再运行
e2.setUnscheduleAllTriggers(true);
}
}throwe2;
}
}public abstract void safeExecute(JobExecutionContext context) throwsException;/*** 是否忽略job运行时产生的异常*/
public abstract booleanignoreException();/*** 发生异常时是否立即重新执行JOB或将JOB挂起.
*
*
*@return{@codetrue} Job运行产生异常时,立即重新执行JOB.
* {@codefalse} Job运行产生异常时,挂起JOB等候管理员处理.*/
public abstract booleanisRefireImmediatelyWhenException();
}
AbstractJob是一个抽象类,凡是job都应该继承该类,通过这种方式可以job做一些自定义处理。如图中代码所示,AbstractJob中有4个方法:
ignoreException:是否忽略异常,返回true时忽略异常,否则必须处理。
isRefireImmediatelyWhenException:当出现异常时,是否立即重新执行。返回true时,立即重新执行,否则将会挂起所有与该job有关的trigger,不再执行。
safeExecute:子类需要实现该方法,在方法中定义具体的实现逻辑。
execute:接口job的实现方法,job最终是在该方法中执行的。只有这个方法才是Job自带的,其他的都是自定义方法。
2.2.3 TestJob
packagecom.sawyer.job;importorg.quartz.DisallowConcurrentExecution;importorg.quartz.JobDataMap;importorg.quartz.JobExecutionContext;importorg.quartz.PersistJobDataAfterExecution;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.context.ApplicationContext;importorg.springframework.data.redis.core.RedisTemplate;importjava.util.Date;
@PersistJobDataAfterExecution
@DisallowConcurrentExecutionpublic class TestJob extendsAbstractJob {private static final String COUNT_KEY = "count";private static final String APPLICATION_CONTEXT_KEY = "applicationContext";
@AutowiredprivateRedisTemplate redisTemplate;
@Overridepublic void safeExecute(JobExecutionContext context) throwsException {//统计执行次数
JobDataMap jobDataMap =context.getJobDetail().getJobDataMap();int count = 0;if(jobDataMap.containsKey(COUNT_KEY)) {
count= (int) jobDataMap.get(COUNT_KEY);
}
count++;
jobDataMap.put(COUNT_KEY, count);//打印出redisTemplate,测试是否能自动注入
System.out.println("autowiring spring bean :" +redisTemplate);//获取spring上下文
ApplicationContext applicationContext =(ApplicationContext) context.getScheduler().getContext().get(APPLICATION_CONTEXT_KEY);
System.out.println("spring context :" +applicationContext);if (10 ==count) {int m = 1 / 0;
}
System.out.println("********current date :" + new Date() + " and the thread is :" + Thread.currentThread().getName() + " and the count is :" + count + " **********");
}
@Overridepublic booleanisRefireImmediatelyWhenException() {return false;
}
@Overridepublic booleanignoreException() {return false;
}
}
Quartz默认是支持并发的,即上一个任务未完成的时候就开始了下一个任务,并且每次都是生成一个新的job实例。图中例子由于需要共享count,统计次数,所在TestJob上面加了两个注解@PersistJobDataExecution和@DisallowConcurrentExecution,这是用于持久化JobData和禁用并发的。加了这两个注解就能够让testJob成为一个有状态的job,并且上一次任务执行完后,才开始下一次任务,这样一来就可以通过jobDataMap共享数据,反之,如果不加注解的话,job就是一个无状态的job,每次运行时都会产生一个新的job实例,数据无法共享。而禁用并发是为了防止并发产生数据紊乱的问题。
TestJob中isRefireImmediatelyWhenException和ignoreException都为false,那么当count等于10时,会抛出异常,系统就会将于当前job有关有的所有trigger挂起,不再执行job。
运行结果如下:
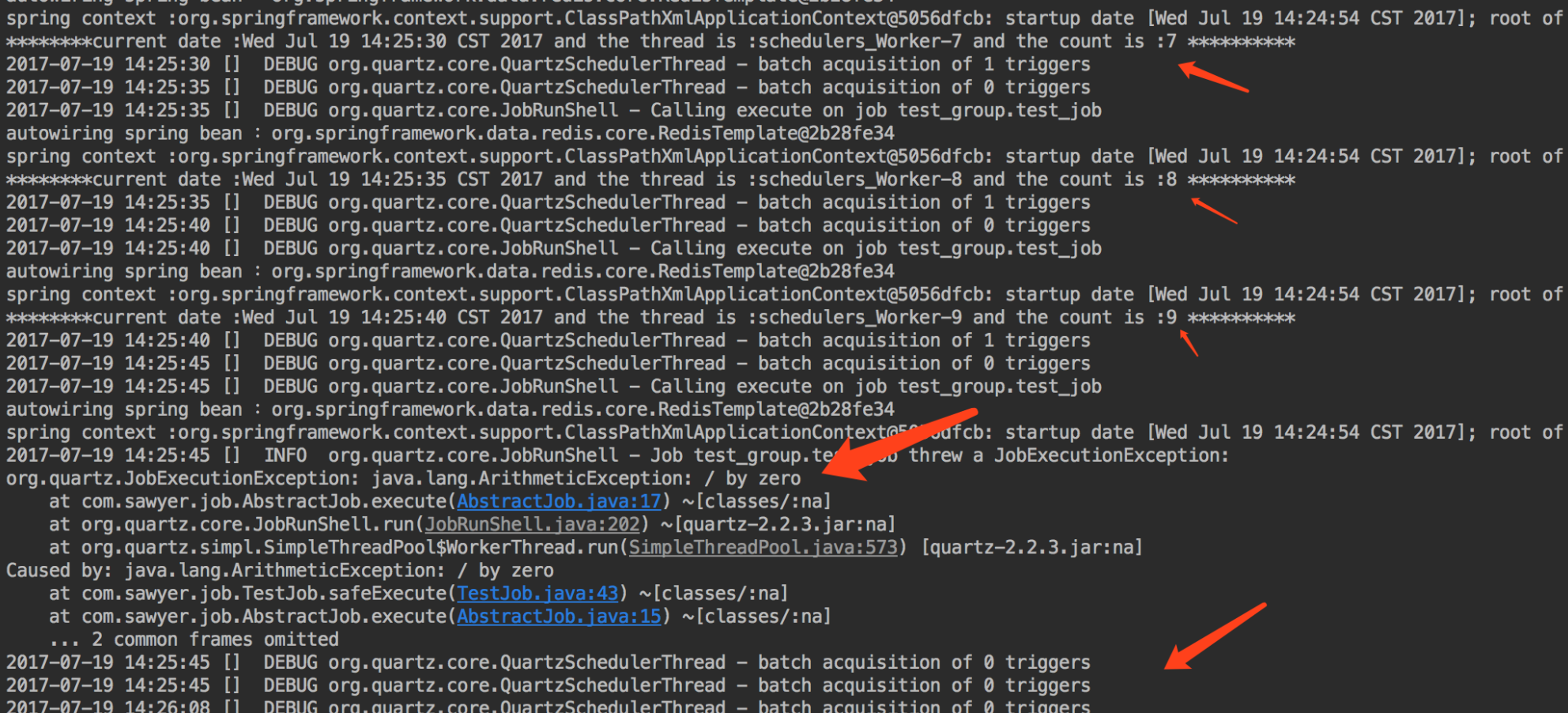
三、Quartz 存储与持久化
Quartz提供了两种作业存储类型,分别为RAMJobSore和JDBCJobStore。
RASMJobStore:将作业的调度信息存储到内存中,不需要配置外置数据库,配置简单,运行速度快;但是由于调度信息存储在内存中,当应用程序停止时,作业的调度信息将会丢失,此外一旦作业运行期间崩溃,将无法恢复事故现场,比如原定执行30次,执行到第15次是崩溃了,那么系统重启时,将会从0开始。
JDBCJobStore:将作业的调度信息存储到数据库中,该种方式支持集群,调度信息不会丢失,并且可以手动恢复意外停止的job;但是这种方式会较为复杂。
Quartz默认使用的就是RAMJobStore,下面开始介绍持久化配置。
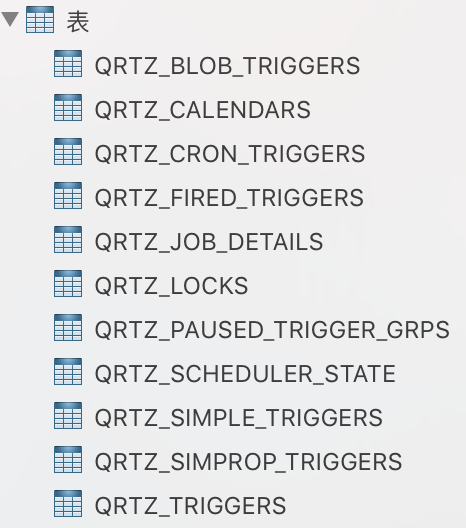
3.1 创建quartz数据表
3.1.1 下载源码包:http://www.quartz-scheduler.org/downloads/
3.1.2 在quartz-2.2.3/docs/dbTables目录下找到与数据库对应的sql文件,我使用的是mysql数据库,所以这里选择tables.mysql.sql文件,在数据库中执行。
3.1.3 表结构为:
3.2 引入 quartz.properties ,并根据业务需要进行配置。
#
# #{copyright}#
#
org.quartz.jobStore.isClustered= trueorg.quartz.jobStore.clusterCheckinInterval= 20000org.quartz.scheduler.instanceId=AUTO
org.quartz.scheduler.skipUpdateCheck= true# 集群配置
org.quartz.scheduler.instanceName=DefaultQuartzScheduler
org.quartz.scheduler.rmi.export= falseorg.quartz.scheduler.rmi.proxy= falseorg.quartz.scheduler.wrapJobExecutionInUserTransaction= false# 线程池的实现类
org.quartz.threadPool.class =org.quartz.simpl.SimpleThreadPool
# 线程数量
org.quartz.threadPool.threadCount= 10# 线程优先级,最大值为10,最小值为1
org.quartz.threadPool.threadPriority= 5#
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread= true# 持久化配置
#org.quartz.jobStore.class =org.quartz.simpl.RAMJobStore
org.quartz.jobStore.class =org.quartz.impl.jdbcjobstore.JobStoreTX
#org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.HSQLDBDelegate
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.scheduler.classLoadHelper.class=org.quartz.simpl.CascadingClassLoadHelper
#org.quartz.jobStore.useProperties= trueorg.quartz.jobStore.tablePrefix=QRTZ_
org.quartz.jobStore.maxMisfiresToHandleAtATime=1org.quartz.jobStore.selectWithLockSQL=SELECT * FROM {0}LOCKS UPDLOCK WHERE LOCK_NAME = ?org.quartz.jobStore.misfireThreshold= 60000#============================================================================# 配置插件
#============================================================================#org.quartz.plugin.triggHistory.class=org.quartz.plugins.history.LoggingJobHistoryPlugin
org.quartz.plugin.runningListener.class=com.sawyer.job.RunningListenerPlugin
org.quartz.plugin.runningListener.LogRunningInfo=true
我在quartz.properties中,配置了一个自定义的插件:com.sawyer.job.RunningListenerPlugin,可以在这里做一些比较有意义的事情。另外就是,我并没有将数据库信息配置在quart.properties中,而是选择另行配置,目的为了将数据库信息集中到一起,方便操作,实际项目中,也推荐使用这种方式。
3.3 application-data.xml
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd">
3.4 application-job.xml
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
这一步的scheduler配置与上文的基本一致,只是配置了dataSource和引入了quartz.properties文件
3.5 自定义插件 RunningListenerPlugin
/** #{copyright}#*/
packagecom.sawyer.job;importorg.quartz.ListenerManager;importorg.quartz.Scheduler;importorg.quartz.SchedulerException;importorg.quartz.impl.matchers.EverythingMatcher;importorg.quartz.spi.ClassLoadHelper;importorg.quartz.spi.SchedulerPlugin;importorg.slf4j.Logger;importorg.slf4j.LoggerFactory;importorg.springframework.context.ApplicationContext;public class RunningListenerPlugin implementsSchedulerPlugin {private final Logger log =LoggerFactory.getLogger(getClass());privateScheduler scheduler;private booleanisLogRunningInfo;
@Overridepublic void initialize(String s, Scheduler scheduler, ClassLoadHelper classLoadHelper) throwsSchedulerException {this.scheduler =scheduler;
System.out.println("################## 调度器初始化 ##################");
}
@Overridepublic voidstart() {
System.out.println("################## 调度器启动 ###################");try{
ApplicationContext applicationContext= (ApplicationContext) scheduler.getContext().get("applicationContext");
System.out.println("获取到的 ApplicationContext :" +applicationContext);
ListenerManager listenerManager=scheduler.getListenerManager();if(isLogRunningInfo()) {
listenerManager.addJobListener(newJobRunningListener(applicationContext), EverythingMatcher.allJobs());
listenerManager.addSchedulerListener(newSchedulerRunningListener(applicationContext));
}
}catch(SchedulerException e) {throw newRuntimeException(e);
}
}
@Overridepublic voidshutdown() {
System.out.println("############# 调度器关闭 ##################");
}public booleanisLogRunningInfo() {returnisLogRunningInfo;
}public void setLogRunningInfo(booleanlogRunningInfo) {
isLogRunningInfo=logRunningInfo;
}
}
可以添加多个监听器,实现各种各样的业务需求,比如用于任务结束后发邮件,记录更为详细的运行信息等。只需要实现响应的接口即可,这里我选择了添加JobRunningListener和SchedulerRunningListener。
JobRunningListener
/** #{copyright}#*/
packagecom.sawyer.job;import org.quartz.*;importorg.springframework.context.ApplicationContext;public class JobRunningListener implementsJobListener {private final static String LISTENER_NAME = "JobRunningListener";privateApplicationContext applicationContext;publicJobRunningListener(ApplicationContext applicationContext) {this.applicationContext =applicationContext;
}
@OverridepublicString getName() {returnLISTENER_NAME;
}
@Overridepublic voidjobToBeExecuted(JobExecutionContext jobExecutionContext) {
System.out.println("######### job 准备开始执行 ##########");
}
@Overridepublic voidjobExecutionVetoed(JobExecutionContext jobExecutionContext) {
System.out.println("######### job 被否决了 ##########");
}
@Overridepublic voidjobWasExecuted(JobExecutionContext jobExecutionContext, JobExecutionException e) {
System.out.println("######### job 执行完毕 ##########");
}
}
SchdulerRunningListener
/** #{copyright}#*/
packagecom.sawyer.job;import org.quartz.*;importorg.springframework.context.ApplicationContext;public class SchedulerRunningListener implementsSchedulerListener {private finalApplicationContext applicationContext;publicSchedulerRunningListener(ApplicationContext applicationContext) {this.applicationContext =applicationContext;
}
@Overridepublic voidjobScheduled(Trigger trigger) {
}
@Overridepublic voidjobUnscheduled(TriggerKey triggerKey) {
}
@Overridepublic voidtriggerFinalized(Trigger trigger) {
}
@Overridepublic voidtriggerPaused(TriggerKey triggerKey) {
}
@Overridepublic voidtriggersPaused(String s) {
}
@Overridepublic voidtriggerResumed(TriggerKey triggerKey) {
}
@Overridepublic voidtriggersResumed(String s) {
}
@Overridepublic voidjobAdded(JobDetail jobDetail) {
}
@Overridepublic voidjobDeleted(JobKey jobKey) {
System.out.println("############ " + jobKey.getGroup() + " 下的 " + jobKey.getName() + "已被删除 ###################");
}
@Overridepublic voidjobPaused(JobKey jobKey) {
}
@Overridepublic voidjobsPaused(String s) {
}
@Overridepublic voidjobResumed(JobKey jobKey) {
}
@Overridepublic voidjobsResumed(String s) {
}
@Overridepublic voidschedulerError(String s, SchedulerException e) {
}
@Overridepublic voidschedulerInStandbyMode() {
}
@Overridepublic voidschedulerStarted() {
}
@Overridepublic voidschedulerStarting() {
}
@Overridepublic voidschedulerShutdown() {
}
@Overridepublic voidschedulerShuttingdown() {
}
@Overridepublic voidschedulingDataCleared() {
}
}
3.6 执行调用
packagecom.sawyer;importcom.sawyer.job.AbstractJob;import org.quartz.*;importorg.slf4j.Logger;importorg.slf4j.LoggerFactory;importorg.springframework.context.ApplicationContext;importorg.springframework.context.support.ClassPathXmlApplicationContext;public classMain {private static final Logger logger = LoggerFactory.getLogger(Main.class);public static voidmain(String[] args) {
String configLocation= "classpath:spring/applicationContext*.xml";
ClassPathXmlApplicationContext context= newClassPathXmlApplicationContext(configLocation);try{
createJob(context);
}catch(SchedulerException e) {
e.printStackTrace();
}
logger.info("Container has been startup.");
}public static void createJob(ApplicationContext context) throwsSchedulerException {final String jobClassName = "com.sawyer.job.TestJob";final String jobName = "test_job";final String jobGroup = "test_group";final String jobDescription = "这是TestJob的描述信息";final String triggerName = "test_trigger";final String triggerGroup = "test_trigger_group";final String cron = "0/5 * * * * ?";//加载job类,并判断 job类的父类是否为AbstractJob
boolean assignableFrom = false;
Class forName= null;try{
forName=Class.forName(jobClassName);
assignableFrom= AbstractJob.class.isAssignableFrom(forName);
}catch(ClassNotFoundException e) {if(logger.isErrorEnabled()) {
logger.error(e.getMessage(), e);
}
}
JobBuilder jb=JobBuilder.newJob(forName).withIdentity(jobName, jobGroup)
.withDescription(jobDescription);//放入数据
JobDataMap data = newJobDataMap();
data.put("count", 5);
jb=jb.usingJobData(data);
JobDetail jobDetail=jb.build();
TriggerBuilder triggerBuilder =TriggerBuilder.newTrigger()
.withIdentity(triggerName, triggerGroup).forJob(jobDetail);
ScheduleBuilder sche=CronScheduleBuilder.cronSchedule(cron);
Trigger trigger=triggerBuilder.withSchedule(sche).build();
Scheduler quartzScheduler= (Scheduler) context.getBean("quartzScheduler");
quartzScheduler.scheduleJob(jobDetail, trigger);
}
}
这里使用的job类仍然是上文中的TestJob,只是改用程序生成调用而已,另外这里的count我手动赋值成了5
3.7 运行结果:
查看数据表,可以发现已经新增了相关的记录了:
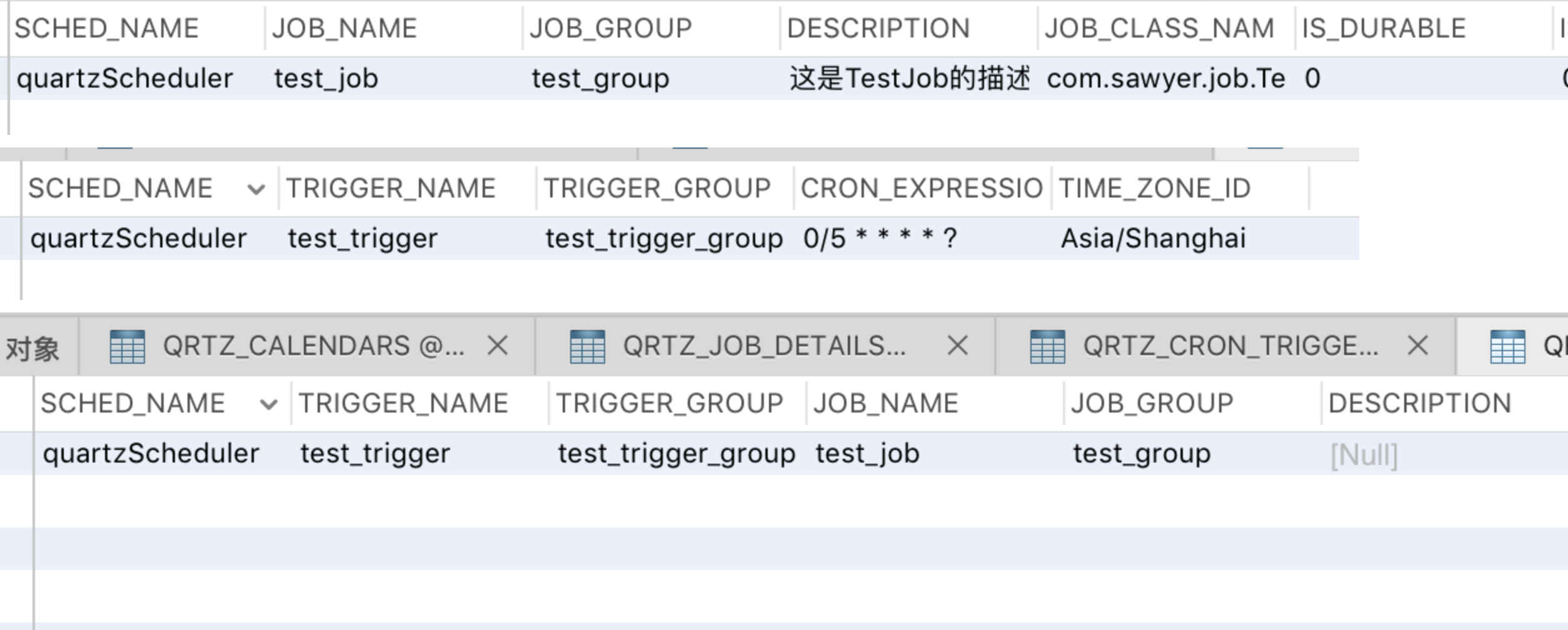
到此,quartz持久化配置就完成了。
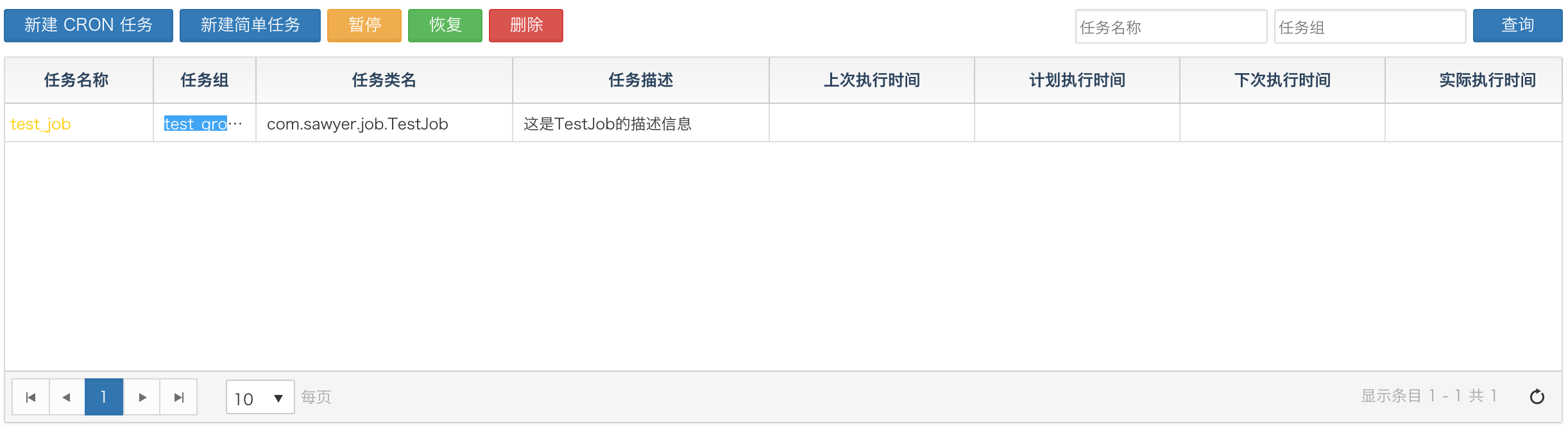
四、 Job操作
quartz是通过jobName和jobGroup来区分job的,所以job的name和group一定要填写,然后通过这个就可以对job进行添加、暂停、恢复和删除了。
添加:quartzScheduler.scheduleJob(jobDetail,trigger)
暂停:quartzScheduler.pauseJob(JobKey.jobKey(jobName,jobGroup))
恢复:quartzSchduler.resumeJob(JobKey.jobKey(jobName,jobGroup))
删除:quartScheduler.deleteJob(JobKey.jobKey(jobName,jobGroup))
通过这些方法就可以对job做一些基本的管理了,体现在web上的效果,如下:

















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









