





注:本文参考北大曹键老师,在B站的tensorflow2.0课程中,自制数据集代码
1.问题:当我们自制图片数据集时,往往把每类单独放在一个文件夹中,当按照上述方法制作数据集时,需要在训练集或测试集的文件夹中放入所有类的图片,这时由于命名标签原因,往往按类排序,如下图所示,这对于后续训练网络有影响。
那如何乱序文件图片,再生成数据集呢?

2.图片乱序
以二分类为例,通过以下代码使得图片列别乱序排列
注:图片命名格式:(序号-类别)
乱序前:

乱序后:

代码(python):
1.图片乱序代码
注:该代码将直接修改原图片的命名
import os
import numpy as np
path = "I:波形分类0626乱序实验image" #存放图片的路径
filelist = os.listdir(path) #该文件夹下所有的文件(包括文件夹)
count=0
for file in filelist:
print(file)
Lrand = np.arange(304) #304指的是该文件下的图片数量,根据实际而修改
np.random.shuffle(Lrand )
print(Lrand)
for file in filelist: #遍历所有文件
Olddir=os.path.join(path,file) #原来的文件路径
if os.path.isdir(Olddir): #如果是文件夹则跳过
continue
filename=os.path.splitext(file)[0][-1] #文件名
print(filename)
filetype=os.path.splitext(file)[1] #文件扩展名
filename_int = int(filename)
Newdir = os.path.join(path, str(Lrand[count]) + '_' + filename + filetype)
os.rename(Olddir,Newdir)#重命名
count+=12.生成图片相应的txt文档标签代码
import os
path = "I:波形分类0626乱序实验image" #相应图片所在文件路径
file_list = []
write_file_name = 'I:波形分类0626seismci_classimage11.txt' #生成的txt文件路径
filelist = os.listdir(path) #该文件夹下所有的文件(包括文件夹)
count=0
write_file = open(write_file_name, "w") #以只写方式打开write_file_name文件
for file in os.listdir(path): #遍历所有文件
filename=os.path.splitext(file)[0] #文件名
filename_last = os.path.splitext(file)[0][-1]
filetype=os.path.splitext(file)[1] #文件扩展名
Newdir = os.path.join(file + ' ' + filename_last )
file_list.append(Newdir)
count+=1
number_of_lines = len(file_list)#列表中元素个数
print('file_list1:',file_list)
file_list.sort(key=lambda item:len(str(item)), reverse=False)#排序
print('file_list:',file_list)
print(type(file_list))
for current_line in range(number_of_lines):
write_file.write(file_list[current_line] + 'n') # 关闭文件生成的txt文件:
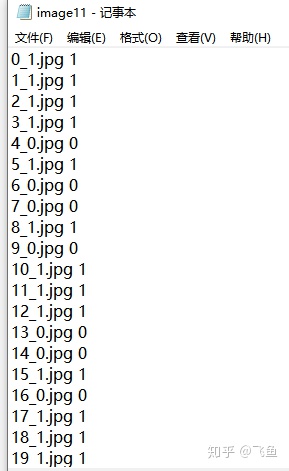
3.生成训练集与测试集的npy文件
代码:
import tensorflow as tf
from PIL import Image
import numpy as np
import os
train_path = './train_jpg_404_g/' #存放训练集图片路径
train_txt = 'train_jpg_404.txt' #存放的训练集txt标签文件
x_train_savepath = 'x_train.npy'
y_train_savepath = 'y_train.npy'
test_path = './test_jpg_102_g/' #存放测试集图片路径
test_txt = 'test_jpg_102.txt' #存放的测试集txt标签文件
x_test_savepath = 'x_test.npy'
y_test_savepath = 'y_test.npy'
def generateds(path, txt):
f = open(txt, 'r') # 以只读形式打开txt文件
contents = f.readlines() # 读取文件中所有行
f.close() # 关闭txt文件
x, y_ = [], [] # 建立空列表
for content in contents: # 逐行取出
value = content.split() # 以空格分开,图片路径为value[0] , 标签为value[1] , 存入列表
img_path = path + value[0] # 拼出图片路径和文件名
img = Image.open(img_path) # 读入图片
img = np.array(img.convert('L')) # 图片变为8位宽灰度值的np.array格式
img = img / 255. # 数据归一化 (实现预处理)
x.append(img) # 归一化后的数据,贴到列表x
y_.append(value[1]) # 标签贴到列表y_
print('loading : ' + content) # 打印状态提示
x = np.array(x) # 变为np.array格式
y_ = np.array(y_) # 变为np.array格式
y_ = y_.astype(np.int64) # 变为64位整型
return x, y_ # 返回输入特征x,返回标签y_
if os.path.exists(x_train_savepath) and os.path.exists(y_train_savepath) and os.path.exists(
x_test_savepath) and os.path.exists(y_test_savepath):
print('-------------Load Datasets-----------------')
x_train_save = np.load(x_train_savepath)
y_train = np.load(y_train_savepath)
x_test_save = np.load(x_test_savepath)
y_test = np.load(y_test_savepath)
x_train = np.reshape(x_train_save, (len(x_train_save), 28, 28))
x_test = np.reshape(x_test_save, (len(x_test_save), 28, 28))
else:
print('-------------Generate Datasets-----------------')
x_train, y_train = generateds(train_path, train_txt)
x_test, y_test = generateds(test_path, test_txt)
print('-------------Save Datasets-----------------')
x_train_save = np.reshape(x_train, (len(x_train), -1))
x_test_save = np.reshape(x_test, (len(x_test), -1))
np.save(x_train_savepath, x_train_save)
np.save(y_train_savepath, y_train)
np.save(x_test_savepath, x_test_save)
np.save(y_test_savepath, y_test)生成文件:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









