



 本文介绍了Perl如何输出匹配的当前行及其下一行,并对比了sed和awk在文本处理中的应用。sed主要用于文本内容替换,awk则更适合统计和格式化输出。文中还详细讲解了sed的多行模式、保持空间以及awk的脚本流程控制、字段与记录、数组操作等概念。
本文介绍了Perl如何输出匹配的当前行及其下一行,并对比了sed和awk在文本处理中的应用。sed主要用于文本内容替换,awk则更适合统计和格式化输出。文中还详细讲解了sed的多行模式、保持空间以及awk的脚本流程控制、字段与记录、数组操作等概念。

正则表达式与文本搜索
元字符介绍
. 匹配除换行符外的任意单字符
*匹配任意一个跟在它前面的字符 零次或多次
[] 匹配方括号中的字符类中的任意一个
^匹配开头
$匹配结尾
转义后面的特殊字符
[hH]ello
pass.*
pass.*$
以#开头 :^#
以#结尾 : #$
grep 行检索,输出匹配行:
根据完整单词查找:grep password anaconda-ks.cfg
模糊查询:grep pass....$ anaconda-ks.cfg
查找行中包含 . : grep "." anaconda-ks.cfg扩展元字符
+ 匹配前面的正则表达式一次或多次
?匹配前面的正则表达式零次或一次
| 匹配它前面或者后面的正则表达式文件查找命令
find 路径 查找条件 [补充条件]
查找:find /etc -regex .*wd
找到并操作:find *txt -exec rm -v {} ;
找到此文件中包含pass的行并以空格做剪切取第一个字段:
grep pass /etc/anaconda-ks.cfg | cut -d " " -f 1
统计shell:
cut -d ":" -f7 /etc/passwd | sort | uniq -c
统计shell 并反向排序:
cut -d ":" -f7 /etc/passwd | sort | uniq -c | sort -r
sed
- vim 与 sed 、awk 区别:
- vim 全文本编辑器,交互式
- sed 、awk 行编辑器,非交互式
2. sed :一般对文本内容做替换
3. awk : 一般对文本内容进行统计,按需要的格式进行输出
4. sed 替换:将文件以行为单位读取到内存(模式空间),使用sed的每个脚本对该行工作,处理完成后输出该行。
sed 的替换命令 s:
单命令单文件:sed 's/old/new/' filename 只替换一次
替换斜线 / :sed 's!/!new!' filename 除 / 外的任何符号作分割
多命令多文件:sed -e 's/old/new/' filename -e 's/old/new/' filename ...
sed 's/old/new/;s/old/new/' filename ...
替换后结果写回文件: sed -I 's/old/new/' 's/old/new/' filename ...
sed -i 's/old/new/;s/old/new/' filename ...
正则表达式:sed 's/正则表达式/new/' filename
拓展正则表达式:sed -r 's/拓展正则表达式/new/' filename
eg:
替换 root 开头的行: grep root /etc/passwd | sed 's/^root//'
扩展元字符 | : sed -r 's/a|b/!/' filename
扩展元字符 | : sed -r 's/(aa)|(bb)/!/' filename
被替换字符的引用a替换成aaa: sed -r 's/a/111/' filename5. sed 替换命令加强版
全局替换
sed ‘s/old/new/g’ filename 替换所有出现的次数
标志位
sed ‘s/old/new/2’ filename 替换第二次
sed ‘s/old/new/p’ filename 输出全部 并且再次输出匹配上的
sed -n ‘s/old/new/p’ filename 只输出匹配上的
sed -n ‘s/old/new/w /tmp/a.txt’ filename 将结果写回到/tmp/a.txt
寻址
/正则表达式/s/old/new/g
行号s/old/new/g
1,$s/old/new/g 1到最后一行
分组
/正则表达式/{s/old/new/;s/old/new/}
sed 脚本文件
sed -f sedscript filename6. sed 其他指令
删除命令:
[寻址]d :删除模式空间内容,改变脚本的控制流,读取新的输入行
sed '/ab/d' filename
追加a、上插入i、更改c:
sed '/ab/i hello' filename 在检索ab的行上面插入hello
sed '/ab/a hello' filename 在检索ab的行下面插入hello
sed '/ab/c hello' filename 在检索ab的行直接替换
打印p:sed -n '/ab/p' filename
打印行号=:
下一行n:本行不做处理
读文件r和写文件w:
退出命令q:
time sed -n '1,10p' filename 把文件内容都读取到内存中,再处理前十行
time sed -n '10q' filename. 效率高,只读十行7. sed 的多行模式
配置文件一般为单行出现,也有使用XML或JSON格式的配置文件多行出现
多行匹配命令:
- N 将下一行加入到模式空间
- D 删除模式空间的第一个字符到第一个换行符
- P 打印模式空间中的第一个字符到第一个换行符
8. 保持空间
保持空间也是多行操作的一种方式,将内容暂存到保存空间,便于做多行处理

如果想让前两行做合并,可以先将第一行读取到模式空间,然后存放到保持空间,在将第二行读取到模式空间,将保持空间的第一行和模式空间的第二行做合并。从模式空间将结果输出到终端。所以 保持空间 不可以使用 s 命令
对保持空间进行读写的操作指令如下:
- 将模式空间内容存放至保持空间:h/H 小写为覆盖模式 大写为追加模式
- 将保持空间内容取回至模式空间:g/G 小写为覆盖模式 大写为追加模式
- x 交换模式空间和保持空间内容:x
AWK
awk 更像是脚本语言,用于更加规范的文本处理,用于统计数量并输出指定字段。
使用 sed 将不规范的文本处理成较规范的文本。
awk 脚本的流程控制
- 输入数据前例程,BEGIN{} 变量定义
- 主输入循环{}
- 所有文件读取完成例程 END{} 汇总
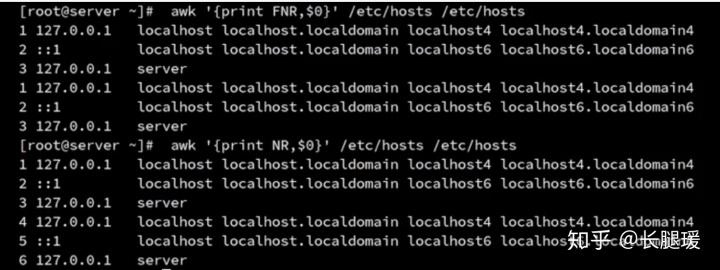
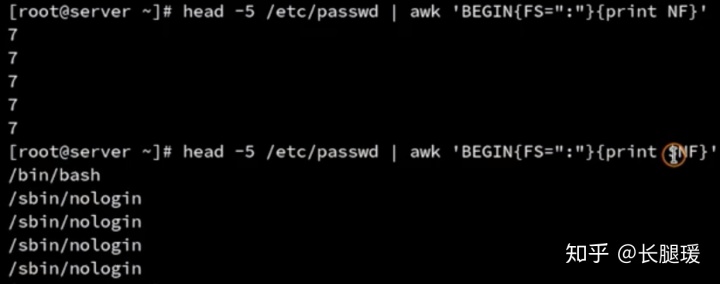
awk字段与记录
- 记录:每行称作awk记录
- 字段:使用空格或者制表符分割出来的单词叫做字段
字段的引用
awk 使用 $1 $2 .... $n表示每一个字段 ,默认指定分隔符为制表符或者空格
awk '/^he/{print $1,$2,$3} ' filename
awk 可以使用 -F 选项改变字段分隔符,分隔符可以使用正则表达式
awk -F ',' '{print $1,$2,$3} ' filename
检索 grub2 引导的内核并标明行号:
awk -F " ' " '/^menu/{print x++,$2}' /boot/grub2/grub.cfg awk 表达式
- 赋值操作符
var1 = "hello"
var2 = "hello" "world"
var3 = $1
其他赋值操作符: ++、--、+=、%=、^=- 算数操作符
+ - * / % ^- 系统变量

- 布尔操作符
&& 、|| 、!- 关系操作符
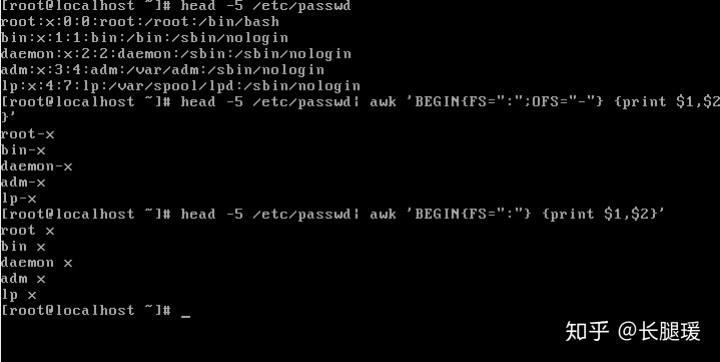
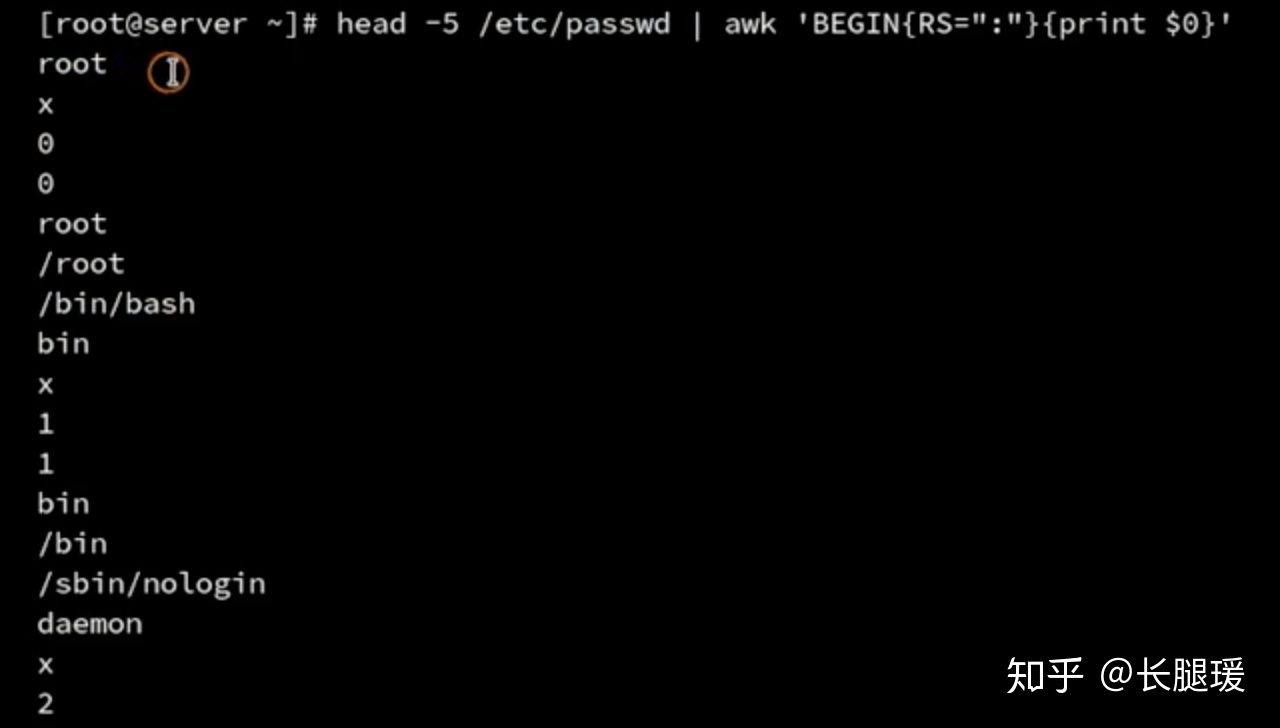
<、 >、 ==、 <=、 >=、 !=、 ~、 !~
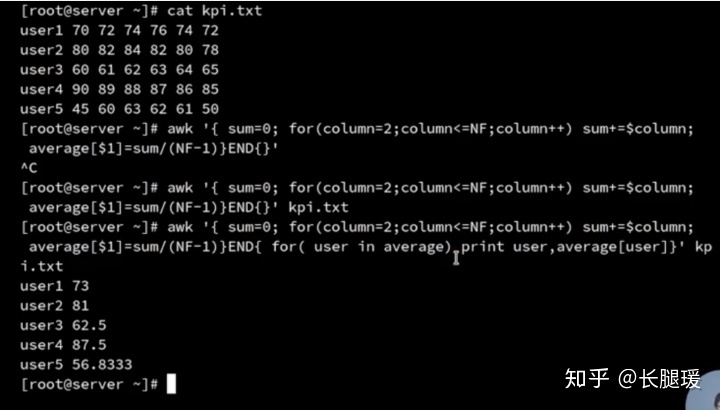
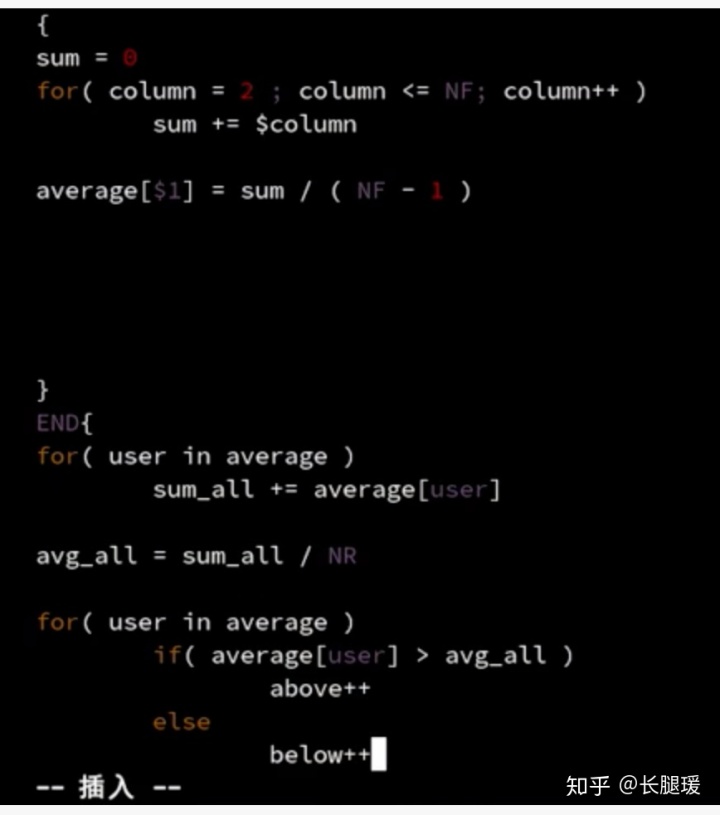
AWK 数组
数组的定义: 数组[下标]=值 下标可以使用数组也可以使用字符串
数组的遍历: for(变量 in 数组名)
删除数组: delete 数组[下标]
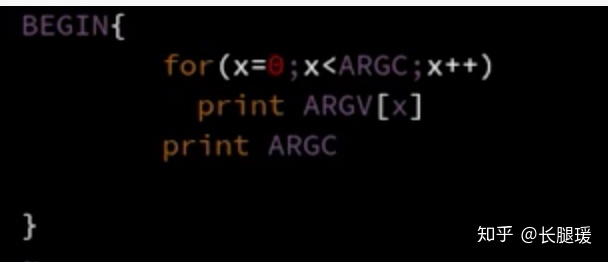
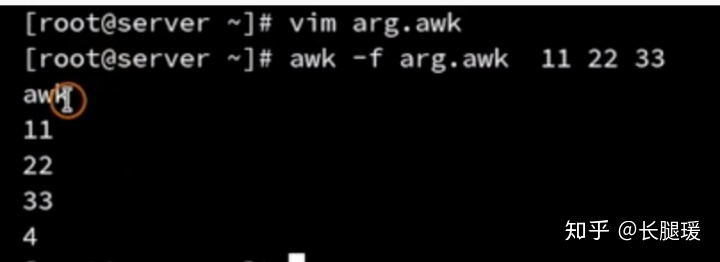
命令行参数数组:
- ARGC
- ARGV


















 5902
5902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









