



 本文介绍了如何使用Python的NumPy和pandas库进行数据处理,包括一维和二维数据的分析,如定义数组、查询、切片、统计计算、向量化运算、缺失值处理以及条件判断等,详细讲解了这两个库在处理数组和数据框时的常用操作。
本文介绍了如何使用Python的NumPy和pandas库进行数据处理,包括一维和二维数据的分析,如定义数组、查询、切片、统计计算、向量化运算、缺失值处理以及条件判断等,详细讲解了这两个库在处理数组和数据框时的常用操作。

NumPy 和 pandas 是 Python 常见的两个科学运算的包,提供了比 Python 列表更高级的数组对象且运算效率更高。常用于处理大量数据并从中提取、分析有用指标。
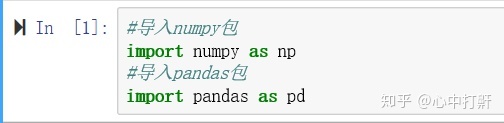
使用之前,需要先在conda中安装这两个包,安装命令:
conda install numpy,pandas安装成功以后载入两个包:
1、运用 NumPy 分析一维数据
1.1 定义一维数组:

1.2 查询:

1.3 切片访问 - 获取指定序号范围的元素

1.4 查询数据类型:

1.5 统计计算 - 平均值

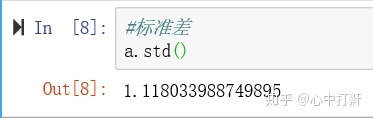
1.6 统计计算 - 标准差
1.7 向量化运行 - 乘以标量

2、运用 pandas 分析一维数据
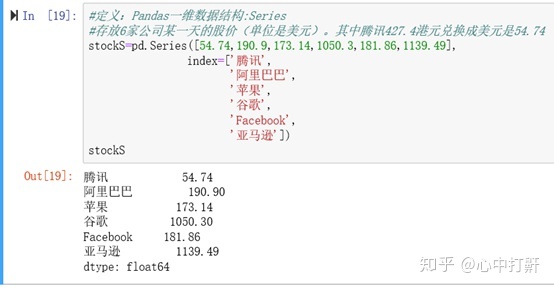
2.1 定义 Pandas 一维数据结构:定义 Pandas 一维数据结构 – Series
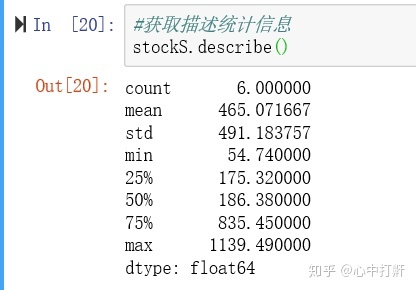
2.2获取描述统计信息:
2.3 iloc属性用于根据索引获取值

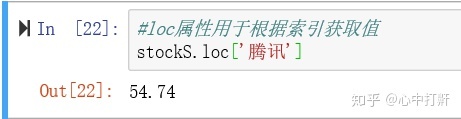
2.4 loc属性用于根据索引获取值
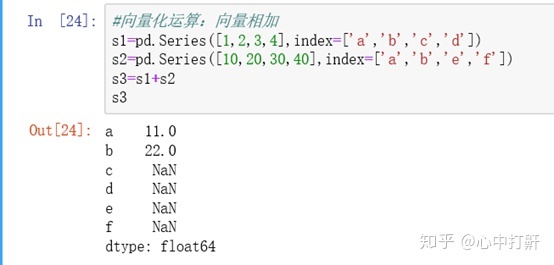
2.5 向量化运算 - 向量相加
2.6 删除缺失值

2.7 填充缺失值

3、运用 NumPy 分析二维数据
3.1定义二维数组:

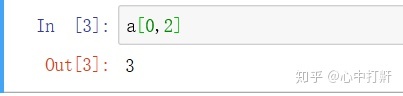
3.2 获取元素:
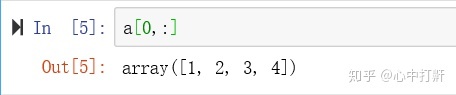
3.3 获取行:
3.4 获取列
3.5 NumPy数轴参数:axis
1) 如果没有指定数轴参数,会计算整个数组的平均值.

2) 按轴计算:axis=1 计算每一行

3) 按轴计算:axis=0 计算每一列

4. 运用 pandas 分析二维数据
pandas 二维数组:数据框(DataFrame)
4.1 定义数据框

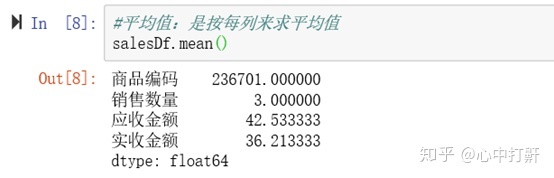
4.2 平均值
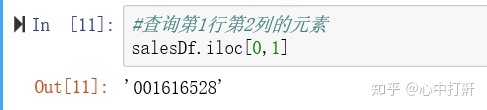
4.3 查询数据 - iloc属性用于根据位置获取值
1) 查询第1行第2列的元素
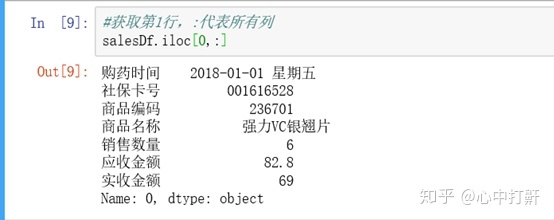
2) 获取第1行 - 代表所有列
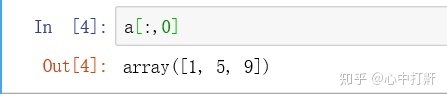
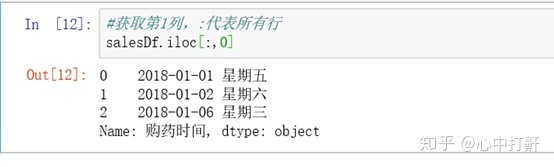
3) 获取第1列 - 代表所有行
4.4 查询数据 - loc属性用于根据索引获取值
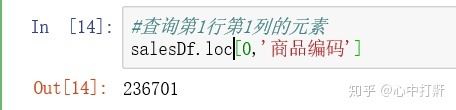
1) 获取第1行商品编码元素
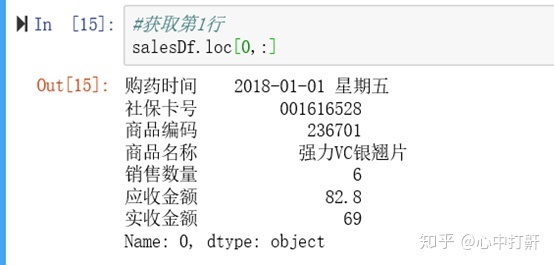
2) 获取第1行
3) 获取“商品名称”这一列

4)简单方法:获取“商品名称”这一列

4.5 数据框复杂查询 - 切片功能
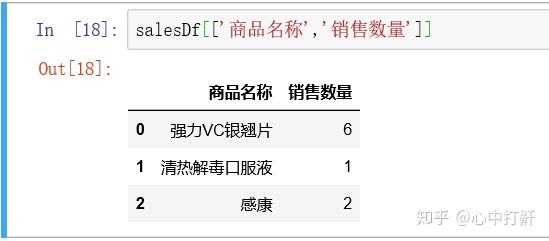
1) 通过列表来选择某几列的数据
2)通过切片功能,获取指定范围的列
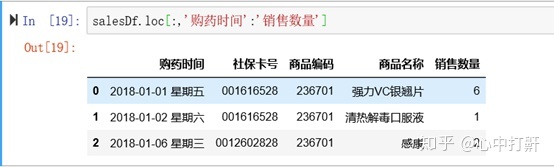
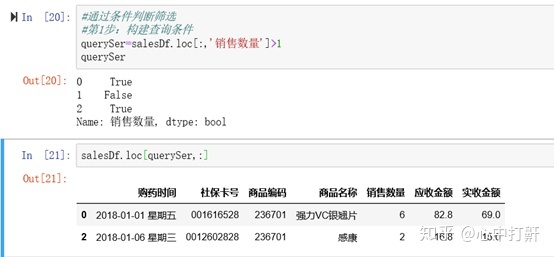
4.6 数据框复杂查询 - 条件判断
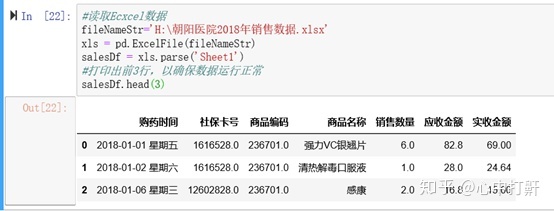
4.7 查看数据集描述统计信息
1 ) 读取 Ecxcel 数据
2) 查询行、列总数

3)查看某一列的数据类型

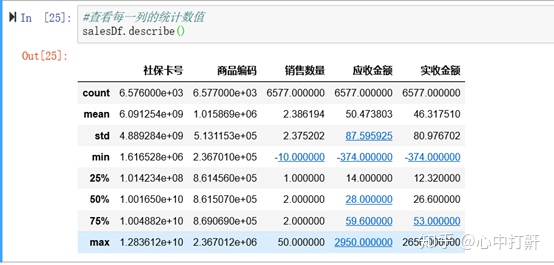
4)查看每一列的统计数值

















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









