





 本文介绍了Kafka消息从发送到消费的过程,重点关注消息的分区策略。通过ProducerRecord,可以指定分区ID或使用Key进行分区。Key通过hash计算决定分区,若未指定,则采用round-robin模式。寻找分区leader时,生产者会定期更新元信息。消息发送的可靠性由acks参数控制,acks=all提供最高保障。
本文介绍了Kafka消息从发送到消费的过程,重点关注消息的分区策略。通过ProducerRecord,可以指定分区ID或使用Key进行分区。Key通过hash计算决定分区,若未指定,则采用round-robin模式。寻找分区leader时,生产者会定期更新元信息。消息发送的可靠性由acks参数控制,acks=all提供最高保障。
Kafka作为一个常用消息中间件,他具备很多优秀的特点,在此,文章从消息的发送到kafka存储,然后到消费方进行消费,进行一个流程性的介绍,希望能够对kafka有个基本的了解
首先,我们如何向kafka发送消息的呢?

其中 客户端的代码连接到kafka集群地址,设置所有的消息都需要ack返回,重试次数为0等信息。生成消息生产者producer,producer连接到Kafka集群,根据消息进行分区计算,将消息发送leader分区的broker。
那么如何进行分区确定?
如何寻找到leader分区,如何感知leader分区的变化?
如何确保消息发送的可靠性?
消息分区的确定:

其中ProducerRecord,就提供了参数,让生产者对消息指定分区

<1> 若指定Partition ID,则ProducerRecord被发送至指定Partition
<2> 若未指定Partition ID,但指定了Key, ProducerRecord会按照hasy(key)发送至对应Partition
<3> 若既未指定Partition ID也没指定Key,ProducerRecord会按照round-robin模式发送到每个Partition
<4> 若同时指定了Partition ID和Key, ProducerRecord只会发送到指定的Partition (Key不起作用,代码逻辑决定)
寻找分区leader
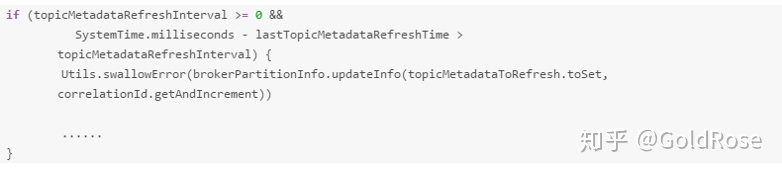
当生产者发送消息失败(分区消失,不可用),生产者会更新topic分区元信息,
正常情况下,每隔topic.metadata.refresh.interval.ms(缺省10分钟)去轮询分区变化。在生产者的代码中
消息发送的可靠性
props.put(“acks”,”all”) ,这个acks作为消息发送的可靠性重要的参数,
acks=0 生产者不会等待broker的任何确认,消息会被立即添加到缓冲区并被认为已经发送
acks=1,在leader服务器的副本收到消息的同一时间,生产者会接收到broker的确认
acks=all(或-1),一旦所有的同步副本接收到消息,生产者才会接收到broker的确认。这是最安全的模式。
以上是kafka发送消息流程的一些思考和总结


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









