





01
背景
基于前面的文章
Flink集成hive bath模式用例
knowfarhhy,公众号:大数据摘文Flink 集成Hive
,我们继续介绍stream模式下的用例。
02
流模式读取Hive
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build(); TableEnvironment tableEnv = TableEnvironment.create(bsSettings); //增加hive支持 String name = "myhive"; String defaultDatabase = "dim"; String version = "1.2.1"; String hivecondir = System.getenv("HIVE_CONF_DIR"); HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hivecondir, version); log.info("注册catalog"); tableEnv.registerCatalog(name, hive); log.info("注册catalog完成"); log.info("使用catalog"); tableEnv.useCatalog(name); log.info("注册database"); tableEnv.useDatabase(defaultDatabase); tableEnv.sqlQuery("SELECT name,age,score,dt FROM myhive.dim.dim_flink_test").printSchema(); String[] fields = new String[4]; fields[0] = "name"; fields[1] = "age"; fields[2] = "score"; fields[3] = "dt"; TypeInformation[] fieldType = new TypeInformation[4]; fieldType[0] = Types.STRING; fieldType[1] = Types.INT; fieldType[2] = Types.LONG; fieldType[3] = Types.STRING; PrintTableUpsertSink sink = new PrintTableUpsertSink(fields,fieldType,true); tableEnv.registerTableSink("inserttable",sink); tableEnv.sqlUpdate("INSERT INTO inserttable SELECT name,age,score,dt FROM myhive.dim.dim_flink_test"); tableEnv.execute("stream_read_hive");03
运行拓扑
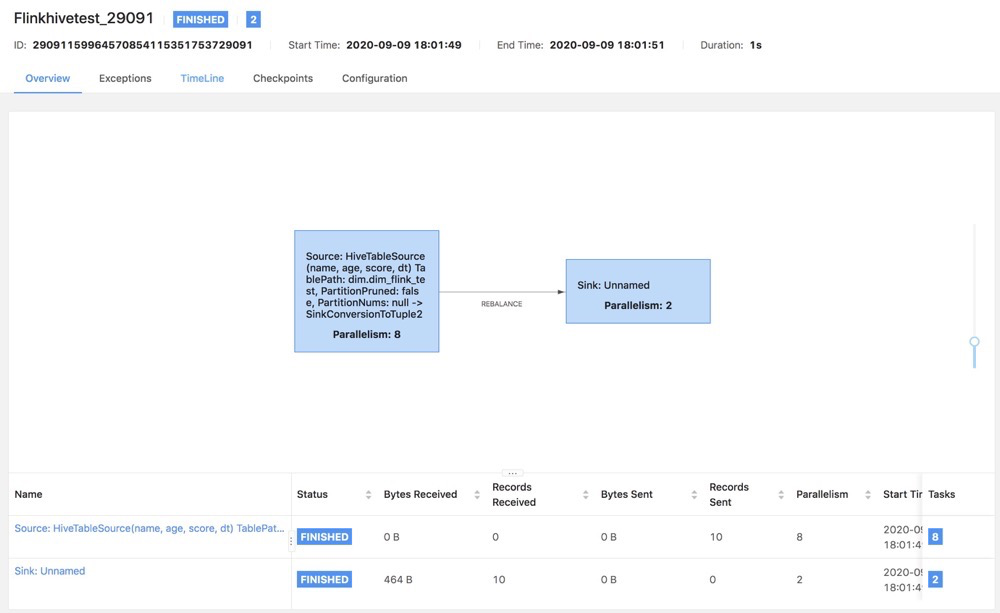
上图展示了第二节中的测试用例任务的拓扑图,我们会发现在流任务中出现了Finish这样的最终状态,而不是一个Running状态,这个主要是目前1.10版本支持Hive的功能没有那么完善,无法真正的实时读取Hive数据,以及无法检测Hive数据发生改变情况,只会在任务运行时候读取一次表数据,然后Hive相关的算子任务便会结束。如果想要更好的使用Hive,建议大家还是用Flink 1.11之后,功能更加强大完善。
为了方便看流任务,有Finished状态,提供另外一个流任务的拓扑图,便于看到区别:
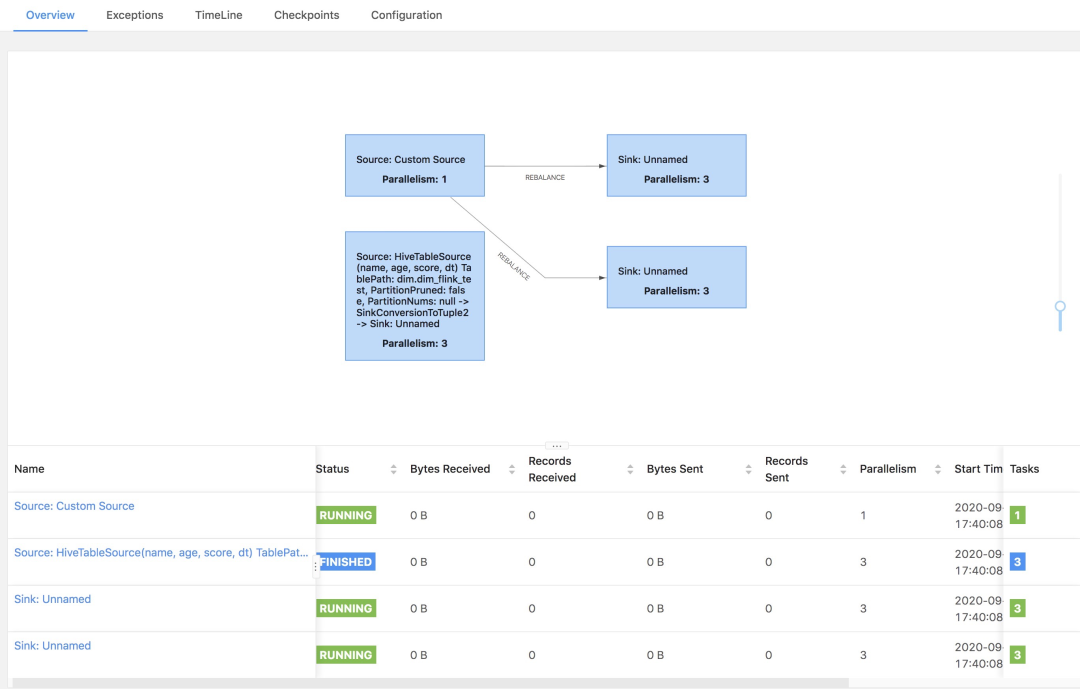
具体的流方式读取Hive,即Hive Streaming,在Flink 1.11进行了相关的支持,这里提供几篇参考文章:

相关Hive Streaming文章
Flink 1.11 新特性之 SQL Hive Streaming 简单示例
LittleMagic,公众号:Flink 中文社区Flink 1.11 新特性之 SQL Hive Streaming 简单示例
Flink x Zeppelin ,Hive Streaming 实战解析
狄杰@蘑菇街,公众号:Flink 中文社区Flink x Zeppelin ,Hive Streaming 实战解析
Flink SQL FileSystem Connector 分区提交与自定义小文件合并策略
LittleMagic,公众号:Flink 中文社区Flink SQL FileSystem Connector 分区提交与自定义小文件合并策略
Flink 1.11 SQL 使用攻略
李劲松,公众号:Flink 中文社区Flink 1.11 SQL 使用攻略
04
注意事项
任务运行环境:
(1)设置Job默认并行度为2
(2)基于K8s运行,申请了一个JobManager 以及一个 TaskManager
(3)TaskManager设置了8个Slot
上面的拓扑中,我们可以看到第一个算子的并行度是8,第二个算子是2,任务正常执行,是因为增加了其他设置才使得任务正常运行。
但是你可能会遇到下面情况:
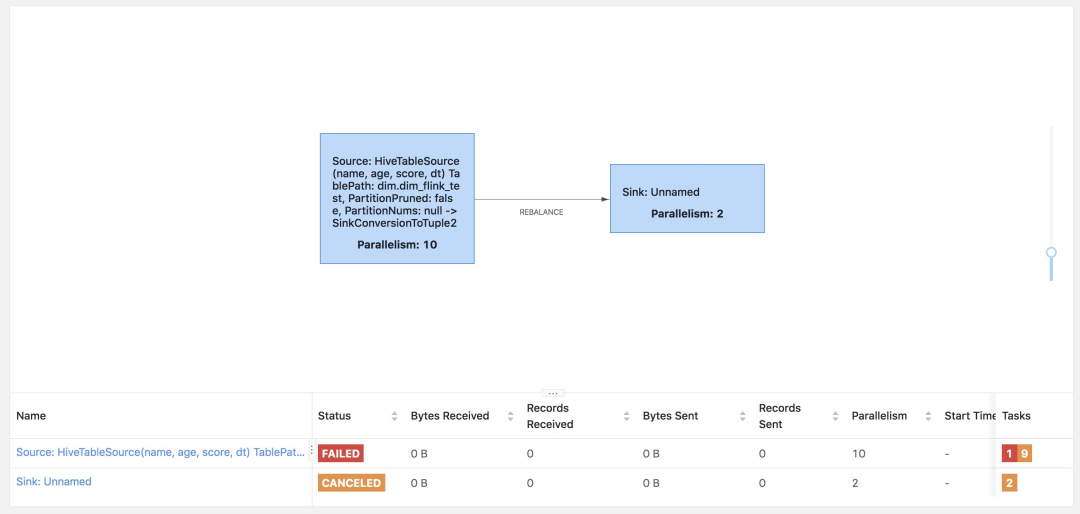
第一个算子并行度是10,第二个算子并行度是2,因为集群只有8个Slot可用,就会导致资源不够,任务一直处于created状态,最终超时失败。
问题分析:
下面展示了设置HiveTableSource的并行度:
int parallelism = conf.get(ExecutionConfigOptions.TABLE_EXEC_RESOURCE_DEFAULT_PARALLELISM); if (conf.getBoolean(HiveOptions.TABLE_EXEC_HIVE_INFER_SOURCE_PARALLELISM)) { int max = conf.getInteger(HiveOptions.TABLE_EXEC_HIVE_INFER_SOURCE_PARALLELISM_MAX); if (max < 1) { throw new IllegalConfigurationException( HiveOptions.TABLE_EXEC_HIVE_INFER_SOURCE_PARALLELISM_MAX.key() + " cannot be less than 1"); } int splitNum; try { long nano1 = System.nanoTime(); splitNum = inputFormat.createInputSplits(0).length; long nano2 = System.nanoTime(); LOG.info( "Hive source({}}) createInputSplits use time: {} ms", tablePath, (nano2 - nano1) / 1_000_000); } catch (IOException e) { throw new FlinkHiveException(e); } parallelism = Math.min(splitNum, max); } parallelism = limit > 0 ? Math.min(parallelism, (int) limit / 1000) : parallelism; parallelism = Math.max(1, parallelism); source.setParallelism(parallelism);涉及的相关参数:
public class HiveOptions { public static final ConfigOption TABLE_EXEC_HIVE_FALLBACK_MAPRED_READER = key("table.exec.hive.fallback-mapred-reader") .defaultValue(false) .withDescription( "If it is false, using flink native vectorized reader to read orc files; " + "If it is true, using hadoop mapred record reader to read orc files."); public static final ConfigOption TABLE_EXEC_HIVE_INFER_SOURCE_PARALLELISM = key("table.exec.hive.infer-source-parallelism") .defaultValue(true) .withDescription( "If is false, parallelism of source are set by config.\n" + "If is true, source parallelism is inferred according to splits number.\n"); public static final ConfigOption TABLE_EXEC_HIVE_INFER_SOURCE_PARALLELISM_MAX = key("table.exec.hive.infer-source-parallelism.max") .defaultValue(1000) .withDescription("Sets max infer parallelism for source operator.");}table.exec.hive.infer-source-parallelism - true : 并行度通过推导得到,依赖splits 数量 - false : 通过config获得并行度table.exec.resource.default-parallelism 设置所有Operator(例如join agg filter等)的默认并行度table.exec.hive.infer-source-parallelism.max 设置HiveTableSource的最大并行度,默认值1000(1)首先从config中获取所有算子的默认并行度
int parallelism = conf.get(ExecutionConfigOptions.TABLE_EXEC_RESOURCE_DEFAULT_PARALLELISM);(2)如果没有开启并行度自动推导,那么使用这个默认并行度
(3)如果开启了并行度推导,会根据计算的split数量与设置的最大并行度取最小值:
parallelism = Math.min(splitNum, max);splitNum大小为下面方法返回数组的长度 public HiveTableInputSplit[] createInputSplits(int minNumSplits) throws IOException { List hiveSplits = new ArrayList<>(); int splitNum = 0; for (HiveTablePartition partition : partitions) { StorageDescriptor sd = partition.getStorageDescriptor(); InputFormat format; try { format = (InputFormat) Class.forName(sd.getInputFormat(), true, Thread.currentThread().getContextClassLoader()).newInstance(); } catch (Exception e) { throw new FlinkHiveException("Unable to instantiate the hadoop input format", e); } ReflectionUtils.setConf(format, jobConf); jobConf.set(INPUT_DIR, sd.getLocation()); //TODO: we should consider how to calculate the splits according to minNumSplits in the future. org.apache.hadoop.mapred.InputSplit[] splitArray = format.getSplits(jobConf, minNumSplits); for (org.apache.hadoop.mapred.InputSplit inputSplit : splitArray) { hiveSplits.add(new HiveTableInputSplit(splitNum++, inputSplit, jobConf, partition)); } } return hiveSplits.toArray(new HiveTableInputSplit[0]); }通过上面的参数配置 ,我们可以合理的控制HiveTableSource的并行度,不至于超过集群的资源配置,无法启动任务。



!关注不迷路~ 各种福利、资源定期分享!

















 1127
1127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









