





目前来说市面上可以选择的消息队列非常多,像 ActiveMQ,RabbitMQ,ZeroMQ 已经被大多数人耳熟能详。
 图片来自 Pexels
图片来自 Pexels
特别像 ActiveMQ 早期应用在企业中的总线通信,基本作为企业级 IT 设施解决方案中不可或缺的一部分。
目前 Kafka 已经非常稳定,并且逐步应用更加广泛,已经算不得新生事物,但是不可否认 Kafka 一枝独秀如同雨后春笋,非常耀眼,今天我们仔细分解一下 Kafka,了解一下它的内幕。 以下的内容版本基于当前最新的 Kafka 稳定版本 2.4.0。文章主要包含以下内容:Kafka 为什么快
Kafka 为什么稳
Kafka 该怎么用
Kafka 为什么快
快是一个相对概念,没有对比就没有伤害,因此通常我们说 Kafka 是相对于我们常见的 ActiveMQ,RabbitMQ 这类会发生 IO,并且主要依托于 IO 来做信息传递的消息队列。 像 ZeroMQ 这种基本纯粹依靠内存做信息流传递的消息队列,当然会更快,但是此类消息队列只有特殊场景下会使用,不在对比之列。 因此当我们说 Kakfa 快的时候,通常是基于以下场景:吞吐量:当我们需要每秒处理几十万上百万 Message 的时候,相对其他 MQ,Kafka 处理的更快。
高并发:当具有百万以及千万的 Consumer 的时候,同等配置的机器下,Kafka 所拥有的 Producer 和 Consumer 会更多。
磁盘锁:相对其他 MQ,Kafka 在进行 IO 操作的时候,其同步锁住 IO 的场景更少,发生等待的时间更短。
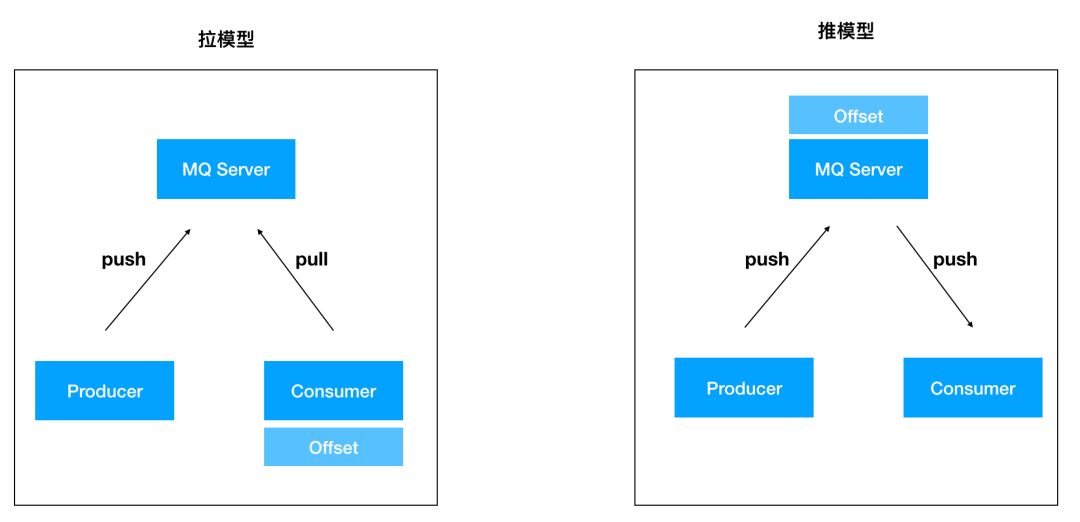
消息队列的推拉模型
首先,如果我们单纯站在 Consumer 的角度来看“Kafka 快”,是一个伪命题,因为相比其他 MQ,Kafka 从 Producer 产生一条 Message 到 Consumer 消费这条 Message 来看,它的时间一定是大于等于其他 MQ 的。 背后的原因涉及到消息队列设计的两种模型:推模型
拉模型
如下图所示:
OS Page Cache 和 Buffer Cache
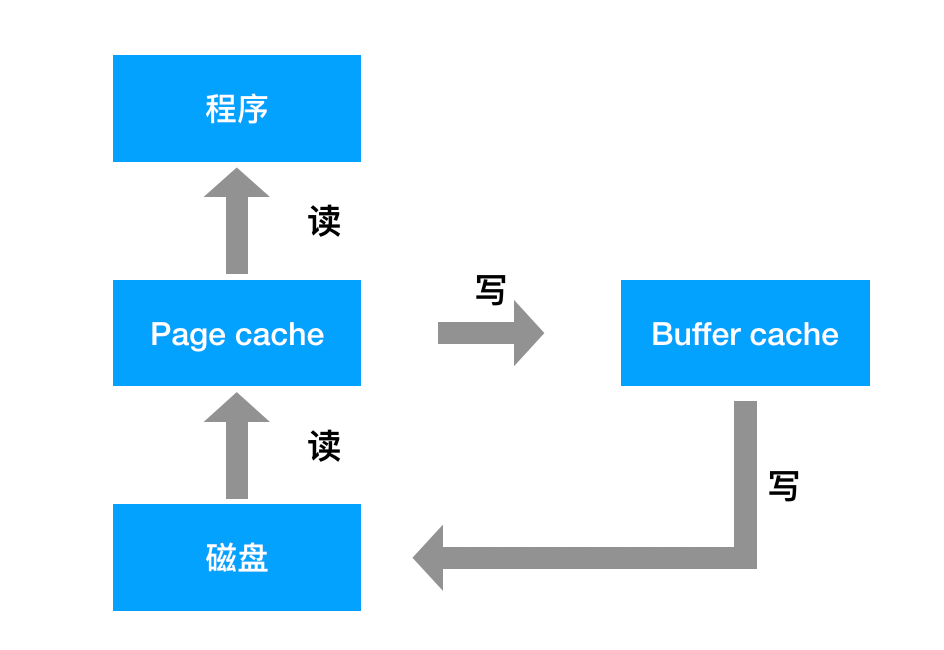
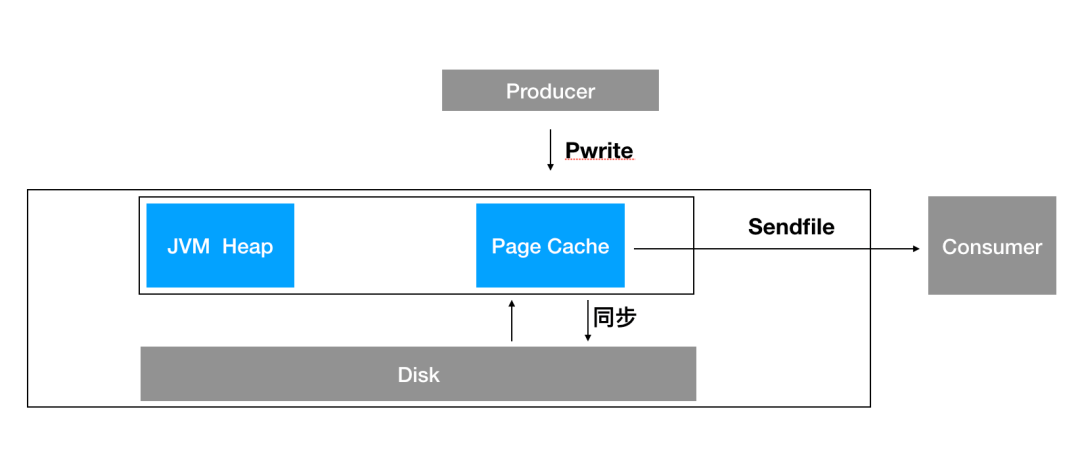
太阳底下无新鲜事,对于一个框架来说,要想运行的更快,通常能用的手段也就那么几招,Kafka 在将这一招用到了极致。 其中之一就是极大化的使用了 OS 的 Cache,主要是 Page Cache 和 Buffer Cache。对于这两个 Cache,使用 Linux 的同学通常不会陌生,例如我们在 Linux 下执行 free 命令的时候会看到如下的输出:

buffers 列表示当前的块缓存(buffer cache)占用量,buffer cache 用于缓存块设备(如磁盘)的块数据。块是物理上的概念,因此 buffer cache 是与块设备驱动程序同级的。
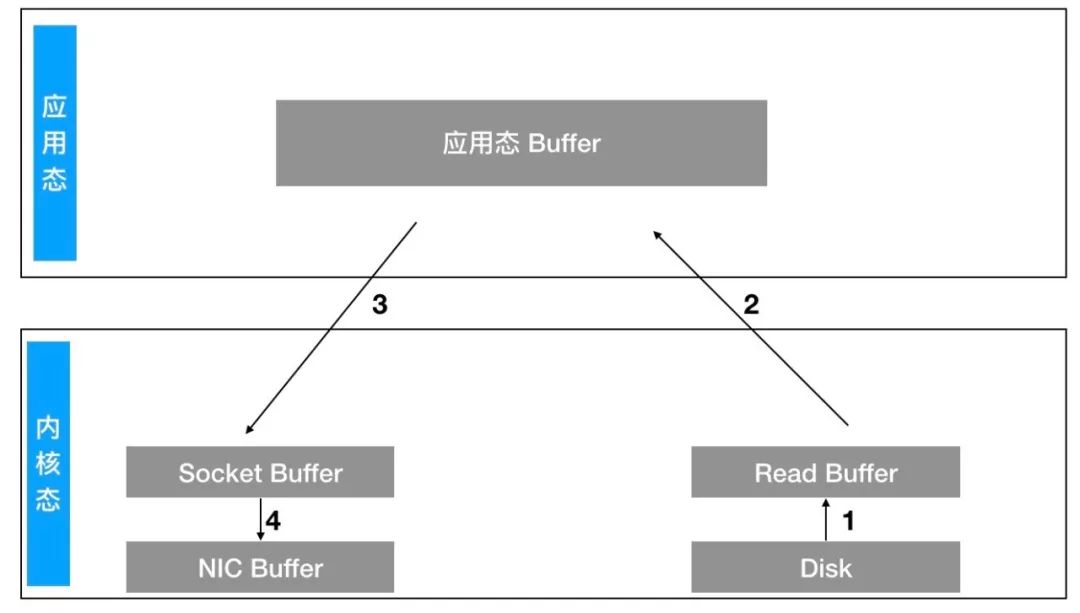
操作系统将数据从磁盘拷贝到内核区的 Page Cache。
用户程序将内核区的 Page Cache 拷贝到用户区缓存。
用户程序将用户区的缓存拷贝到 Socket 缓存中。
操作系统将 Socket 缓存中的数据拷贝到网卡的 Buffer 上,发送数据。
也就是省去第二和第三步骤,变成这样:
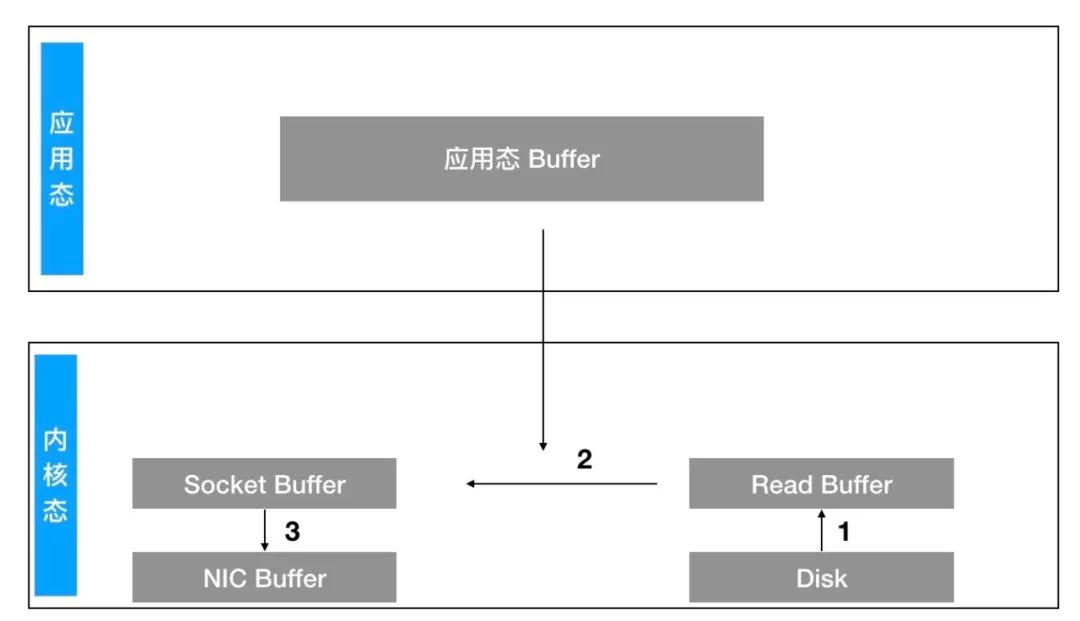
JVM 中的一切皆对象,所以无论对象的大小,总会有些额外的 JVM 的对象元数据浪费空间。
JVM 自己的 GC 不受程序手动控制,所以如果使用 JVM 作为缓存,在遇到大对象或者频繁 GC 的时候会降低整个系统的吞吐量。
程序异常退出或者重启,所有的缓存都将失效,在容灾架构下会影响快速恢复。而 Page Cache 因为是 OS 的 Cache,即便程序退出,缓存依旧存在。
用一张图来简述三者之间的关系如下:
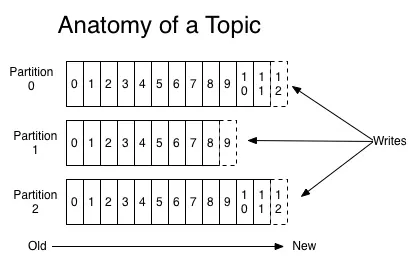
追加顺序写入
除了前面的重要特性之外,Kafka 还有一个设计,就是对数据的持久化存储采用的顺序的追加写入,Kafka 在将消息落到各个 Topic 的 Partition 文件时,只是顺序追加,充分的利用了磁盘顺序访问快的特性。
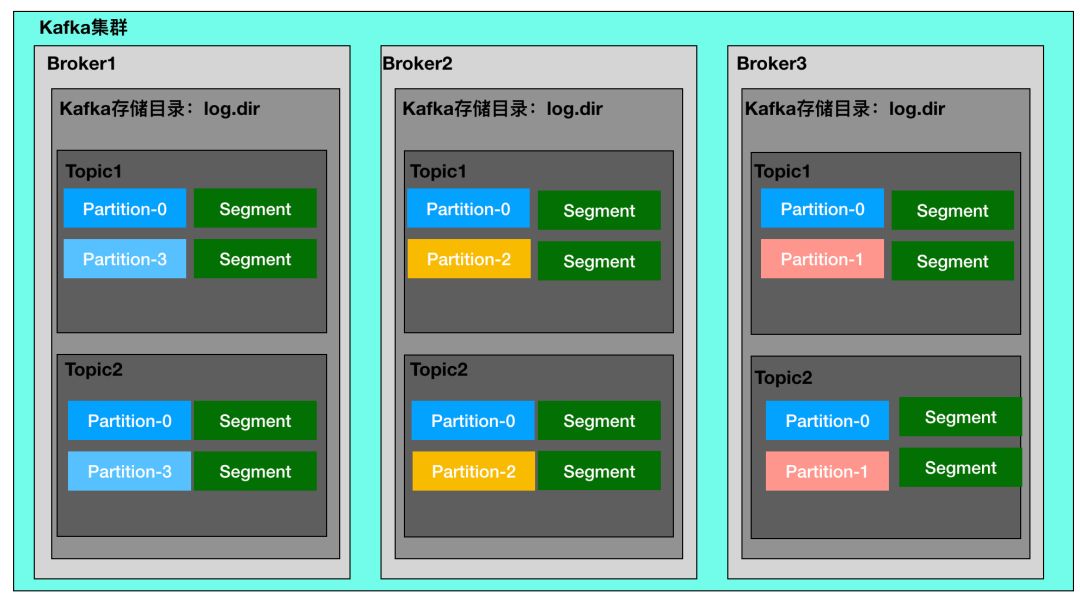
Broker:Kafka 中用来处理消息的服务器,也是 Kafka 集群的一个节点,多个节点形成一个 Kafka 集群。
Topic:一个消息主题,每一个业务系统或者 Consumer 需要订阅一个或者多个主题来获取消息,Producer 需要明确发生消息对于的 Topic,等于信息传递的口令名称。
Partition:一个 Topic 会拆分成多个 Partition 落地到磁盘,在 Kafka 配置的存储目录下按照对应的分区 ID 创建的文件夹进行文件的存储,磁盘可以见的最大的存储单元。
Segment:一个 Partition 会有多个 Segment 文件来实际存储内容。
Offset:每一个 Partition 有自己的独立的序列编号,作用域仅在当前的 Partition 之下,用来对对应的文件内容进行读取操作。
Leader:每一个 Topic 需要有一个 Leader 来负责该 Topic 的信息的写入,数据一致性的维护。
- Controller:每一个 Kafka 集群会选择出一个 Broker 来充当 Controller,负责决策每一个 Topic 的 Leader 是谁,监听集群 Broker 信息的变化,维持集群状态的健康。
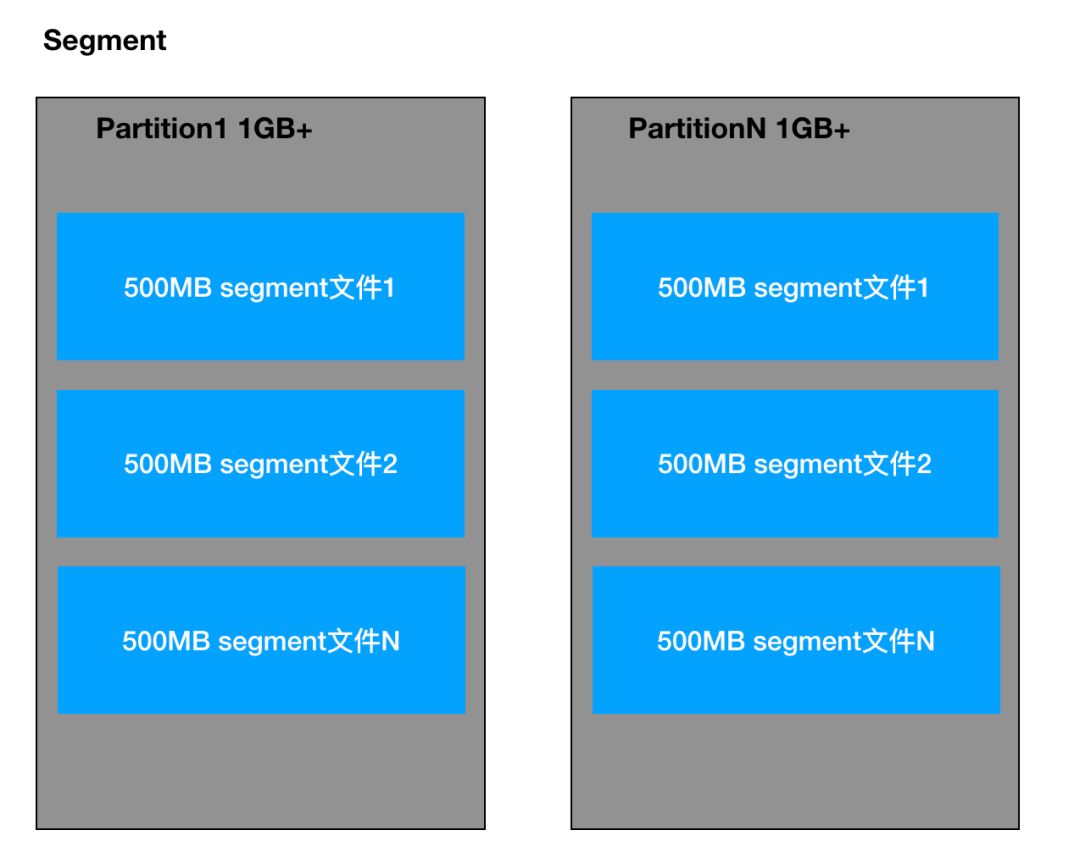
Segment 的文件由 index file 和 data file 组成,落地在磁盘的后缀为 .index 和 .log,文件按照序列编号生成,如下所示:

Kafka 为什么稳
前面提到 Kafka 为什么快,除了快的特性之外,Kafka 还有其他特点,那就是:稳。 Kafka 的稳体现在几个维度:数据安全,几乎不会丢数据。
集群安全,发生故障几乎可以 Consumer 无感知切换。
可用性强,即便部分 Partition 不可用,剩余的 Partition 的数据依旧不影响读取。
流控限制,避免大量 Consumer 拖垮服务器的带宽。
限流机制
对于 Kafka 的稳,通常是由其整体架构设计决定,很多优秀的特性结合在一起,就更加的优秀,像 Kafka 的 Qutota 就是其中一个。 既然是限流,那就意味着需要控制 Consumer 或者 Producer 的流量带宽,通常限制流量这件事需要在网卡上作处理,像常见的 N 路交换机或者高端路由器。 所以对于 Kafka 来说,想要操控 OS 的网卡去控制流量显然具有非常高的难度,因此 Kafka 采用了另外一个特别的思路。 即:没有办法控制网卡通过的流量大小,就控制返回数据的时间。对于 JVM 程序来说,就是一个 Wait 或者 Seelp 的事情。 所以对于 Kafka 来说,有一套特殊的时延计算规则,Kafka 按照一个窗口来统计单位时间传输的流量。 当流量大小超过设置的阈值的时候,触发流量控制,将当前请求丢入 Kafka 的 Qutota Manager,等到延迟时间到达后,再次返回数据。我们通过 Kafka 的 ClientQutotaManager 类中的方法来看:
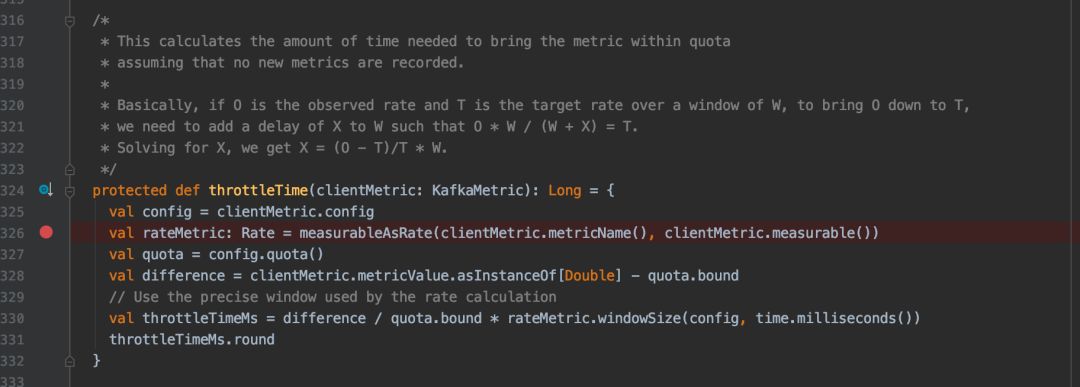
如果 O 超过了 T,那么会进行限速,限速的公示为:
X = (O - T)/ T * W
通过 KafkaApis 里面对 Producer 和 Consumer 的 call back 代码可以看到对限流的延迟返回:
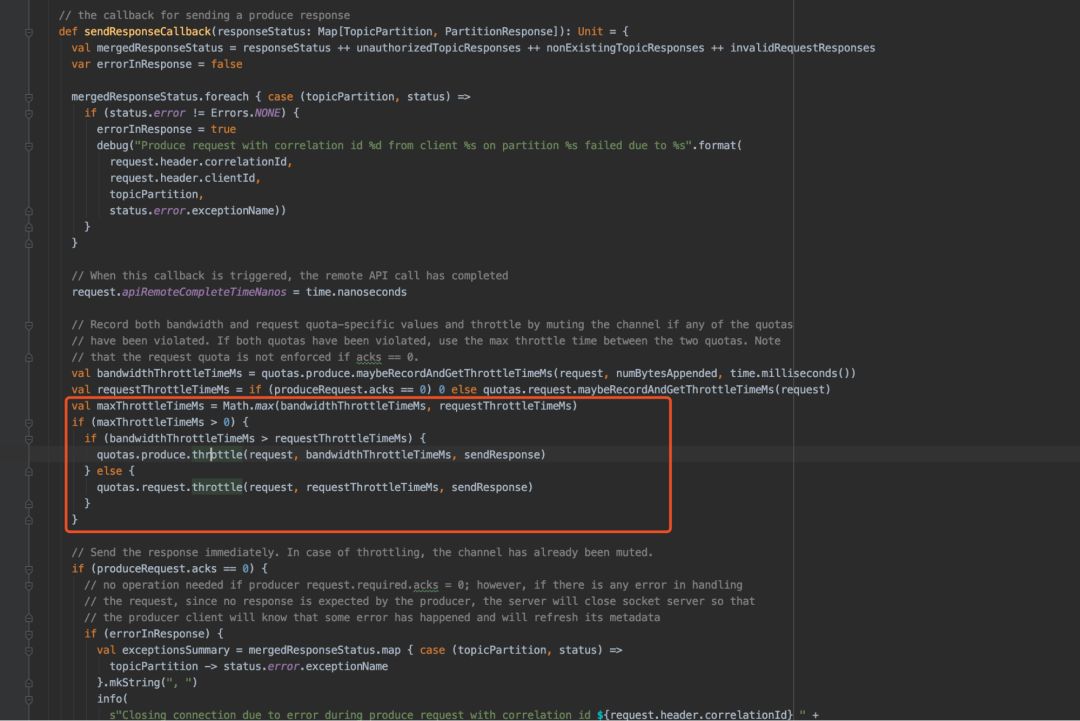
竞选机制
Kafka 背后的元信息重度依赖 Zookeeper,再次我们不解释 Zookeeper 本身,而是关注 Kafka 到底是如何使用 ZK 的。首先一张图解释 Kafka 对 ZK 的重度依赖:
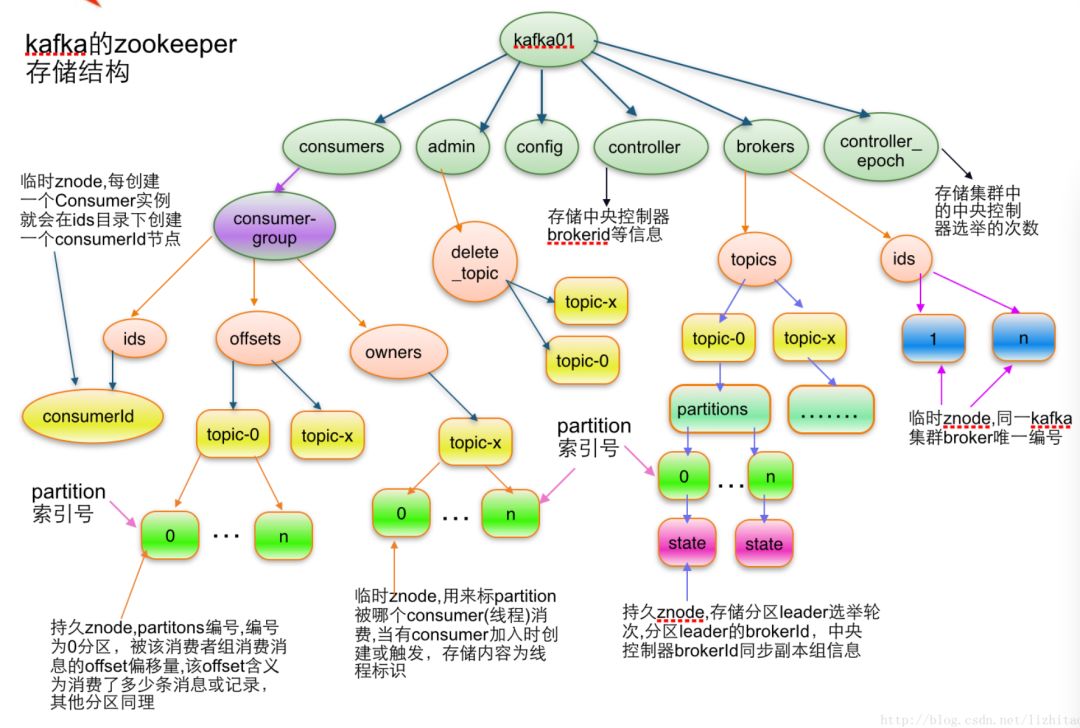
首先 Controller 作为 Kafka 的心脏,主要负责着包括不限于以下重要事项:

其代码直接通过 KafkaController 可以看到:
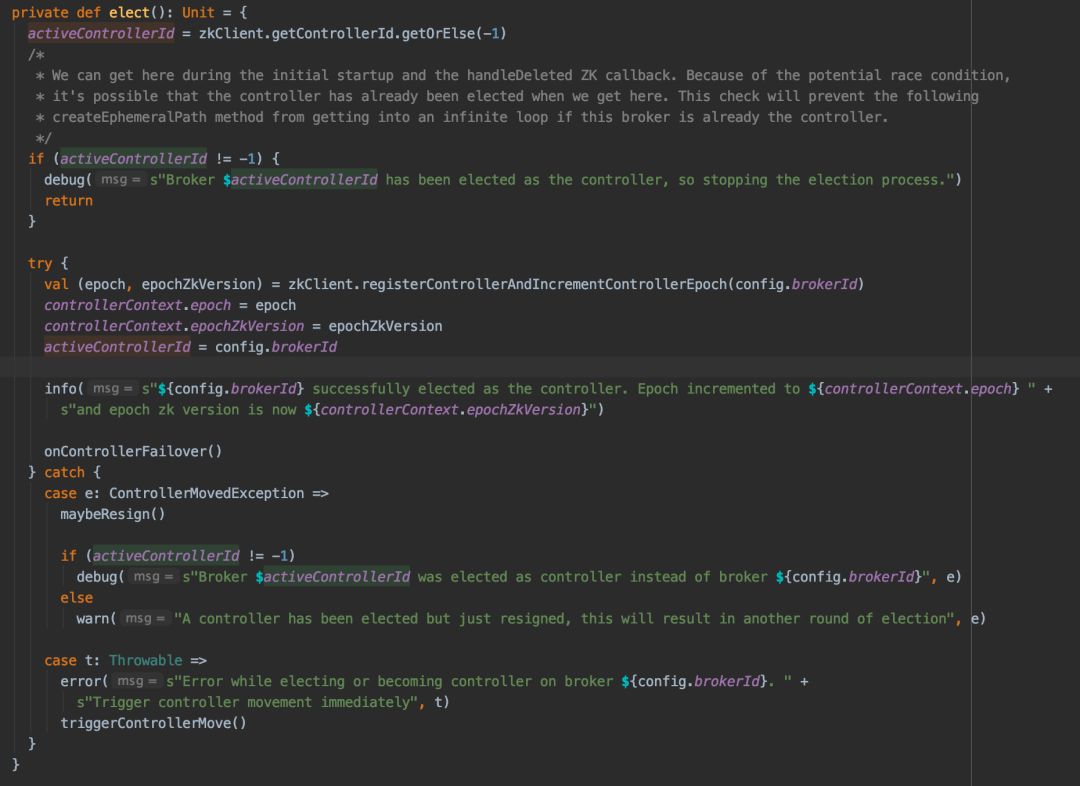
一旦 Controller 选举出来之后,则其他 Broker 会监听 ZK 的变化,来响应集群中 Controller 挂掉的情况:

Kafka 该怎么用
虽然 Kafka 整体看起来非常优秀,但是 Kafka 也不是全能的银弹,必然有其对应的短板,那么对于 Kafka 如何,或者如何能用的更好,则需要经过实际的实践才能得感悟的出。 经过归纳和总结,能够发现以下不同的使用场景和特点:①Kafka 并不合适高频交易系统
Kafka 虽然具有非常高的吞吐量和性能,但是不可否认,Kafka 在单条消息的低延迟方面依旧不如传统 MQ,毕竟依托推模型的 MQ 能够在实时消息发送的场景下取得先天的优势。
②Kafka 并不具备完善的事务机制
0.11 之后 Kafka 新增了事务机制,可以保障 Producer 的批量提交,为了保障不会读取到脏数据,Consumer 可以通过对消息状态的过滤过滤掉不合适的数据,但是依旧保留了读取所有数据的操作。
即便如此,Kafka 的事务机制依旧不完备,背后主要的原因是 Kafka 对 Client 并不感冒,所以不会统一所有的通用协议,因此在类似仅且被消费一次等场景下,效果非常依赖于客户端的实现。
③Kafka 的异地容灾方案非常复杂
对于 Kafka 来说,如果要实现跨机房的无感知切换,就需要支持跨集群的代理。
因为 Kafka 特殊的 append log 的设计机制,导致同样的 Offset 在不同的 Broker 和不同的内容上无法复用。
也就是文件一旦被拷贝到另外一台服务器上,将不可读取,相比类似基于数据库的 MQ,很难实现数据的跨集群同步。
同时对于 Offset 的复现也非常难,曾经帮助客户实现了一套跨机房的 Kafka 集群 Proxy,投入了非常大的成本。
④Kafka Controller 架构无法充分利用集群资源
Kafka Controller 类似于 ES 的去中心化思想,按照竞选规则从集群中选择一台服务器作为 Controller。
意味着改服务器即承担着 Controller 的职责,同时又承担着 Broker 的职责,导致在海量消息的压迫下,该服务器的资源很容易成为集群的瓶颈,导致集群资源无法最大化。
Controller 虽然支持 HA 但是并不支持分布式,也就意味着如果要想 Kafka 的性能最优,每一台服务器至少都需要达到最高配置。
⑤Kafka 不具备非常智能的分区均衡能力
通常在设计落地存储的时候,对于热点或者要求性能足够高的场景下,会是 SSD 和 HD 的结合。
同时如果集群存在磁盘容量大小不均等的情况,对于 Kafka 来说会有非常严重的问题,Kafka 的分区产生是按照 Paratition 的个数进行统计,将新的分区创建在个数最少的磁盘上,见下图: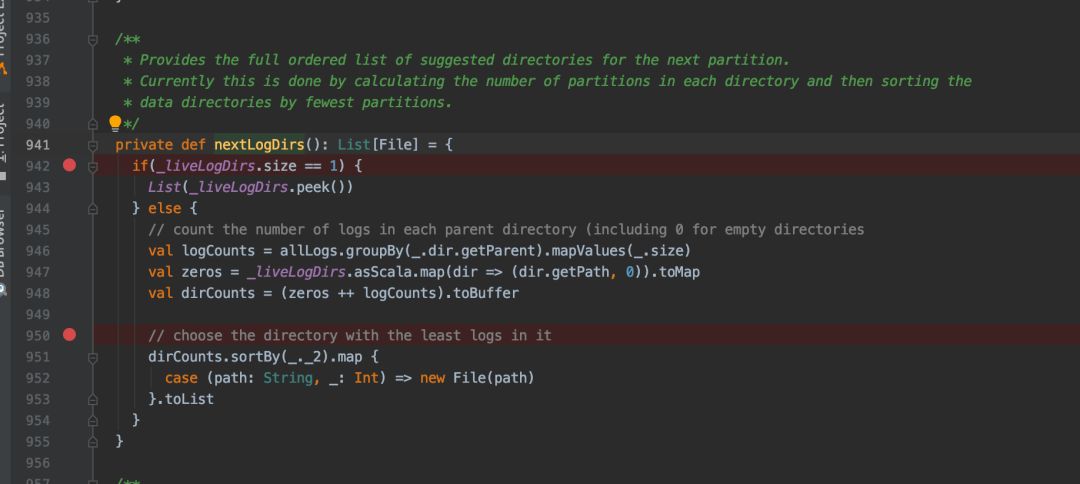 曾经我帮助某企业修改了分区创建规则,考虑了容量的情况,也就是按照磁盘容量进行分区的选择。
紧接着带来第二个问题:容量大的磁盘具备更多的分区,则会导致大量的 IO 都压向该盘,最后问题又落回 IO,会影响该磁盘的其他 Topic 的性能。
所以在考虑 MQ 系统的时候,需要合理的手动设置 Kafka 的分区规则。
曾经我帮助某企业修改了分区创建规则,考虑了容量的情况,也就是按照磁盘容量进行分区的选择。
紧接着带来第二个问题:容量大的磁盘具备更多的分区,则会导致大量的 IO 都压向该盘,最后问题又落回 IO,会影响该磁盘的其他 Topic 的性能。
所以在考虑 MQ 系统的时候,需要合理的手动设置 Kafka 的分区规则。
结尾
Kafka 并不是唯一的解决方案,像几年前新生势头挺厉害的 Pulsar,以取代 Kafka 的口号冲入市场,也许会成为下一个解决 Kafka 部分痛点的框架,下文再讲述 Pulsar。作者:白发川
编辑:陶家龙
出处:转载自微信公众号 ThoughtWorks 洞见(ID:TW-Insight)

精彩文章推荐:
注意了!Kafka与RabbitMQ千万不要乱用… 一口气说出Kafka为啥这么快? Kafka架构原理,也就这么回事!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









