





 本文介绍了COCO数据集的格式及应用,包括图像id、标注id、类别id的概念,如何利用pycocotools加载数据,并展示了通过图像id获取标签id的方法。
本文介绍了COCO数据集的格式及应用,包括图像id、标注id、类别id的概念,如何利用pycocotools加载数据,并展示了通过图像id获取标签id的方法。
COCO数据集格式
COCO的全称是Objects in Context,是微软推出的数据集,用于进行物体检测、分割、关键点检测、添加字幕等。

数据的标注通过字典进行组织,保存在json文件中,json文件最主题的结构如下:
{
文件只包含5个字段:
info 和 licenses 并不重要,下面介绍剩下三个字段。
- images 字段
{
上面比较重要的字段为 file_name 用于读取图片,id表示图像的id。
- annotations 字段
{
"id": int,
"image_id": int,
"category_id": int,
"segmentation": RLE or [polygon],
"area": float,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1
}上述字段中 segmentation 表示分割,用多边形顶点(iscrowd为0)或者mask编码(iscrowd为1)后表示。
bbox表示目标的框。
image_id 与 category_id 对应了标记所述的图像和类别。
- categories 字段
{
"id": int,
"name": str,
"supercategory": str,
}以上为目标检测和分割的标记,COCO数据集还提供关键点检测、image caption的标记,具体格式可以参见:
COCO 标注详解_911的专栏-优快云博客blog.youkuaiyun.com
pycocotools
通过观察可以发现,COCO数据集中包含三种id:图像id、标注id、类别id,解析COCO数据的关键就是可以通过一种id,找到和该id相关的其他数据,例如通过图像id找到该图像的标注。
在windows安装pycocotools可以使用以下的命令:
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
下面通过使用Mnist合成的目标检测数据集,展示该工具的原理。
加载标注数据
from 读取数据的id
imgIds = coco.getImgIds() # 获取所有的image id,可以选择参数 coco.getImgIds(imgIds=[], catIds=[])
imgIds = coco.getImgIds(imgIds=[0, 1, 2]) # 获得image id 为 0,1,2的图像的id
imgIds = coco.getImgIds(catIds=[0, 1, 2]) # 获得包含类别 id 为0,1,2的图像
annIds = coco.getAnnIds(catIds=[0, 1, 2]) # 获得类别id为0,1,2的标签
annIds = coco.getAnnIds(imgIds=imgIds[0]) # 获得和image id对应的标签
catIds = coco.getCatIds(catNms=['0']) # 通过类别名筛选
catIds = coco.getCatIds(catIds=[0, 1, 2]) # 通过id筛选
catIds = coco.getCatIds(supNms=[]) # 通过父类的名筛选通过id加载对应的数据(类别、标签、图像)
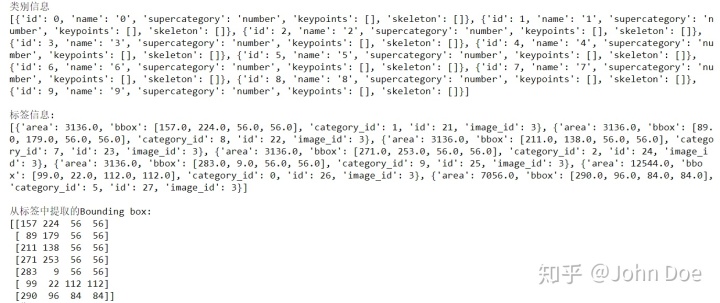
print('类别信息')
cats_name = coco.loadCats(ids=catIds)
print(cats_name)
print('n标签信息:')
anns = coco.loadAnns(annIds)
bboxes = np.array([i['bbox'] for i in anns]).astype(np.int32)
cats = np.array([i['category_id'] for i in anns])
print(anns)
print('n从标签中提取的Bounding box:')
print(bboxes)
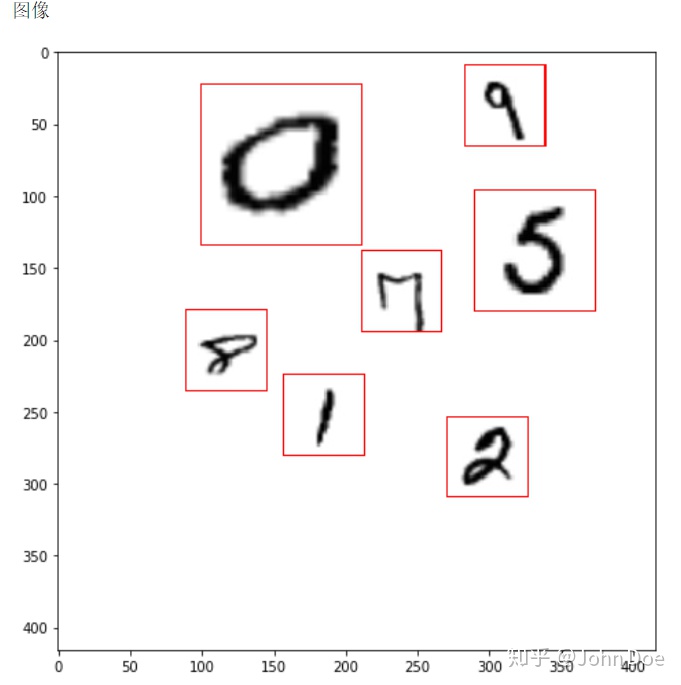
print('图像')
imgIdx = imgIds[0]
img = coco.loadImgs([imgIdx]) # 读取图片信息
img = cv.imread('./train/' + img[0]['file_name'])
# 绘制bounding box
for i in range(len(bboxes)):
p1 = bboxes[i][0:2]
p2 = bboxes[i][0:2] + bboxes[i][2:4]
cv.rectangle(img, (p1[0], p1[1]), (p2[0], p2[1]), (255, 0, 0))
plt.figure(figsize=(8, 8))
plt.imshow(img)
plt.show()加载的数据如下图所示:
总结来说使用coco加载数据步骤如下:
获得图像id,通过图像id获得图像对应标签的id,加载图像和对应标签,就可以作为网络的输入进行训练了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









