




 MoE(Mixture-of-Experts)通过引入稀疏门机制,实现大模型容量提升,降低计算成本。文章探讨了MoE的动机、难点、模型结构、批缩小问题、均衡问题及实验结果,指出MoE在处理大规模数据时能有效提高效率并保持良好性能。
MoE(Mixture-of-Experts)通过引入稀疏门机制,实现大模型容量提升,降低计算成本。文章探讨了MoE的动机、难点、模型结构、批缩小问题、均衡问题及实验结果,指出MoE在处理大规模数据时能有效提高效率并保持良好性能。
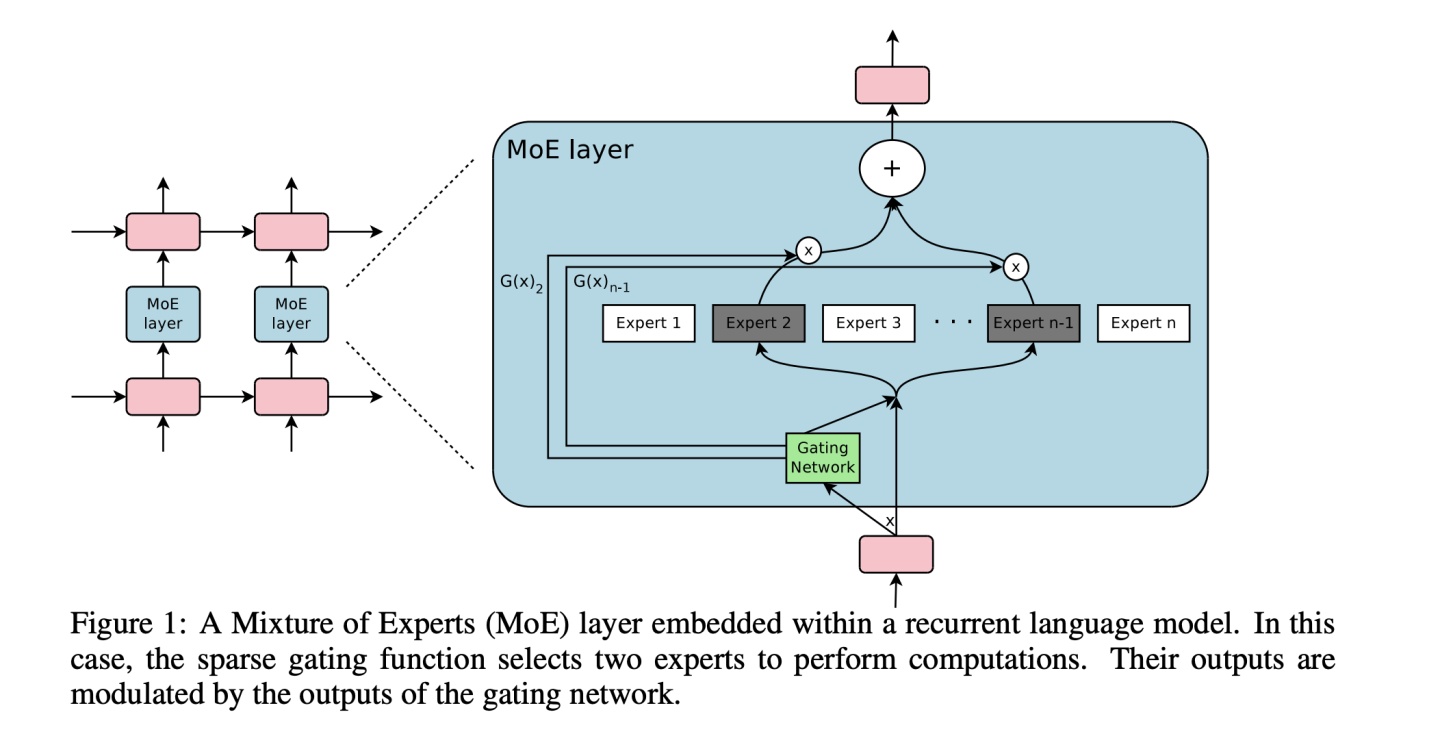
Moe,是Mixture-Of-Experts的缩写,可以在保证运算速度的情况下,将模型的容量提升>1000倍。
动机
现在的模型越来越大,训练样本越来越多,每个样本都需要经过模型的全部计算,这就导致了训练成本的平方级增长。
为了解决这个问题,参考文献[1]提出了一种方式,即将大模型拆分成多个小模型,对于一个样本来说,无需经过所有的小模型去计算,而只是激活一部分小模型进行计算,这样就节省了计算资源。
那么如何决定一个样本去经过哪些小模型呢?这就引入了一个稀疏门机制,即样本输入给这个门,得到要激活的小模型索引,这个门需要确保稀疏性,从而保证计算能力的优化。
难点
听起来这个方法其实还是很直接的,那么为什么之前没有人做呢?主要因为以下几点:
- 现在的设备,比如GPU,比较擅长做运算,不擅长做分支。
- 大批量是训练模型的必须,但是这种方式下会导致每个小模型的样本数较少,无法训练得到好的模型
- 网络通信是瓶颈。
- 为了控制稀疏性,可能需要在loss上去做些改进,确保模型质量和小模型上的负载均衡
- 模型容量对大数据集比较重要,现有的工作都是在类似cifar10之类的数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









