



|
- ArrayList和HashMap是异步的, Vector和HashTable是同步的<同步集合类>。
- 同步包装类Collections.synchronizedMap()和Collections.synchronizedList()提供了一个基本的有条件的线程安全的Map和List实现。Map<String, Object> map = Collections.synchronizedMap(new HashMap<String, Object>());
java.util.concurrent包中
- 包含的并发集合类如下:
ConcurrentHashMap
CopyOnWriteArrayList
CopyOnWriteArraySet
- 虽然Set同List都实现了Collection接口,但是他们的实现方式却大不一样。List基本上都是以Array为基础。但是Set则是在 HashMap的基础上来实现的,这个就是Set和List的根本区别。
- ArrayList类 初始长度10 1.5倍速度 ; HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数
- Collections类提供了丰富的静态方法:
binarySearch:折半查找。
sort:排序,这里是一种类似于快速排序的方法,效率仍然是O(n * log n),但却是一种稳定的排序方法。
灵活使用sort的例子 : java的list集合如何根据对象中的某个字段排序
Collections.sort(list, new Comparator<String>(){
public int compare(String o1, String o2) {
return o1.length()-o2.length();
}});
/*
Collection提供了一个重载的sort方法,可以允许传入一个额外的比较器
按照该比较器的规则对元素比较大小后进行排序。
*/reverse:将线性表进行逆序操作,这个可是从前数据结构的经典考题哦!
rotate:以某个元素为轴心将线性表“旋转”。
swap:交换一个线性表中两个元素的位置。
- Collections还有一个重要功能就是“封装器”(Wrapper),它提供了一些方法可以把一个集合转换成一个特殊的集合,如下:
unmodifiableXXX:转换成只读集合,这里XXX代表六种基本集合接口:Collection、List、Map、Set、 SortedMap和SortedSet。如果你对只读集合进行插入删除操作,将会抛出UnsupportedOperationException异常。
synchronizedXXX:转换成同步集合。
singleton:创建一个仅有一个元素的集合,这里singleton生成的是单元素Set,
singletonList和singletonMap分别生成单元素的List和Map。
- 空集:由Collections的静态属性EMPTY_SET、EMPTY_LIST和EMPTY_MAP表示。
CopyOnWriteArrayList使用了一种叫写时复制的方法,当有新元素添加到CopyOnWriteArrayList时,先从原有的数组中拷贝一份出来,然后在新的数组做写操作,写完之后,再将原来的数组引用指向到新数组。CopyOnWriteArrayList的整个add操作都是在锁的保护下进行的。
这样做是为了避免在多线程并发add的时候,复制出多个副本出来,把数据搞乱了,导致最终的数组数据不是我们期望的。由于所有的写操作都是在新数组进行的,这个时候如果有线程并发的写,则通过锁来控制,如果有线程并发的读,则分几种情况:
1、如果写操作未完成,那么直接读取原数组的数据;
2、如果写操作完成,但是引用还未指向新数组,那么也是读取原数组数据;
3、如果写操作完成,并且引用已经指向了新的数组,那么直接从新数组中读取数据。可见,CopyOnWriteArrayList的读操作是可以不用加锁的。
-
通过上面的分析,CopyOnWriteArrayList 有几个缺点:
1、由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致young gc或者full gc2、不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个set操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求;CopyOnWriteArrayList 合适读多写少的场景,不过这类慎用 , 因为谁也没法保证CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点多,每次add/set都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
CopyOnWriteArrayList透露的思想
如上面的分析CopyOnWriteArrayList表达的一些思想:
1、读写分离,读和写分开
2、最终一致性3、使用另外开辟空间的思路,来解决并发冲突
参考 : https://blog.youkuaiyun.com/u012117503/article/details/43373905/
| Collection Collection . .....List. ..........ArrayList ...............Stack ..........LinkedList. .....Set . ..........HashSet ...............LinkedHashSet ..........SortedSet ...............TreeSet . ----------------------------------- ..........ListIterator. ----------------------------------- Map .....Hashtable. ..........Properties .....HashMap ...............LinkedHashMap .....WeakHashMap .. .....SortedMap. ...............TreeMap . |
map数据结构
asList返回的是Arrays下的ArrayList 并不是Util下的ArrayList
参考 https://yq.aliyun.com/articles/620316 Java集合类: Set、List、Map、Queue使用场景梳理
参考 https://blog.youkuaiyun.com/xzp_12345/article/details/79251174 List、set、Map的底层实现原理
hashset与hashtable的区别
1.hashset用来做高性能集运算的,例如对两个集合求交集、并集、差集等。集合中包含一组不重复出现且无特性顺序的元素,HashSet拒绝接受重复的对象。
2. hashtable用于处理和表现类似key-value的键值对,其中key通常可用来快速查找,同时key是区分大小写;value用于存储对应于key的值。
Hashtable在底层采用Entry[]数组来保存所有的key-value对儿。 HashTable采用"拉链法"实现哈希表
| 1.HashMap可以允许存在一个为null的key和任意个为null的value,但是HashTable中的key和value都不允许为null。如下: 当HashMap遇到为null的key时,它会调用putForNullKey方法来进行处理。对于value没有进行任何处理,只要是对象都可以。 2.Hashtable的方法是同步的,而HashMap的方法不是。所以有人一般都建议如果是涉及到多线程同步时采用HashTable,没有涉及就采用HashMap。 3.HashTable有一个contains(Object value),功能和containsValue(Object value)功能一样。 4.两个遍历方式的内部实现上不同。 Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。 5.哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。代码是这样的: 6.Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数 |
HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
与HashMap不同的是,ConcurrentHashMap使用多个子Hash表,也就是段(Segment)
对于HashSet中保存的对象,请注意正确重写其equals和hashCode方法,以保证放入的对象的唯一性。
现有一个字符串,String=“asdasdsafsa”,求单个字符出现多少次(map集合作答)
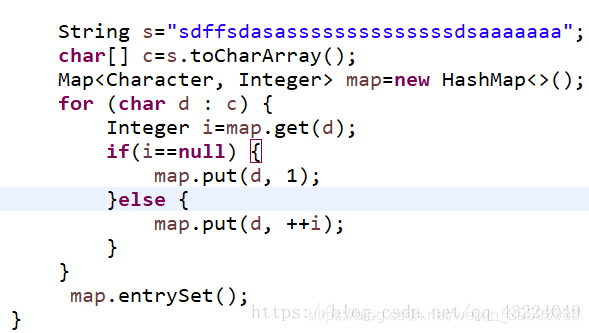
Set entrySet=map.entrySet();//entrySet()方法返回反应map键值的映射关系,存储在set集合中
.entrySet()
Map map=new HashMap();
Iterator it=map.entrySet().iterator();
Object key;Object value;while(it.hasNext()){
Map.Entry entry = (Map.Entry)it.next();
key=entry.getKey();
value=entry.getValue();
System.out.println(key+"="+value);
}
参考 https://blog.youkuaiyun.com/qq_27093465/article/details/52207152 1.7可能还早的hashmap底层原理
ConcurrentHashMap原理分析以及线程安全性问题
https://blog.youkuaiyun.com/jjc120074203/article/details/78625433 ;
同步的集合类还有hashtable vector 封装类collection synchronizedmap 他们仅有单个锁,对整个集合(map)加锁
currentHashmap保留线程安全的同时,也提供了更高的并发性, 引入了分割(segmentation)不论他多大,仅需要锁定map的某个部分,而其他线程不需要等迭代完成才能访问map,这就是锁分段技术,ConcurrentHashMap 使用segment来分段和管理锁,segment继承自ReentrantLock,因此ConcurrentHashMap使用ReentrantLock来保证线程安全
| *** 首先对key.hashCode进行hash操作,基于其值找到对应的Segment对象,调用其get方法完成当前操作。而Segment的get操作首先通过hash值和对象数组大小减1的值进行按位与操作来获取数组上对应位置的HashEntry。在这个步骤中,可能会因为对象数组大小的改变,以及数组上对应位置的HashEntry产生不一致性,那么ConcurrentHashMap是如何保证的? 对象数组大小的改变只有在put操作时有可能发生,由于HashEntry对象数组对应的变量是volatile类型的,因此可以保证如HashEntry对象数组大小发生改变,读操作可看到最新的对象数组大小。 在获取到了HashEntry对象后,怎么能保证它及其next属性构成的链表上的对象不会改变呢?这点ConcurrentHashMap采用了一个简单的方式,即HashEntry对象中的hash、key、next属性都是final的,这也就意味着没办法插入一个HashEntry对象到基于next属性构成的链表中间或末尾。这样就可以保证当获取到HashEntry对象后,其基于next属性构建的链表是不会发生变化的。 ConcurrentHashMap默认情况下采用将数据分为16个段进行存储,并且16个段分别持有各自不同的锁Segment,锁仅用于put和remove等改变集合对象的操作,基于volatile及HashEntry链表的不变性实现了读取的不加锁。这些方式使得ConcurrentHashMap能够保持极好的并发支持,尤其是对于读取比插入和删除频繁的Map而言,而它采用的这些方法也可谓是对于Java内存模型、并发机制深刻掌握的体现。 |
list数据结构
元素都对应一个整形序号标明在容器的位置,可以通过序号进行查询,与数组的区别是list集合的长度可以变化(Arraylist也是大小可变 顺序存储)
ArrayList类 初始长度10 1.5倍速度增长<10->16->25->38->58->88->...> linkedlist 访问效率O(n/2)
map hashmap底层entry数组(哈希桶)每个元素指向一个单向链表,访问O(1), 初始长度16 扩容2倍速度 扩容因子0.75
*linkedlist拥有的方法:
增加:
add(E e):在链表后添加一个元素; 通用方法
add(int index, E element):在指定位置插入一个元素。
addFirst(E e):在链表头部插入一个元素; 特有方法
addLast(E e):在链表尾部添加一个元素; 特有方法
push(E e):与addFirst方法一致
offer(E e):在链表尾部插入一个元素
offerFirst(E e):JDK1.6版本之后,在头部添加; 特有方法
offerLast(E e):JDK1.6版本之后,在尾部添加; 特有方法
删除:
remove() :移除链表中第一个元素; 通用方法
remove(E e):移除指定元素; 通用方法 strList.remove(string)
removeFirst(E e):删除头,获取元素并删除; 特有方法
removeLast(E e):删除尾; 特有方法
pollFirst():删除头; 特有方法
pollLast():删除尾; 特有方法
pop():和removeFirst方法一致,删除头。
poll():查询并移除第一个元素 特有方法
查:
get(int index):按照下标获取元素; 通用方法
getFirst():获取第一个元素; 特有方法
getLast():获取最后一个元素; 特有方法
peek():获取第一个元素,但是不移除; 特有方法
peekFirst():获取第一个元素,但是不移除;
peekLast():获取最后一个元素,但是不移除;
pollFirst():查询并删除头; 特有方法
pollLast():删除尾; 特有方法
poll():查询并移除第一个元素 特有方法
**迭代器(Iterator)指向的位置是元素之前的位置。
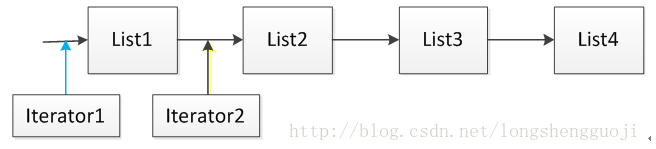
当使用语句Iterator it=List.Iterator()时,迭代器it指向的位置是Iterator1指向的位置,当执行语句it.next()之后,迭代器指向的位置后移到Iterator2指向的位置。
迭代器的remove应用
while(iterator.hasnext()){
iteratot.next();
if(){
iterator.remove();
}}
**数组转换为list方法:
-
String[] str = new String[]{"AA", "BB", "CC"};
-
List list = Arrays.asList(str);
首先,该方法是将数组转化为list。有以下几点需要注意:
(1)该方法不适用于基本数据类型(byte,short,int,long,float,double,boolean)-->那么 , 循环添加至链表
(2)该方法将数组与列表链接起来,当更新其中之一时,另一个自动更新
(3)不支持add和remove方法
返回的是一个ArrayList,但是这个ArrayList不是ArrayList.class而是Arrays$ArrayList这样一个内部类
这个内部类中并没有实现list的一些方法,所以调用add(),remove()这些方法都会出现错误。
这个内部类中有一个泛型的数组private final E[] a,所以Arrays.asList返回的集合中的数组其实是有具体的类型的,而不是Object[]。
相当于List<String> list = new Arrays$ArrayList<String>();
// 如果想要返回可变列表,则需要将数组里的元素遍历加到List中
List list = new ArrayList();
if (arrays != null && arrays.length > 0) {
for (Object obj : arrays) {
list.add(obj);
}
}
return list;
ArrayList 继承了AbstractList,实现了List。它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
ArrayList 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
ArrayList 实现了Cloneable接口,即覆盖了函数clone(),能被克隆。
ArrayList 实现java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。
set数据结构
set中不允许数据重复,因此最多只能有一个null值 是无序的没有索引 因此很多list的方法都没有 例如:
get(i);
set(int index,Object o);
remove(int index);这些需要索引的方法都没有
常用set集合hashset--->且常用于去重 拥有的方法如下:
add(Object o);remove(Object o);contains(Object o);clear();size();
由于是乱序存储(输入的值求出hashcode(),计算出数组位置的下标, 使用的是hashmap的存储结构,add相当于添加一个键值对)无法通过索引进行遍历,需要通过迭代器
对应方法有
**数组转set
private static Set arraysToSet(Object[] arrays) { return new HashSet(Arrays.asList(arrays)); // 先转成list,再通过HashSet构造出Set }
**list转数组
private static Object[] listToArrays(List list) { return list.toArray(); }
** list转set
private static Set listToSet(List list) { return new HashSet(list); }
**set转List
private static List setToList(Set set) { return new ArrayList(set); }
***set 实现数组去重
public static void main(String[] args) {
int[] nums = { 5, 6, 6, 6, 8, 8, 7 };
List<Integer> numList = new ArrayList<Integer>();
for (int i : nums)
numList.add(i);//将数组元素存储到list集合中
Set<Integer> numSet = new HashSet<Integer>();
numSet.addAll(numList);//将list集合中的元素一次add到hashset中
System.out.println(numSet);
}
* 用hashset treeset 不仅实现去重而且重排
Integer[] nums = { 5, 5, 6, 6, 6, 8, 8, 7, 11, 12, 12 };
// HashSet hset = new HashSet(Arrays.asList(nums));https://www.cnblogs.com/vmax-tam/p/4074640.html HashSet 是没有提供get方法的,但是我们在使用Set的时候要获取对象,因此在HashSet中提供了 Iterator 来实现遍历
TreeSet<Integer> hset = new TreeSet<Integer>(Arrays.asList(nums));
Iterator i = hset.iterator();
while(i.hasNext()){
System.out.println(i.next());
}
使用TreeSet要求集合元素必须是可以比较大小的,保证Set里添加的元素后是“大小排序”的。
比较大小主要有两种方式:
A. 自然排序。所有集合元素要实现Comparable接口。
B. 定制排序。要求创建TreeSet时,提供一个Comparator对象(负责比较元素大小)。
HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相等
注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。其规则是如果两个对 象通过equals方法比较返回true时,其hashCode也应该相同。
***遍历 Collection 的几种方式:
for-each语法
Collection<Person> persons = new ArrayList<Person>();
for (Person person : persons) {
System.out.println(person.name);
}
1
2
3
4
使用 Iterator 迭代器
Collection<Person> persons = new ArrayList<Person>();
Iterator iterator = persons.iterator();
while (iterator.hasNext) {
System.out.println(iterator.next);
}
1
2
3
4
5
使用 aggregate operations 聚合操作
Collection<Person> persons = new ArrayList<Person>();
persons
.stream()
.forEach(new Consumer<Person>() {
@Override
public void accept(Person person) {
System.out.println(person.name);
}
});
参考:https://blog.youkuaiyun.com/u011240877/article/details/52773577
*String的方法 Java String charAt()方法
此方法返回位于字符串的指定索引处的字符。该字符串的索引从零开始。
*Arrays.sort() 数组排序 增序排序 参考 https://blog.youkuaiyun.com/github_38838414/article/details/80642329
减序排序 需要通过包装类 compartor
*Arrays.equals(ary, ary1) 判断两个数组是否相同 参考 https://www.cnblogs.com/borter/p/9613382.html
*STACK
| - push() - 在栈顶添加元素 - peek() - 返回栈顶的元素,但是不删除栈顶元素 - pop() - 和peek()一样返回栈顶元素,但是要将栈顶元素移除掉 - empty() - 检查栈是否为空 - search() - 返回元素在堆栈中的位置 |
*QUEUE
| offer,add区别: poll,remove区别: peek,element区别: |
ArrayDeque数据结构
提供的方法 参考 https://segmentfault.com/a/1190000017480142?utm_source=tag-newest
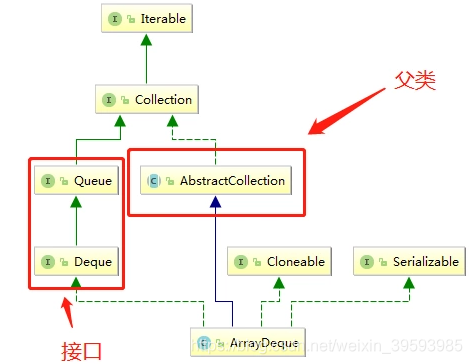
父类 (抽象类)
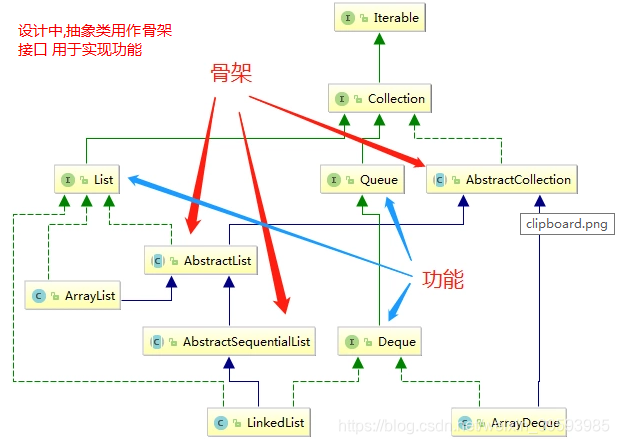
父类是AbstractCollection add、addAll、remove、clear、iterator、size……是你常用的xxList中,经常会看到这些方法 ; 可以说,AbstractCollection这个抽象类,是这种结构(数组、链表等等)的骨架!
接口 (接口)
首先是Queue接口,定义出了最基本的队列功能
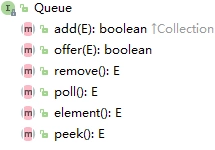
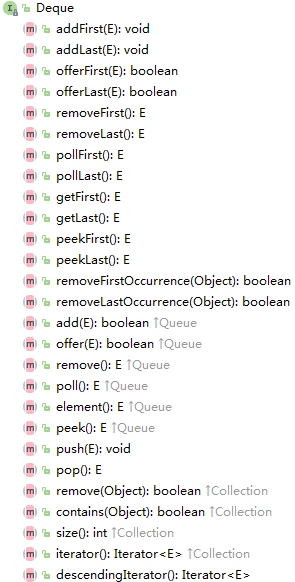
Deque接口
入眼各种xxFirst、xxLast,这种定义决定了它是双端队列的代表!
一个经典问题——抽象类和接口有什么区别?
你可能会有各种回答,比如抽象类能自己有自己的实现之类的。不能说不对,但这种答案相当于只停留在奇技淫巧层面,未得正统。以设计角度来看,其实是is-a(抽象类)和has-a(接口)的区别!
- 抽象类相当于某一个种族的基石
- 接口则关注各种功能
有些汽车多了座椅加热;有些增设了天窗打开功能。但这些功能都是增强型的,并不是每种汽车都会有!但定义汽车AbstractCar,会规定有轮子有发动机能跑的就是汽车 , 各家厂商生产的汽车都逃不出这个范畴;
抽象类和接口合理的组合,就产生了奇妙的效果:既能保证种族(类)的结构,又能对其进行扩展(接口)。
这种设计不仅仅限于Java Collection,开源框架中也是如此,比如Spring IOC中的Context、Factory那部分……
分析
回归到本文的主角 ArrayDeque,既然它实现了Deque,自然具备双端队列的特性。类名中的 Array姓氏,无时无刻不在提醒我们,它是基于数组实现的。
ArrayDeque作为队列时比LinkedList快,看看它是怎么办到的!
三大属性:
transient Object[] elements; //基于数组实现
transient int head; //头指针
transient int tail; //尾巴指针 ps:tail 不是尾部元素的索引,而是尾部元素的下一位,即下一个将要被加入的元素的索引。技术敏感的同学已经能猜到它是怎么实现的了:数组作为基底,两个指分指头尾,插入删除操作时移动指针 (当tail值超过数组索引后,就回到了索引为0的地方,实现了内存单元循环利用);如果头尾指针重合,则需要扩容(默认容量16)…… (ArrayDeque 没有容量限制,可根据需求自动进行扩容。ArrayDeque不支持值为 null 的元素。)
回到那个问题:作为队列时,ArrayDeque效率为什么会比LinkedList更好?
参考文章的博主认为因为LinkedList作为队列实现,新增修改要多修改节点的pre、next指针,且地址非连续,寻址时也会比array花更多时间。
参考 https://blog.youkuaiyun.com/ted_cs/article/details/82926423
参考 https://www.jianshu.com/p/132733115f95
相比ArrayList,我们可以看到ArrayDeque大量减少了System.arrayCopy的使用,只在delete、clone、扩容和toArray函数中使用了这个函数,其他操作中都不需要大量移动数组元素,这也可以说明ArrayDeque这个数据集合的性能非常优良。

















 171万+
171万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









