



 本文介绍如何在TensorFlow 2.0中加载Numpy格式数据,并将其用于模型训练和评估。通过numpy.load()函数从文件加载数据,利用tf.data.Dataset.from_tensor_slices()创建数据集,进而训练和测试模型。
本文介绍如何在TensorFlow 2.0中加载Numpy格式数据,并将其用于模型训练和评估。通过numpy.load()函数从文件加载数据,利用tf.data.Dataset.from_tensor_slices()创建数据集,进而训练和测试模型。
numpy是python中进行数值计算的基础库,numpy格式的数据也是python开发者常用的数据格式。使用这种格式存储的数据文件该怎样用于tensorflow的机器学习系统呢?本文就是讨论在tensorflow2.0中加载numpy数据,并使用该数据进行模型训练和评估。本文是参照tensorflow官网教程完成编写的,主要的代码逻辑与官网一致,感兴趣并且网速合适的朋友也可以直接阅读tensorflow官网的教程。本文所使用的数据可以从https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 下载。
1. 从文件载入numpy数据
numpy为npz格式的数据提供了载入接口,这里就是使用numpy.load()函数将数据从文件载入到内存。查看一下训练集和测试机数据及格式一致,样本数量符合预期。使用matplotlib可视化训练集的前6个样本数据,标记与图像是匹配的,因此从文件到内存的数据载入过程正确。
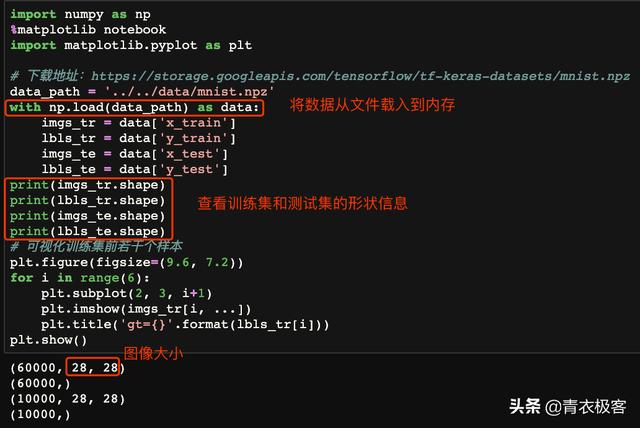
从文件载入到内存

训练集样本展示
2. 创建数据集
tensorflow提供了tf.data.Dataset.from_tensor_slices()函数将numpy格式的数据包装成Dataset,以便于后面的调用。对于训练集除指定batch size之外,还需要将样本随机排列。使用matplotlib可视化训练数据集的前几个样本,发现与上文中显示的不相同,说明随机排列设置生效。
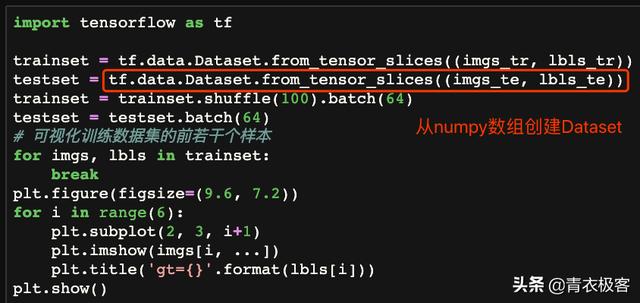
从bumpy数组到Dataset

随机排列的训练集样本展示
3. 训练模型及测试
数据集准备完成之后,就可以使用该数据集训练模型了。这里使用tensorflow中的keras子模块创建一个简单的神经网络,设置好优化器和损失函数之后就可以进行训练了。训练完成之后,在测试集上对该模型进行评估,所得到的正确率与训练过程基本一致,符合预期。
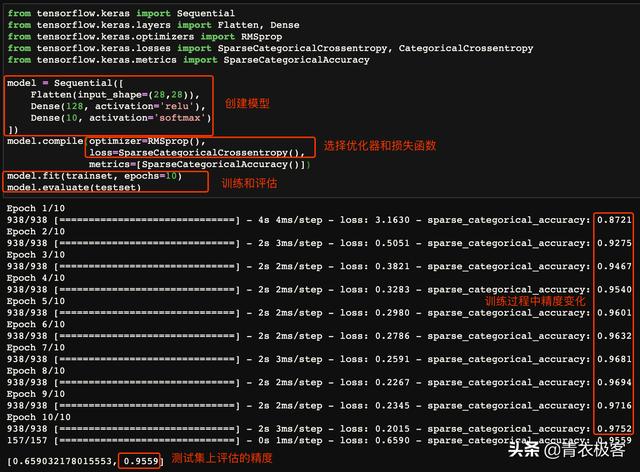
训练和评估模型
使用训练好的模型进行预测过程的测试。使用测试集的第一个batch作为模型的输入,对比模型输出与真实标签,发现绝大部分都预测正确,小部分预测错误,比例基本与评估显示的错误率一致。
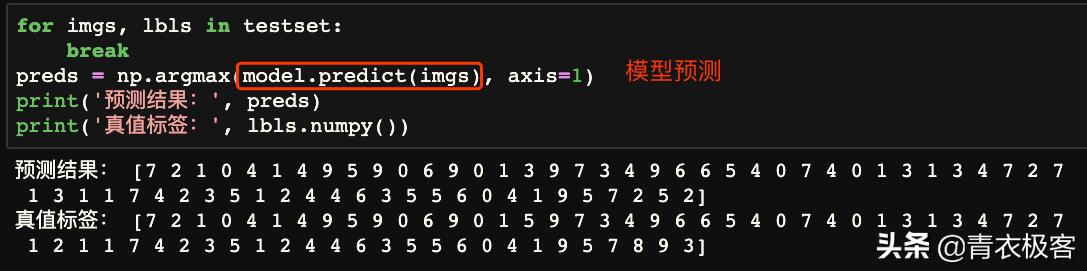
使用模型进行预测
到此,在tensorflow2.0中加载numpy数据用于模型训练就讨论完毕。使用的过程和操作方式都很简单,在日常的工作和科研过程中,使用这种方式确实可以较大地提高工作效率。不过需要指出的是,这种方式会将数据一次载入内存,如果数据量比较大,内存压力过大可能会出现程序崩溃。因此,这种方式适合数据量不太大的项目,如果内存不足以容纳这么多的数据,就需要考虑别的方法了。本文的notebook文件在github上的cnbluegeek/notebook仓库中共享,欢迎感兴趣的朋友前往下载。


















 2708
2708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









