



 本文介绍了短文本匹配技术,包括无监督、有监督及两者结合的方法。无监督方式利用词向量快速计算相似度;有监督方式通过标注数据训练模型,如孪生网络、匹配聚合网络及预训练语言模型等;结合方式利用已存储的标准句向量加速新文本匹配过程。
本文介绍了短文本匹配技术,包括无监督、有监督及两者结合的方法。无监督方式利用词向量快速计算相似度;有监督方式通过标注数据训练模型,如孪生网络、匹配聚合网络及预训练语言模型等;结合方式利用已存储的标准句向量加速新文本匹配过程。
因为最近在做短文本匹配的项目,所以,简单的记个笔记。
短文本匹配,即计算两个短文本的相似度。从广义分,可以分为无监督方式,有监督方式,有监督和无监督结合方式。具体实现,可以使用两个算法库,分别是MatchZoo和text_matching,在github上以上两个算法都开源了。
1.无监督方式。
通过模型训练语料得到词向量,如word2vec,glove等模型。然后通过对文本进行分词,通过look up Embedding table得到每个词向量,将词向量相加得到句向量。对两个短文本的句向量计算相似度。常见的相似度算法有余弦相似度,欧式距离,曼哈顿距离,切比雪夫距离等。无监督方式计算速度较快,其相似度结果依赖于得到的词向量质量。
2.有监督相似度
有标注语料的情况下训练。标注的语料为句子对形式,<text1, text2,label>,label分为0和1两种。通过对标注的训练集学习,直接端到端学习,计算出短文本的相似度。目前有以下这种架构:1)孪生网络。2)匹配聚合网络。3)预训练语言模型
1)孪生网络(Siamese Network)
孪生网络使用相同的深度学习编码器,将两个短文本分别编码到相同的空间,然后将得到的两个句向量进行距离计算,最后获取两个短文本的相似度。优点就是共享参数,更加容易训练,缺点就是映射过程中两个短文本没有明确的交互,这种缺乏交互的结构没有充分利用到两个短文本相互影响的信息。孪生网络的结构如下:
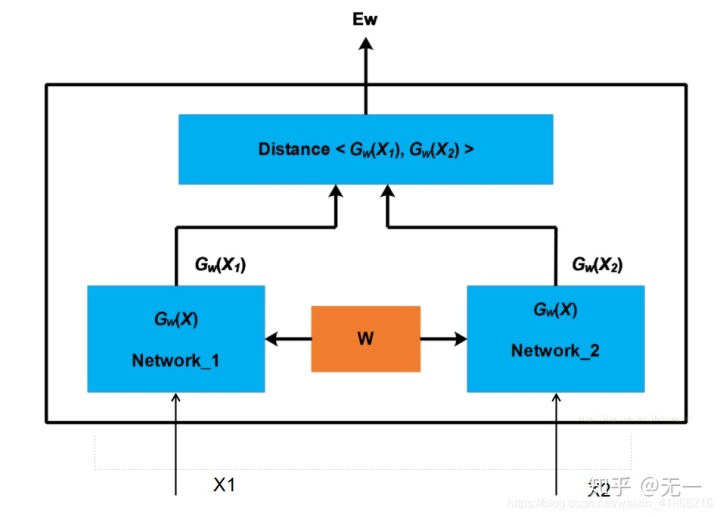
Siamese-CNN:特征提取使用cnn。
Siamese-RNN:特征提取使用rnn。
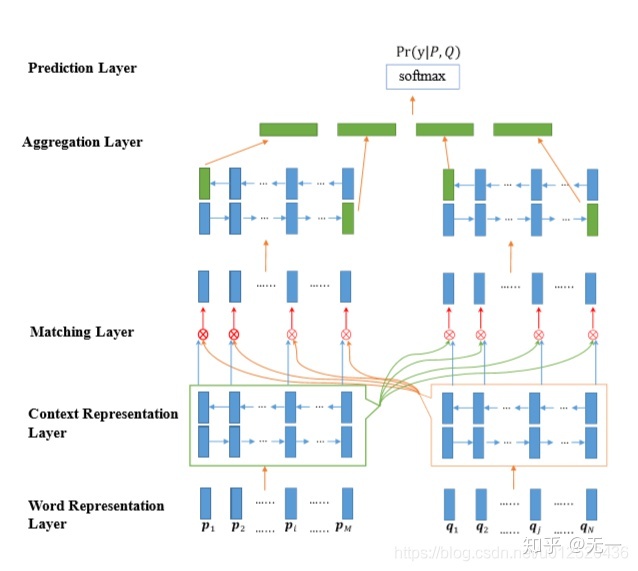
2)匹配聚合网络(Matching-Aggregation Network)
前半部分与孪生网络相同,即是将两个短文本输入到相同的深度学习编码器,然后不是直接将得到的两个句向量进行距离计算,二十通过一种或多种注意力机制,将两个句子向量进行信息的交互,最终将其聚合成一个向量,并且通过全连接层获取短文本的相似度。代表的模型有ESIM,BIMPM,DIIN,Cafe等。以BIMPM的架构举例:
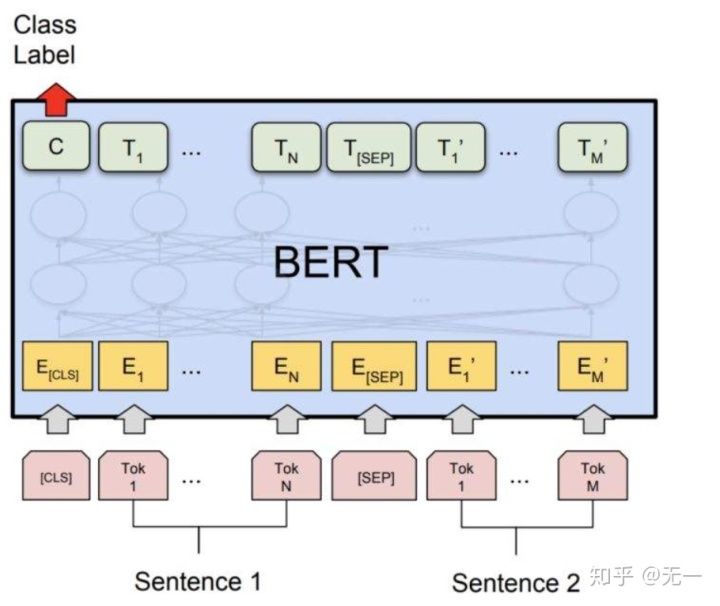
3)预训练语言模型(Pre-trained Language Model)
该模型主要使用训练语言模型。第一阶段,使用通用的预料库训练语言模型,然后第二阶段预训练的语言模型做相似度任务,得到信息交互后的向量,然后连接全连接层,输出概率。说白了,比如bert,就是输入两个短文本,然后CLS向量连接全连接层,计算相似度。这种模型参数多,并且使用了通用的语料库,能够获取到短文本之间隐藏的交互信息,效果较好。
3.有监督+无监督
无监督:直接相加得到句向量,不能很好的表达语义信息,并且词的位置信息没有得到体现,也不包含上下文的语义信息。
有监督学习:时间复杂度太高。可以将标准库中的句向量计算完成并存储。新的文本来临时,只需要解决用户问题的就响了,然后与存储在库中的标准问句进行距离度量。
可以使用bert代替孪生网络的CNN或LSTM结构,获取更多语义信息的句向量,还可以通过蒸馏降低BERT模型的参数,节约时间成本。
以下列出常用的短文本匹配模型:
DSSM
ConvNet
ESIM
ABCNN
BIMPM
DIIN
DRCN

















 4477
4477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









